一月一日等待变化等待机会
Learning Linux Binary Analysis是一部无上至宝,我决定使用我的信用卡点数买正版,一方面向大师”elfmaster”, Ryan O'Neill
Int foo()
{
}
_start()
{
foo();
bar();
__asm__("leave");
}
nick@ubuntu-14:~/Documents/staroceans/practice$ objdump -S nomain.o
nomain.o: file format elf32-i386
Disassembly of section .text:
00000000 <foo>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 5d pop %ebp
4: c3 ret
00000005 <_start>:
5: 55 push %ebp
6: 89 e5 mov %esp,%ebp
8: 53 push %ebx
9: 83 ec 04 sub $0x4,%esp
c: e8 fc ff ff ff call d
<foo+0xd>
11: 81 c3 02 00 00 00 add $0x2,%ebx
17: e8 fc ff ff ff call 18
<foo+0x18>
1c: c9 leave
1d: 83 c4 04 add $0x4,%esp
20: 5b pop %ebx
21: 5d pop %ebp
22: c3 ret
Disassembly of section
.text.__x86.get_pc_thunk.bx:
00000023 <__x86.get_pc_thunk.bx>:
23: 8b 1c 24 mov (%esp),%ebx
26: c3 ret
一月二日 等待变化等待机会
回到了圣何塞,头脑还不是很清楚,我开始困惑为什么我在/etc/cron.xxx/下看不到我的设定的任务,后来才明白你不是直接编辑这些文件的,你使用crontab这个命令来修改添加任务。比如,我使用strace crontab -l发现他是在/var/spool/cron/crontabs/xxx一月四日 等待变化等待机会
U-boot的代码还看不懂,这位大侠的学习笔记我现在看还有些困难,我买的葵花宝典《Learning Linux Binary Analysis》,怀着对于作者Ryan “elfmaster” O'Neill 的无限尊敬我购买了原版书达到了,准备认认真真一步一步看,这个现在比较适合我的程度,很多不一定是完全的陌生,但是一定是有很大的提高。这里是大师的网站,还没有拜读。 一月五日 等待变化等待机会 下载了大师的作品:text-infector。究竟怎么使用呢?代码尽管不多可是怎么平移添加蠕虫还是要花时间才能看得懂。这里是大师的论文,还没有看就发现大师还有自己的大师,这篇祖师的论文更加的难懂。下载一个版本吧。一月六日 等待变化等待机会
对于PIC我的头脑并没有很清楚的概念,至少怎么实现的是一窍不通,甚至现在才意识到它和loader relocation是两种不同的方式,这篇文章值得学习,我还没有看它的前传,直接读PIC似乎有些断层?这一段要如何理解呢?:There's no instruction to obtain the value of the instruction pointer on x86, but we can use a simple trick to get it. Here's some assembly pseudo-code that demonstrates it:
call TMPLABEL
TMPLABEL:
pop ebx一月七日 等待变化等待机会
昨晚看不明白早上继续看,下载如下。关于作者验证全局变量在got中地址一段很精彩,需要特别仔细阅读:
; add xx + yy + zz and store it in sum
;
mov eax, DWORD PTR [ebp-8]
mov edx, DWORD PTR [ebp-4]
lea eax, [edx+eax]
add eax, DWORD PTR [ebp-12]
mov DWORD PTR [ebp-16],eax
一月八日 等待变化等待机会
如果我在x86_64ubuntu下编译32位程序,比如gcc -m32,然后查看readelf -h我看到的entry point是0x8048440,这个和64位程序很不同。一月十日 等待变化等待机会
安装wireshark默认不能enable网卡的访问,需要配置: sudo dpkg-reconfigure wireshark-common 当然还要把用户添加到wireshark的组里:一月十一日 等待变化等待机会
经过了太多的忍耐,我的耐心到了极点,决定使用笔记本来编写html日记,反正我也没有什么花哨的背景和字体,只是记录原始的思想而已。一月十二日 等待变化等待机会
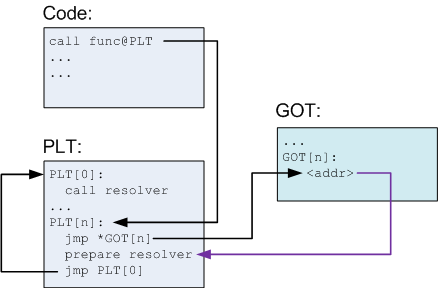
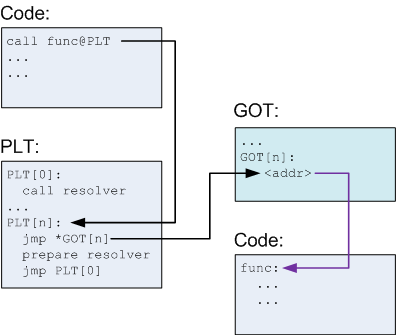
学习PIC是一件很难的事情如果不结合代码可能更难?请看这幅画里面有多少文字来解释:Explanation:这个还没有完仅仅是开始,大师接着解释在resolve之后发生了什么?
- In the code, a function func is called. The compiler translates it to a call to func@plt, which is some N-th entry in the PLT.
- The PLT consists of a special first entry, followed by a bunch of identically structured entries, one for each function needing resolution.
- Each PLT entry but the first consists of these parts:
- A jump to a location which is specified in a corresponding GOT entry
- Preparation of arguments for a "resolver" routine
- Call to the resolver routine, which resides in the first entry of the PLT
- The first PLT entry is a call to a resolver routine, which is located in the dynamic loader itself [6]. This routine resolves the actual address of the function. More on its action a bit later.
- Before the function's actual address has been resolved, the Nth GOT entry just points to after the jump. This is why this arrow in the diagram is colored differently - it's not an actual jump, just a pointer.
After the first call, the diagram looks a bit differently:
- PLT[n] is called and jumps to the address pointed to in GOT[n].
- This address points into PLT[n] itself, to the preparation of arguments for the resolver.
- The resolver is then called.
- The resolver performs resolution of the actual address of func, places its actual address into GOT[n] and calls func.
一月十三日 等待变化等待机会
看汇编有多难呢?总之一个人的记忆力丧失了至少还能写一些C/C++的代码前提是利用一些好的开发工具,但是汇编码靠的很多是记忆力,脑子记不过来,当然熟能生巧是不变的,我几乎没有怎么写过,除了刚上大学的第一门课的第一篇作业和第一个project,那时候很自豪以为汇编写了几千行就是很牛逼的事情。其实机器产生的汇编码更多你怎么不和机器比?
00000556 <ml_func>:
556: 55 push ebp
557: 89 e5 mov ebp,esp
559: 53 push ebx
55a: 83 ec 24 sub esp,0x24
55d: e8 be fe ff ff call 420 <__x86.get_pc_thunk.bx>
562: 81 c3 9e 1a 00 00 add ebx,0x1a9e
568: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
56b: 89 04 24 mov DWORD PTR [esp],eax
56e: e8 9d fe ff ff call 410 <ml_util_func@plt>
00000477 <ml_func>: 477: 55 push ebp 478: 89 e5 mov ebp,esp 47a: 53 push ebx 47b: 83 ec 24 sub esp,0x24 47e: e8 e4 ff ff ff call 467 <__i686.get_pc_thunk.bx> 483: 81 c3 71 1b 00 00 add ebx,0x1b71 489: 8b 45 08 mov eax,DWORD PTR [ebp+0x8] 48c: 89 04 24 mov DWORD PTR [esp],eax 48f: e8 0c ff ff ff call 3a0 <ml_util_func@plt>
nick@ubuntu-14:/tmp$ readelf -x .got.plt libsample.so
Hex dump of section '.got.plt':
0x00002000 081f0000 00000000 00000000 f6030000 ................
0x00002010 06040000 16040000 ........
00000410 <ml_util_func@plt>:
410: ff a3 14 00 00 00 jmp DWORD PTR [ebx+0x14]
416: 68 10 00 00 00 push 0x10
41b: e9 c0 ff ff ff jmp 3e0 <_init+0x28>
Contents of section .rel.plt:
03a0 0c200000 07020000 10200000 07030000 . ....... ......
03b0 14200000 07090000 . ......
Relocation section '.rel.plt' at offset 0x3a0 contains 3 entries:
Offset Info Type Sym.Value Sym. Name
0000200c 00000207 R_386_JUMP_SLOT 00000000 __cxa_finalize
00002010 00000307 R_386_JUMP_SLOT 00000000 __gmon_start__
00002014 00000907 R_386_JUMP_SLOT 0000054b ml_util_func
0000054b <ml_util_func>:
54b: 55 push ebp
54c: 89 e5 mov ebp,esp
54e: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
551: 83 c0 01 add eax,0x1
554: 5d pop ebp
555: c3 ret一月十五日 等待变化等待机会
大师说看PIC之前应该先读懂loadtime relocation,所以,应该先读这一篇,实际上这个应该更容易。
int myglob = 42;
int ml_func(int a, int b)
{
myglob += a;
return b + myglob;
}
0000051b <ml_func>:
int myglob = 42;
int ml_func(int a, int b)
{
51b: 55 push ebp
51c: 89 e5 mov ebp,esp
myglob += a;
51e: 8b 15 00 00 00 00 mov edx,DWORD PTR ds:0x0
524: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
527: 01 d0 add eax,edx
529: a3 00 00 00 00 mov ds:0x0,eax
return b + myglob;
52e: 8b 15 00 00 00 00 mov edx,DWORD PTR ds:0x0
534: 8b 45 0c mov eax,DWORD PTR [ebp+0xc]
537: 01 d0 add eax,edx
}
539: 5d pop ebp
53a: c3 ret
Relocation section '.rel.dyn' at offset 0x334 contains 11 entries:
Offset Info Type Sym.Value Sym. Name
00001ef8 00000008 R_386_RELATIVE
00001efc 00000008 R_386_RELATIVE
00002014 00000008 R_386_RELATIVE
00000520 00000601 R_386_32 00002018 myglob
0000052a 00000601 R_386_32 00002018 myglob
00000530 00000601 R_386_32 00002018 myglob
Symbol table '.dynsym' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterTMCloneTab
2: 00000000 0 FUNC WEAK DEFAULT UND __cxa_finalize@GLIBC_2.1.3 (2)
3: 00000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
4: 00000000 0 NOTYPE WEAK DEFAULT UND _Jv_RegisterClasses
5: 00000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMCloneTable
6: 00002018 4 OBJECT GLOBAL DEFAULT 21 myglob
一月十六日 等待变化等待机会
loadtime relocation对于函数的算法非常的难懂,对比全局变量复杂度增加了一个数量级,我看了一晚上也没有看懂,看来只有实际动手一步一步推演才行。当然大师也说他的解说加快了步骤是假定读者已经明白了要义,我感到比较惭愧,似乎很不得法悟性很糟。现在跳过详细的解说,如果你直接去读大师所谓的bonus的部分给你的一些真知灼见的分析为何算法如此复杂的原因,我才有些恍然,因为不要以为凡是global就一定是在我们当前代码段的相对固定的偏移,如果是这样的话,global就沦为了static,这个正是大师的实验所证实的。因为也许这个global本身就在另一个动态库里单靠相对偏移不可能解决的。
int myglob = 42;
int ml_util_func(int a)
{
return a + 1;
}
int ml_func(int a, int b)
{
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}
0000054b <ml_util_func>:
54b: 55 push %ebp
54c: 89 e5 mov %esp,%ebp
54e: 8b 45 08 mov 0x8(%ebp),%eax
551: 83 c0 01 add $0x1,%eax
554: 5d pop %ebp
555: c3 ret
00000556 <ml_func>:
556: 55 push %ebp
557: 89 e5 mov %esp,%ebp
559: 83 ec 14 sub $0x14,%esp
55c: 8b 45 08 mov 0x8(%ebp),%eax
55f: 89 04 24 mov %eax,(%esp)
562: e8 fc ff ff ff call 563 <ml_func+0xd>
567: 8b 55 0c mov 0xc(%ebp),%edx
56a: 01 d0 add %edx,%eax
56c: 89 45 fc mov %eax,-0x4(%ebp)
56f: 8b 15 00 00 00 00 mov 0x0,%edx
575: 8b 45 fc mov -0x4(%ebp),%eax
578: 01 d0 add %edx,%eax
57a: a3 00 00 00 00 mov %eax,0x0
57f: 8b 15 00 00 00 00 mov 0x0,%edx
585: 8b 45 0c mov 0xc(%ebp),%eax
588: 01 d0 add %edx,%eax
58a: c9 leave
58b: c3 ret
Relocation section '.rel.dyn' at offset 0x358 contains 12 entries:
Offset Info Type Sym.Value Sym. Name
00001ef8 00000008 R_386_RELATIVE
00001efc 00000008 R_386_RELATIVE
00002014 00000008 R_386_RELATIVE
00000563 00000902 R_386_PC32 0000054b ml_util_func
00000571 00000601 R_386_32 00002018 myglob
0000057b 00000601 R_386_32 00002018 myglob
00000581 00000601 R_386_32 00002018 myglob
0000054b <ml_util_func>:
54b: 55 push %ebp
54c: 89 e5 mov %esp,%ebp
54e: 8b 45 08 mov 0x8(%ebp),%eax
551: 83 c0 01 add $0x1,%eax
554: 5d pop %ebp
555: c3 ret
It means the following: take the value at the offset specified in the entry, add the address of the symbol to it, subtract the address of the offset itself, and place it back into the word at the offset. Recall that this relocation is done at load-time, when the final load addresses of the symbol and the relocated offset itself are already known. These final addresses participate in the computation.我再次阅读以上文字才意识到我头脑中始终认为像全局变量一样偏移量0x563是0,因此我总是情不自禁的使用rel.dyn的sym.value来替代0,实际上这个做法在偏移处为0的时候是等价的,但是真正的算法是:0xfffffffc+address[ml_util_func]-address[offset 0x563]这个我是将信将疑的,需要实际运行来检验,大师有gdb演示,我没有时间要赶去上班,下班在实际照做
extern int ml_func(int a, int b);
int main(int argc, char**argv)
{
return ml_func(argc, argc);
}
(gdb) set disassembly-flavor intel
(gdb) b ml_func
Breakpoint 1 at 0x8048410
(gdb) r
Starting program: /tmp/driver
Breakpoint 1, ml_func (a=1, b=1) at func.c:10
10 int c = b + ml_util_func(a);
(gdb) info files
Symbols from "/tmp/driver".
Unix child process:
Using the running image of child process 5193.
While running this, GDB does not access memory from...
Local exec file:
`/tmp/driver', file type elf32-i386.
Entry point: 0x8048440
0x08048154 - 0x08048167 is .interp
0x08048168 - 0x08048188 is .note.ABI-tag
0x08048188 - 0x080481ac is .note.gnu.build-id
0x080481ac - 0x080481e8 is .gnu.hash
0x080481e8 - 0x080482b8 is .dynsym
0x080482b8 - 0x0804837e is .dynstr
0x0804837e - 0x08048398 is .gnu.version
0x08048398 - 0x080483b8 is .gnu.version_r
0x080483b8 - 0x080483c0 is .rel.dyn
0x080483c0 - 0x080483d8 is .rel.plt
0x080483d8 - 0x080483fb is .init
0x08048400 - 0x08048440 is .plt
0x08048440 - 0x080485d2 is .text
0x080485d4 - 0x080485e8 is .fini
0x080485e8 - 0x080485f0 is .rodata
0x080485f0 - 0x0804861c is .eh_frame_hdr
0x0804861c - 0x080486cc is .eh_frame
0x08049f00 - 0x08049f04 is .init_array
0x08049f04 - 0x08049f08 is .fini_array
0x08049f08 - 0x08049f0c is .jcr
0x08049f0c - 0x08049ffc is .dynamic
0x08049ffc - 0x0804a000 is .got
0x0804a000 - 0x0804a018 is .got.plt
0x0804a018 - 0x0804a020 is .data
0x0804a020 - 0x0804a024 is .bss
(gdb) disas ml_util_func
Dump of assembler code for function ml_util_func:
0xf7fd354b <+0>: push ebp
0xf7fd354c <+1>: mov ebp,esp
0xf7fd354e <+3>: mov eax,DWORD PTR [ebp+0x8]
0xf7fd3551 <+6>: add eax,0x1
0xf7fd3554 <+9>: pop ebp
0xf7fd3555 <+10>: ret
End of assembler dump.
(gdb) disas /r ml_func
Dump of assembler code for function ml_func:
0xf7fd3556 <+0>: 55 push ebp
0xf7fd3557 <+1>: 89 e5 mov ebp,esp
0xf7fd3559 <+3>: 83 ec 14 sub esp,0x14
=> 0xf7fd355c <+6>: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
0xf7fd355f <+9>: 89 04 24 mov DWORD PTR [esp],eax
0xf7fd3562 <+12>: e8 e4 ff ff ff call 0xf7fd354b <ml_util_func>
0xf7fd3567 <+17>: 8b 55 0c mov edx,DWORD PTR [ebp+0xc]
0xf7fd356a <+20>: 01 d0 add eax,edx
0xf7fd356c <+22>: 89 45 fc mov DWORD PTR [ebp-0x4],eax
0xf7fd356f <+25>: 8b 15 18 50 fd f7 mov edx,DWORD PTR ds:0xf7fd5018
0xf7fd3575 <+31>: 8b 45 fc mov eax,DWORD PTR [ebp-0x4]
0xf7fd3578 <+34>: 01 d0 add eax,edx
0xf7fd357a <+36>: a3 18 50 fd f7 mov ds:0xf7fd5018,eax
0xf7fd357f <+41>: 8b 15 18 50 fd f7 mov edx,DWORD PTR ds:0xf7fd5018
0xf7fd3585 <+47>: 8b 45 0c mov eax,DWORD PTR [ebp+0xc]
0xf7fd3588 <+50>: 01 d0 add eax,edx
0xf7fd358a <+52>: c9 leave
0xf7fd358b <+53>: c3 ret
End of assembler dump.一月十七日 等待变化等待机会
我一开始始终不明白大师的输出有所有的程序的header的地址和名字,我还一直以为是大师的gdb的版本不同的特性。今天看了大师的driver才恍然大悟,其实我早就注意到了dl_iterate_phdr,可是后来就忘记了。原来是一个很有用的小trick,就是说我一直期待寻找的方法,我之前曾经费尽心机的要去debug linker/loader的运行期加载的模块,只能使用LD_DEBUG的环境变量输出到文件,虽然也不错可是毕竟有时候不太好控制,那么这个回调函数注册的办法提供了可编程的方法。
#define _GNU_SOURCE
#include <link.h>
#include <stdlib.h>
#include <stdio.h>
char* typeName[]=
{
"unused", /* Program header table entry unused */
"Loadable program segment", /* Loadable program segment */
"Dynamic linking information", /* Dynamic linking information */
"Program interpreter", /* Program interpreter */
"Auxiliary information", /* Auxiliary information */
"Reserved", /* Reserved */
"Entry for header table itself", /* Entry for header table itself */
"Thread-local storage segment", /* Thread-local storage segment */
"Number of defined types", /* Number of defined types */
"Start of OS-specific", /* Start of OS-specific */
"GCC .eh_frame_hdr segment", /* GCC .eh_frame_hdr segment */
"Indicates stack executability", /* Indicates stack executability */
"Read-only after relocation", /* Read-only after relocation */
"unknown"
};
int type2Number(int in)
{
if (in < 8)
{
return in;
}
switch (in)
{
case 0x60000000:
return 9;
case 0x6474e550:
return 10;
case 0x6474e551:
return 11;
case 0x6474e552:
return 12;
}
return 13;
}
char*flagName[] =
{
"executable", /* Segment is executable */
"writable", /* Segment is writable */
"readable", /* Segment is readable */
"OS-specific", /* OS-specific */
"Processor-specific", /* Processor-specific */
"PF_PARISC_SBP(PF_HP_SBP)",
"PF_HP_PAGE_SIZE",
"PF_HP_FAR_SHARED",
"PF_HP_NEAR_SHARED",
"PF_HP_CODE",
"PF_HP_MODIFY",
"PF_HP_LAZYSWAP",
"executable|writable",
"executable|readable",
"readable|writable",
"readable|writable|executable",
"unknown"
};
int flag2Number(int in)
{
switch (in)
{
case PF_X:
return 0;
case PF_W:
return 1;
case PF_R:
return 2;
case 0x0ff00000:
return 3;
case 0xf0000000:
return 4;
case 0x08000000:
return 5;
case 0x00100000:
return 6;
case 0x00200000:
return 7;
case 0x00400000:
return 8;
case 0x01000000:
return 9;
case 0x02000000:
return 10;
case 0x04000000:
return 11;
case (PF_X|PF_W):
return 12;
case (PF_X|PF_R):
return 13;
case (PF_W|PF_R):
return 14;
case (PF_X|PF_W|PF_R):
return 15;
}
return 12;
}
static int header_handler(struct dl_phdr_info* info, size_t size, void* data)
{
printf("name=%s (%d segments) address=%p\n",
info->dlpi_name, info->dlpi_phnum, (void*)info->dlpi_addr);
for (int j = 0; j < info->dlpi_phnum; j++) {
printf("\t\t header %2d: address=%10p\n", j,
(void*) (info->dlpi_addr + info->dlpi_phdr[j].p_vaddr));
int typeNumber=type2Number(info->dlpi_phdr[j].p_type);
int flagNumber=flag2Number(info->dlpi_phdr[j].p_flags);
printf("\t\t\t type=%s, flags=%s\n",
typeName[typeNumber], flagName[flagNumber]);
}
printf("\n");
return 0;
}
extern int ml_func(int, int);
int main(int argc, const char* argv[])
{
dl_iterate_phdr(header_handler, NULL);
int t = ml_func(argc, argc);
return t;
}
name= (9 segments) address=(nil)
header 0: address= 0x8048034
type=Entry for header table itself, flags=executable|readable
header 1: address= 0x8048154
type=Program interpreter, flags=readable
header 2: address= 0x8048000
type=Loadable program segment, flags=executable|readable
header 3: address= 0x8049f00
type=Loadable program segment, flags=readable|writable
header 4: address= 0x8049f0c
type=Dynamic linking information, flags=readable|writable
header 5: address= 0x8048168
type=Auxiliary information, flags=readable
header 6: address= 0x8048bd0
type=GCC .eh_frame_hdr segment, flags=readable
header 7: address= (nil)
type=Indicates stack executability, flags=readable|writable
header 8: address= 0x8049f00
type=Read-only after relocation, flags=readable
name= (4 segments) address=0xf776e000
header 0: address=0xf776e000
type=Loadable program segment, flags=executable|readable
header 1: address=0xf776e2bc
type=Dynamic linking information, flags=readable
header 2: address=0xf776e558
type=Auxiliary information, flags=readable
header 3: address=0xf776e5b8
type=GCC .eh_frame_hdr segment, flags=readable
name=/tmp/libfunc.so (7 segments) address=0xf7767000
header 0: address=0xf7767000
type=Loadable program segment, flags=executable|readable
header 1: address=0xf7768ef8
type=Loadable program segment, flags=readable|writable
header 2: address=0xf7768f04
type=Dynamic linking information, flags=readable|writable
header 3: address=0xf7767114
type=Auxiliary information, flags=readable
header 4: address=0xf77675a0
type=GCC .eh_frame_hdr segment, flags=readable
header 5: address=0xf7767000
type=Indicates stack executability, flags=readable|writable
header 6: address=0xf7768ef8
type=Read-only after relocation, flags=readable
name=/lib32/libc.so.6 (10 segments) address=0xf759a000
header 0: address=0xf759a034
type=Entry for header table itself, flags=executable|readable
header 1: address=0xf7704cb4
type=Program interpreter, flags=readable
header 2: address=0xf759a000
type=Loadable program segment, flags=executable|readable
header 3: address=0xf77421dc
type=Loadable program segment, flags=readable|writable
header 4: address=0xf7743da8
type=Dynamic linking information, flags=readable|writable
header 5: address=0xf759a174
type=Auxiliary information, flags=readable
header 6: address=0xf77421dc
type=Thread-local storage segment, flags=readable
header 7: address=0xf7704cc8
type=GCC .eh_frame_hdr segment, flags=readable
header 8: address=0xf759a000
type=Indicates stack executability, flags=readable|writable
header 9: address=0xf77421dc
type=Read-only after relocation, flags=readable
name=/lib/ld-linux.so.2 (7 segments) address=0xf7770000
header 0: address=0xf7770000
type=Loadable program segment, flags=executable|readable
header 1: address=0xf7790cc0
type=Loadable program segment, flags=readable|writable
header 2: address=0xf7790f30
type=Dynamic linking information, flags=readable|writable
header 3: address=0xf7770114
type=Auxiliary information, flags=readable
header 4: address=0xf778c8c0
type=GCC .eh_frame_hdr segment, flags=readable
header 5: address=0xf7770000
type=Indicates stack executability, flags=readable|writable
header 6: address=0xf7790cc0
type=Read-only after relocation, flags=readable
一月十九日 等待变化等待机会
int myglob = 42;
int ml_util_func(int a)
{
return a + 1;
}
int ml_func(int a, int b)
{
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}
00000556 <ml_func>:
556: 55 push ebp
557: 89 e5 mov ebp,esp
559: 83 ec 14 sub esp,0x14
55c: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
55f: 89 04 24 mov DWORD PTR [esp],eax
562: e8 fc ff ff ff call 563 <ml_func+0xd>
567: 8b 55 0c mov edx,DWORD PTR [ebp+0xc]
56a: 01 d0 add eax,edx
56c: 89 45 fc mov DWORD PTR [ebp-0x4],eax
56f: 8b 15 00 00 00 00 mov edx,DWORD PTR ds:0x0
575: 8b 45 fc mov eax,DWORD PTR [ebp-0x4]
578: 01 d0 add eax,edx
57a: a3 00 00 00 00 mov ds:0x0,eax
57f: 8b 15 00 00 00 00 mov edx,DWORD PTR ds:0x0
585: 8b 45 0c mov eax,DWORD PTR [ebp+0xc]
588: 01 d0 add eax,edx
58a: c9 leave
58b: c3 ret
00000556 <ml_func>:
556: 55 push ebp
557: 89 e5 mov ebp,esp
559: 53 push ebx
55a: 83 ec 24 sub esp,0x24
55d: e8 be fe ff ff call 420 <__x86.get_pc_thunk.bx>
562: 81 c3 9e 1a 00 00 add ebx,0x1a9e
568: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
56b: 89 04 24 mov DWORD PTR [esp],eax
56e: e8 9d fe ff ff call 410 <ml_util_func@plt>
573: 8b 55 0c mov edx,DWORD PTR [ebp+0xc]
576: 01 d0 add eax,edx
578: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
57b: 8b 83 ec ff ff ff mov eax,DWORD PTR [ebx-0x14]
581: 8b 10 mov edx,DWORD PTR [eax]
583: 8b 45 f4 mov eax,DWORD PTR [ebp-0xc]
586: 01 c2 add edx,eax
588: 8b 83 ec ff ff ff mov eax,DWORD PTR [ebx-0x14]
58e: 89 10 mov DWORD PTR [eax],edx
590: 8b 83 ec ff ff ff mov eax,DWORD PTR [ebx-0x14]
596: 8b 10 mov edx,DWORD PTR [eax]
598: 8b 45 0c mov eax,DWORD PTR [ebp+0xc]
59b: 01 d0 add eax,edx
59d: 83 c4 24 add esp,0x24
5a0: 5b pop ebx
5a1: 5d pop ebp
5a2: c3 ret
一月二十二日 等待变化等待机会
大师的文章深入浅出,尤其可贵的是绝不像很多略知一二的人的流于浮光掠影式的只空谈理论,而是拿出实实在在的干货,正应了大师自己说的那样:plz show me the codes!这个和老祖师Linus的RTFC!有异曲同工之妙。这一篇是关于debugger的,保存一个版本。一月二十四日 等待变化等待机会
我的两台打印机设置起来着实麻烦。hp的设置可以使用wps的button,我使用hp-wificonfig之类的工具似乎不行。不过我不是很确认因为我只是把它当作扫描仪使用,因此能够设定wifi就好了,有个办法可以查看所有的device: ping -b 192.168.1.255然后arp -n可以看看有什么设备。一月二十五日 等待变化等待机会
hld是一个什么东东?这是它的白皮书。关于bitcoin的概念很深奥的。一月二十六日 等待变化等待机会
下载Satoshi nakamoto的原论文也许更好懂一些,因为不懂原理就贸然读实现后的细节是一个费时费力的错误。一月二十七日 等待变化等待机会
浑浑噩噩读的似懂非懂,其实我原来明白的还是那些基本原理,没有看到实际的bitcoin的存储记录一切的一切都是不明其所以然。这个是论文引用的源头,我下载一个版本。这篇短文一望而知是某个大学教授之类的空想家的乌托邦式的臆想,因为他批判的政府滥用发钞权实际上被移交给了某些服务器控制者,在他的眼里似乎系统管理员都是宅心高尚不食人间烟火的圣人。所以,从这个层面上说Satoshi的设计是理性的因为不能相信任何机构或者个人,而是制度,一个分散的共享信息的系统,防止作弊的方法也不是靠良心,而是简单的计算能力的投入与产出。而且bmoney的作者在货币初始发行量的决定上也含混不清。这一点上Satoshi的方法更加的简单容易计量,因为所谓的计算能力的招标是一个空泛的想法,而挖矿的概念似乎更加的实际,直接解决了公共记录维护的成本摊销问题。一月二十八日 等待变化等待机会
关于给文件加时间戳的数字签名我只能从原理上理解,就是有这么几个要素:He who comes after me has surpassed me because he was before me.
一月二十九日 等待变化等待机会
关于证书你打算了解多少呢?从原理上说几乎每个人都明白一个大概,那就是证书实际上是一个Public key的容器其中自然也包含了它是如何进行验证的信息?在wiki的解说中是这样子的:
openssl x509 -in wikipedia.crt -C -noout
/* subject:/C=US/ST=California/L=San Francisco/O=Wikimedia Foundation, Inc./CN=*.wikipedia.org */
/* issuer :/C=BE/O=GlobalSign nv-sa/CN=GlobalSign Organization Validation CA - SHA256 - G2 */
unsigned char XXX_subject_name[123]={
0x30,0x79,0x31,0x0B,0x30,0x09,0x06,0x03,0x55,0x04,0x06,0x13,0x02,0x55,0x53,0x31,
0x13,0x30,0x11,0x06,0x03,0x55,0x04,0x08,0x13,0x0A,0x43,0x61,0x6C,0x69,0x66,0x6F,
0x72,0x6E,0x69,0x61,0x31,0x16,0x30,0x14,0x06,0x03,0x55,0x04,0x07,0x13,0x0D,0x53,
0x61,0x6E,0x20,0x46,0x72,0x61,0x6E,0x63,0x69,0x73,0x63,0x6F,0x31,0x23,0x30,0x21,
0x06,0x03,0x55,0x04,0x0A,0x13,0x1A,0x57,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,
0x20,0x46,0x6F,0x75,0x6E,0x64,0x61,0x74,0x69,0x6F,0x6E,0x2C,0x20,0x49,0x6E,0x63,
0x2E,0x31,0x18,0x30,0x16,0x06,0x03,0x55,0x04,0x03,0x0C,0x0F,0x2A,0x2E,0x77,0x69,
0x6B,0x69,0x70,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,
};
unsigned char XXX_public_key[91]={
0x30,0x59,0x30,0x13,0x06,0x07,0x2A,0x86,0x48,0xCE,0x3D,0x02,0x01,0x06,0x08,0x2A,
0x86,0x48,0xCE,0x3D,0x03,0x01,0x07,0x03,0x42,0x00,0x04,0xEF,0x53,0x4D,0xF8,0x6F,
0xB7,0x72,0xB2,0x45,0xA2,0x0D,0x29,0x84,0x1C,0xAE,0xDE,0x04,0xEE,0x16,0x88,0x8B,
0xC1,0x3D,0xE8,0xB6,0x23,0xA9,0x75,0x72,0x71,0xA4,0xD1,0x1F,0x46,0x03,0x33,0x22,
0xF5,0x72,0x56,0x3F,0xDF,0x1F,0x2B,0x93,0xD2,0x41,0xB7,0x39,0xF9,0x74,0x4F,0x20,
0x0A,0x1D,0xE9,0xC0,0x47,0x89,0x80,0x0B,0x5F,0x68,0x03,
};
unsigned char XXX_certificate[2393]={
0x30,0x82,0x09,0x55,0x30,0x82,0x08,0x3D,0xA0,0x03,0x02,0x01,0x02,0x02,0x0C,0x09,
0xDE,0x73,0x4B,0x91,0x75,0x4C,0x18,0x79,0xC0,0xAE,0x4E,0x30,0x0D,0x06,0x09,0x2A,
0x86,0x48,0x86,0xF7,0x0D,0x01,0x01,0x0B,0x05,0x00,0x30,0x66,0x31,0x0B,0x30,0x09,
0x06,0x03,0x55,0x04,0x06,0x13,0x02,0x42,0x45,0x31,0x19,0x30,0x17,0x06,0x03,0x55,
0x04,0x0A,0x13,0x10,0x47,0x6C,0x6F,0x62,0x61,0x6C,0x53,0x69,0x67,0x6E,0x20,0x6E,
0x76,0x2D,0x73,0x61,0x31,0x3C,0x30,0x3A,0x06,0x03,0x55,0x04,0x03,0x13,0x33,0x47,
0x6C,0x6F,0x62,0x61,0x6C,0x53,0x69,0x67,0x6E,0x20,0x4F,0x72,0x67,0x61,0x6E,0x69,
0x7A,0x61,0x74,0x69,0x6F,0x6E,0x20,0x56,0x61,0x6C,0x69,0x64,0x61,0x74,0x69,0x6F,
0x6E,0x20,0x43,0x41,0x20,0x2D,0x20,0x53,0x48,0x41,0x32,0x35,0x36,0x20,0x2D,0x20,
0x47,0x32,0x30,0x1E,0x17,0x0D,0x31,0x37,0x31,0x31,0x30,0x33,0x30,0x33,0x34,0x32,
0x30,0x32,0x5A,0x17,0x0D,0x31,0x38,0x31,0x31,0x32,0x32,0x30,0x37,0x35,0x39,0x35,
0x39,0x5A,0x30,0x79,0x31,0x0B,0x30,0x09,0x06,0x03,0x55,0x04,0x06,0x13,0x02,0x55,
0x53,0x31,0x13,0x30,0x11,0x06,0x03,0x55,0x04,0x08,0x13,0x0A,0x43,0x61,0x6C,0x69,
0x66,0x6F,0x72,0x6E,0x69,0x61,0x31,0x16,0x30,0x14,0x06,0x03,0x55,0x04,0x07,0x13,
0x0D,0x53,0x61,0x6E,0x20,0x46,0x72,0x61,0x6E,0x63,0x69,0x73,0x63,0x6F,0x31,0x23,
0x30,0x21,0x06,0x03,0x55,0x04,0x0A,0x13,0x1A,0x57,0x69,0x6B,0x69,0x6D,0x65,0x64,
0x69,0x61,0x20,0x46,0x6F,0x75,0x6E,0x64,0x61,0x74,0x69,0x6F,0x6E,0x2C,0x20,0x49,
0x6E,0x63,0x2E,0x31,0x18,0x30,0x16,0x06,0x03,0x55,0x04,0x03,0x0C,0x0F,0x2A,0x2E,
0x77,0x69,0x6B,0x69,0x70,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,0x30,0x59,0x30,
0x13,0x06,0x07,0x2A,0x86,0x48,0xCE,0x3D,0x02,0x01,0x06,0x08,0x2A,0x86,0x48,0xCE,
0x3D,0x03,0x01,0x07,0x03,0x42,0x00,0x04,0xEF,0x53,0x4D,0xF8,0x6F,0xB7,0x72,0xB2,
0x45,0xA2,0x0D,0x29,0x84,0x1C,0xAE,0xDE,0x04,0xEE,0x16,0x88,0x8B,0xC1,0x3D,0xE8,
0xB6,0x23,0xA9,0x75,0x72,0x71,0xA4,0xD1,0x1F,0x46,0x03,0x33,0x22,0xF5,0x72,0x56,
0x3F,0xDF,0x1F,0x2B,0x93,0xD2,0x41,0xB7,0x39,0xF9,0x74,0x4F,0x20,0x0A,0x1D,0xE9,
0xC0,0x47,0x89,0x80,0x0B,0x5F,0x68,0x03,0xA3,0x82,0x06,0xB9,0x30,0x82,0x06,0xB5,
0x30,0x0E,0x06,0x03,0x55,0x1D,0x0F,0x01,0x01,0xFF,0x04,0x04,0x03,0x02,0x03,0x88,
0x30,0x81,0xA0,0x06,0x08,0x2B,0x06,0x01,0x05,0x05,0x07,0x01,0x01,0x04,0x81,0x93,
0x30,0x81,0x90,0x30,0x4D,0x06,0x08,0x2B,0x06,0x01,0x05,0x05,0x07,0x30,0x02,0x86,
0x41,0x68,0x74,0x74,0x70,0x3A,0x2F,0x2F,0x73,0x65,0x63,0x75,0x72,0x65,0x2E,0x67,
0x6C,0x6F,0x62,0x61,0x6C,0x73,0x69,0x67,0x6E,0x2E,0x63,0x6F,0x6D,0x2F,0x63,0x61,
0x63,0x65,0x72,0x74,0x2F,0x67,0x73,0x6F,0x72,0x67,0x61,0x6E,0x69,0x7A,0x61,0x74,
0x69,0x6F,0x6E,0x76,0x61,0x6C,0x73,0x68,0x61,0x32,0x67,0x32,0x72,0x31,0x2E,0x63,
0x72,0x74,0x30,0x3F,0x06,0x08,0x2B,0x06,0x01,0x05,0x05,0x07,0x30,0x01,0x86,0x33,
0x68,0x74,0x74,0x70,0x3A,0x2F,0x2F,0x6F,0x63,0x73,0x70,0x32,0x2E,0x67,0x6C,0x6F,
0x62,0x61,0x6C,0x73,0x69,0x67,0x6E,0x2E,0x63,0x6F,0x6D,0x2F,0x67,0x73,0x6F,0x72,
0x67,0x61,0x6E,0x69,0x7A,0x61,0x74,0x69,0x6F,0x6E,0x76,0x61,0x6C,0x73,0x68,0x61,
0x32,0x67,0x32,0x30,0x56,0x06,0x03,0x55,0x1D,0x20,0x04,0x4F,0x30,0x4D,0x30,0x41,
0x06,0x09,0x2B,0x06,0x01,0x04,0x01,0xA0,0x32,0x01,0x14,0x30,0x34,0x30,0x32,0x06,
0x08,0x2B,0x06,0x01,0x05,0x05,0x07,0x02,0x01,0x16,0x26,0x68,0x74,0x74,0x70,0x73,
0x3A,0x2F,0x2F,0x77,0x77,0x77,0x2E,0x67,0x6C,0x6F,0x62,0x61,0x6C,0x73,0x69,0x67,
0x6E,0x2E,0x63,0x6F,0x6D,0x2F,0x72,0x65,0x70,0x6F,0x73,0x69,0x74,0x6F,0x72,0x79,
0x2F,0x30,0x08,0x06,0x06,0x67,0x81,0x0C,0x01,0x02,0x02,0x30,0x09,0x06,0x03,0x55,
0x1D,0x13,0x04,0x02,0x30,0x00,0x30,0x49,0x06,0x03,0x55,0x1D,0x1F,0x04,0x42,0x30,
0x40,0x30,0x3E,0xA0,0x3C,0xA0,0x3A,0x86,0x38,0x68,0x74,0x74,0x70,0x3A,0x2F,0x2F,
0x63,0x72,0x6C,0x2E,0x67,0x6C,0x6F,0x62,0x61,0x6C,0x73,0x69,0x67,0x6E,0x2E,0x63,
0x6F,0x6D,0x2F,0x67,0x73,0x2F,0x67,0x73,0x6F,0x72,0x67,0x61,0x6E,0x69,0x7A,0x61,
0x74,0x69,0x6F,0x6E,0x76,0x61,0x6C,0x73,0x68,0x61,0x32,0x67,0x32,0x2E,0x63,0x72,
0x6C,0x30,0x82,0x02,0xF8,0x06,0x03,0x55,0x1D,0x11,0x04,0x82,0x02,0xEF,0x30,0x82,
0x02,0xEB,0x82,0x0F,0x2A,0x2E,0x77,0x69,0x6B,0x69,0x70,0x65,0x64,0x69,0x61,0x2E,
0x6F,0x72,0x67,0x82,0x11,0x2A,0x2E,0x6D,0x2E,0x6D,0x65,0x64,0x69,0x61,0x77,0x69,
0x6B,0x69,0x2E,0x6F,0x72,0x67,0x82,0x11,0x2A,0x2E,0x6D,0x2E,0x77,0x69,0x6B,0x69,
0x62,0x6F,0x6F,0x6B,0x73,0x2E,0x6F,0x72,0x67,0x82,0x10,0x2A,0x2E,0x6D,0x2E,0x77,
0x69,0x6B,0x69,0x64,0x61,0x74,0x61,0x2E,0x6F,0x72,0x67,0x82,0x11,0x2A,0x2E,0x6D,
0x2E,0x77,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,0x82,0x1B,
0x2A,0x2E,0x6D,0x2E,0x77,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,0x66,0x6F,0x75,
0x6E,0x64,0x61,0x74,0x69,0x6F,0x6E,0x2E,0x6F,0x72,0x67,0x82,0x10,0x2A,0x2E,0x6D,
0x2E,0x77,0x69,0x6B,0x69,0x6E,0x65,0x77,0x73,0x2E,0x6F,0x72,0x67,0x82,0x11,0x2A,
0x2E,0x6D,0x2E,0x77,0x69,0x6B,0x69,0x70,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,
0x82,0x11,0x2A,0x2E,0x6D,0x2E,0x77,0x69,0x6B,0x69,0x71,0x75,0x6F,0x74,0x65,0x2E,
0x6F,0x72,0x67,0x82,0x12,0x2A,0x2E,0x6D,0x2E,0x77,0x69,0x6B,0x69,0x73,0x6F,0x75,
0x72,0x63,0x65,0x2E,0x6F,0x72,0x67,0x82,0x13,0x2A,0x2E,0x6D,0x2E,0x77,0x69,0x6B,
0x69,0x76,0x65,0x72,0x73,0x69,0x74,0x79,0x2E,0x6F,0x72,0x67,0x82,0x12,0x2A,0x2E,
0x6D,0x2E,0x77,0x69,0x6B,0x69,0x76,0x6F,0x79,0x61,0x67,0x65,0x2E,0x6F,0x72,0x67,
0x82,0x12,0x2A,0x2E,0x6D,0x2E,0x77,0x69,0x6B,0x74,0x69,0x6F,0x6E,0x61,0x72,0x79,
0x2E,0x6F,0x72,0x67,0x82,0x0F,0x2A,0x2E,0x6D,0x65,0x64,0x69,0x61,0x77,0x69,0x6B,
0x69,0x2E,0x6F,0x72,0x67,0x82,0x16,0x2A,0x2E,0x70,0x6C,0x61,0x6E,0x65,0x74,0x2E,
0x77,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,0x82,0x0F,0x2A,
0x2E,0x77,0x69,0x6B,0x69,0x62,0x6F,0x6F,0x6B,0x73,0x2E,0x6F,0x72,0x67,0x82,0x0E,
0x2A,0x2E,0x77,0x69,0x6B,0x69,0x64,0x61,0x74,0x61,0x2E,0x6F,0x72,0x67,0x82,0x0F,
0x2A,0x2E,0x77,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,0x82,
0x19,0x2A,0x2E,0x77,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,0x66,0x6F,0x75,0x6E,
0x64,0x61,0x74,0x69,0x6F,0x6E,0x2E,0x6F,0x72,0x67,0x82,0x0E,0x2A,0x2E,0x77,0x69,
0x6B,0x69,0x6E,0x65,0x77,0x73,0x2E,0x6F,0x72,0x67,0x82,0x0F,0x2A,0x2E,0x77,0x69,
0x6B,0x69,0x71,0x75,0x6F,0x74,0x65,0x2E,0x6F,0x72,0x67,0x82,0x10,0x2A,0x2E,0x77,
0x69,0x6B,0x69,0x73,0x6F,0x75,0x72,0x63,0x65,0x2E,0x6F,0x72,0x67,0x82,0x11,0x2A,
0x2E,0x77,0x69,0x6B,0x69,0x76,0x65,0x72,0x73,0x69,0x74,0x79,0x2E,0x6F,0x72,0x67,
0x82,0x10,0x2A,0x2E,0x77,0x69,0x6B,0x69,0x76,0x6F,0x79,0x61,0x67,0x65,0x2E,0x6F,
0x72,0x67,0x82,0x10,0x2A,0x2E,0x77,0x69,0x6B,0x74,0x69,0x6F,0x6E,0x61,0x72,0x79,
0x2E,0x6F,0x72,0x67,0x82,0x14,0x2A,0x2E,0x77,0x6D,0x66,0x75,0x73,0x65,0x72,0x63,
0x6F,0x6E,0x74,0x65,0x6E,0x74,0x2E,0x6F,0x72,0x67,0x82,0x14,0x2A,0x2E,0x7A,0x65,
0x72,0x6F,0x2E,0x77,0x69,0x6B,0x69,0x70,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,
0x82,0x0D,0x6D,0x65,0x64,0x69,0x61,0x77,0x69,0x6B,0x69,0x2E,0x6F,0x72,0x67,0x82,
0x06,0x77,0x2E,0x77,0x69,0x6B,0x69,0x82,0x0D,0x77,0x69,0x6B,0x69,0x62,0x6F,0x6F,
0x6B,0x73,0x2E,0x6F,0x72,0x67,0x82,0x0C,0x77,0x69,0x6B,0x69,0x64,0x61,0x74,0x61,
0x2E,0x6F,0x72,0x67,0x82,0x0D,0x77,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,0x2E,
0x6F,0x72,0x67,0x82,0x17,0x77,0x69,0x6B,0x69,0x6D,0x65,0x64,0x69,0x61,0x66,0x6F,
0x75,0x6E,0x64,0x61,0x74,0x69,0x6F,0x6E,0x2E,0x6F,0x72,0x67,0x82,0x0C,0x77,0x69,
0x6B,0x69,0x6E,0x65,0x77,0x73,0x2E,0x6F,0x72,0x67,0x82,0x0D,0x77,0x69,0x6B,0x69,
0x71,0x75,0x6F,0x74,0x65,0x2E,0x6F,0x72,0x67,0x82,0x0E,0x77,0x69,0x6B,0x69,0x73,
0x6F,0x75,0x72,0x63,0x65,0x2E,0x6F,0x72,0x67,0x82,0x0F,0x77,0x69,0x6B,0x69,0x76,
0x65,0x72,0x73,0x69,0x74,0x79,0x2E,0x6F,0x72,0x67,0x82,0x0E,0x77,0x69,0x6B,0x69,
0x76,0x6F,0x79,0x61,0x67,0x65,0x2E,0x6F,0x72,0x67,0x82,0x0E,0x77,0x69,0x6B,0x74,
0x69,0x6F,0x6E,0x61,0x72,0x79,0x2E,0x6F,0x72,0x67,0x82,0x12,0x77,0x6D,0x66,0x75,
0x73,0x65,0x72,0x63,0x6F,0x6E,0x74,0x65,0x6E,0x74,0x2E,0x6F,0x72,0x67,0x82,0x0D,
0x77,0x69,0x6B,0x69,0x70,0x65,0x64,0x69,0x61,0x2E,0x6F,0x72,0x67,0x30,0x1D,0x06,
0x03,0x55,0x1D,0x25,0x04,0x16,0x30,0x14,0x06,0x08,0x2B,0x06,0x01,0x05,0x05,0x07,
0x03,0x01,0x06,0x08,0x2B,0x06,0x01,0x05,0x05,0x07,0x03,0x02,0x30,0x1D,0x06,0x03,
0x55,0x1D,0x0E,0x04,0x16,0x04,0x14,0xBC,0x93,0xB7,0x81,0xF9,0x8E,0x73,0x79,0xE8,
0x57,0x77,0xFF,0xBB,0x2D,0x96,0x32,0x72,0x37,0xA5,0x85,0x30,0x1F,0x06,0x03,0x55,
0x1D,0x23,0x04,0x18,0x30,0x16,0x80,0x14,0x96,0xDE,0x61,0xF1,0xBD,0x1C,0x16,0x29,
0x53,0x1C,0xC0,0xCC,0x7D,0x3B,0x83,0x00,0x40,0xE6,0x1A,0x7C,0x30,0x82,0x01,0xF5,
0x06,0x0A,0x2B,0x06,0x01,0x04,0x01,0xD6,0x79,0x02,0x04,0x02,0x04,0x82,0x01,0xE5,
0x04,0x82,0x01,0xE1,0x01,0xDF,0x00,0x75,0x00,0xDD,0xEB,0x1D,0x2B,0x7A,0x0D,0x4F,
0xA6,0x20,0x8B,0x81,0xAD,0x81,0x68,0x70,0x7E,0x2E,0x8E,0x9D,0x01,0xD5,0x5C,0x88,
0x8D,0x3D,0x11,0xC4,0xCD,0xB6,0xEC,0xBE,0xCC,0x00,0x00,0x01,0x5F,0x7F,0xF8,0xAA,
0x82,0x00,0x00,0x04,0x03,0x00,0x46,0x30,0x44,0x02,0x20,0x38,0x14,0x02,0xD7,0xF3,
0x55,0xD6,0x30,0x01,0xF4,0x64,0xFE,0x12,0x84,0x5E,0x32,0x6E,0xE1,0xD5,0x01,0x05,
0xC3,0xF1,0x50,0x5D,0x51,0xD1,0x20,0x29,0x7D,0xA6,0xF7,0x02,0x20,0x58,0xC1,0x8D,
0x46,0x4A,0xED,0xBA,0xA1,0xD9,0x05,0xA9,0x0B,0x17,0x83,0x51,0xF8,0x1E,0x69,0xAE,
0x4E,0xA9,0xD8,0x97,0xC7,0x68,0xC2,0x4E,0x60,0xD3,0x7B,0xF5,0xE4,0x00,0x76,0x00,
0x56,0x14,0x06,0x9A,0x2F,0xD7,0xC2,0xEC,0xD3,0xF5,0xE1,0xBD,0x44,0xB2,0x3E,0xC7,
0x46,0x76,0xB9,0xBC,0x99,0x11,0x5C,0xC0,0xEF,0x94,0x98,0x55,0xD6,0x89,0xD0,0xDD,
0x00,0x00,0x01,0x5F,0x7F,0xF8,0xAA,0xDA,0x00,0x00,0x04,0x03,0x00,0x47,0x30,0x45,
0x02,0x20,0x0C,0xCD,0x09,0xDE,0x5C,0xEA,0xE9,0xC9,0x7E,0x74,0x64,0xF3,0x1D,0xC5,
0x72,0x19,0x26,0x6F,0x92,0x28,0x9C,0xD0,0x1A,0x67,0x43,0xA0,0x38,0x75,0x13,0x7E,
0xC1,0x23,0x02,0x21,0x00,0x9B,0x01,0x9F,0xAD,0xC8,0x6F,0x07,0xF1,0xD0,0x3E,0x89,
0xDF,0xC9,0xD6,0x6E,0xBD,0xE1,0xAE,0xE7,0x68,0x30,0xD1,0x5F,0x34,0x48,0x56,0xD5,
0x50,0xF3,0x7F,0x81,0x8B,0x00,0x76,0x00,0xA4,0xB9,0x09,0x90,0xB4,0x18,0x58,0x14,
0x87,0xBB,0x13,0xA2,0xCC,0x67,0x70,0x0A,0x3C,0x35,0x98,0x04,0xF9,0x1B,0xDF,0xB8,
0xE3,0x77,0xCD,0x0E,0xC8,0x0D,0xDC,0x10,0x00,0x00,0x01,0x5F,0x7F,0xF8,0xAD,0x4A,
0x00,0x00,0x04,0x03,0x00,0x47,0x30,0x45,0x02,0x20,0x3E,0x27,0x0F,0xB4,0xED,0x7C,
0xC4,0x6E,0x81,0x8B,0xFB,0x60,0x7C,0x5A,0xB7,0xFC,0x67,0xDA,0x50,0x5B,0x3E,0x53,
0xED,0x54,0x19,0x4F,0xA3,0xB7,0x75,0x40,0xC8,0xBC,0x02,0x21,0x00,0xC2,0x0D,0x4D,
0xD0,0xA0,0x00,0x6A,0x95,0x0A,0x21,0x17,0x32,0xD7,0xCB,0xB9,0xDF,0x9A,0x8E,0x23,
0x19,0xBA,0x71,0x59,0x9E,0xCF,0xC3,0x28,0x8E,0x53,0x52,0x0E,0xF8,0x00,0x76,0x00,
0xEE,0x4B,0xBD,0xB7,0x75,0xCE,0x60,0xBA,0xE1,0x42,0x69,0x1F,0xAB,0xE1,0x9E,0x66,
0xA3,0x0F,0x7E,0x5F,0xB0,0x72,0xD8,0x83,0x00,0xC4,0x7B,0x89,0x7A,0xA8,0xFD,0xCB,
0x00,0x00,0x01,0x5F,0x7F,0xF8,0xB0,0x31,0x00,0x00,0x04,0x03,0x00,0x47,0x30,0x45,
0x02,0x21,0x00,0x91,0x26,0x1E,0x19,0xFF,0x66,0xC6,0x67,0xE5,0x54,0x57,0xBE,0x11,
0x7C,0xFA,0x10,0x3A,0x68,0xF8,0x38,0x42,0x10,0x6D,0x77,0x09,0xCA,0xB4,0xEF,0xE2,
0xCA,0xE6,0x37,0x02,0x20,0x11,0xC5,0xA3,0xDB,0x0B,0x58,0x3D,0xCD,0x2D,0xC6,0x74,
0x45,0x63,0x9D,0x68,0x26,0x9D,0x73,0x8C,0x30,0x96,0x8C,0x30,0x1F,0x89,0xE1,0x40,
0x6B,0x08,0x56,0x01,0x1F,0x30,0x0D,0x06,0x09,0x2A,0x86,0x48,0x86,0xF7,0x0D,0x01,
0x01,0x0B,0x05,0x00,0x03,0x82,0x01,0x01,0x00,0x51,0x1E,0x84,0x93,0x2E,0x72,0x35,
0x97,0x9B,0x2E,0x89,0x3C,0x54,0x07,0xA9,0x95,0xAF,0xAE,0xB4,0x78,0x97,0xA9,0x83,
0xE5,0x4D,0x69,0x48,0x0B,0x33,0x52,0x6D,0xEF,0x98,0x32,0x5B,0x47,0x95,0x93,0x9B,
0xFE,0xEF,0x16,0x92,0x7C,0x80,0x07,0x89,0x9C,0xC6,0xD1,0xAB,0x9B,0xE7,0x63,0x40,
0x2E,0xC5,0x39,0x20,0x65,0xB5,0xDD,0x43,0x0B,0x82,0x4A,0x7D,0xE0,0x3E,0xB5,0x5F,
0x1F,0xC2,0xD7,0x71,0x0E,0x4E,0xDC,0x2C,0xAB,0x86,0xAC,0xA6,0xB5,0x70,0x9E,0x88,
0xDC,0x6B,0xEE,0x5E,0x04,0x95,0x97,0x6F,0xE0,0xC6,0x59,0x6A,0x7B,0x1B,0xC9,0xA7,
0xA6,0xA4,0xE0,0xA0,0x81,0x55,0xD6,0x6C,0xAA,0xD0,0x6B,0x99,0x98,0x8C,0xCF,0x0F,
0xC3,0x44,0x77,0x2A,0xF9,0x43,0x87,0xC6,0x67,0x66,0x3F,0x0E,0xE3,0x9E,0x24,0xC6,
0xAD,0xFB,0x6D,0x49,0xF6,0x0D,0x96,0xE6,0xF4,0x70,0xDC,0x9D,0xAA,0x4D,0xD5,0xD2,
0xF8,0xF1,0xEA,0x33,0x6C,0x83,0x49,0x96,0x66,0xC5,0x37,0x83,0x12,0x1D,0xD8,0x08,
0x00,0x97,0xA5,0xE8,0xE1,0x2B,0x31,0x86,0x6A,0xD6,0x0B,0x2A,0xA1,0x89,0x63,0x48,
0xE0,0x90,0xFB,0x58,0xE1,0x32,0x6A,0x15,0xAD,0x3E,0x56,0xC6,0x95,0xDB,0x6D,0x04,
0xCD,0x3E,0x94,0x58,0xF6,0x38,0x64,0xD5,0x6F,0x4D,0xA0,0xE3,0x98,0x32,0x7E,0x78,
0x52,0xD5,0xFA,0xC0,0x95,0x7B,0xA5,0x62,0xE5,0x1D,0xF4,0x72,0x93,0x59,0x28,0x44,
0x46,0xE7,0x19,0x5A,0xC7,0x12,0x90,0x54,0x06,0x26,0x15,0x7A,0x18,0x8A,0x51,0xF4,
0x6C,0x9E,0xB3,0x18,0x79,0x9A,0x2A,0x35,0x08,
};The structure of an X.509 v3 digital certificate is as follows: Certificate Version Number Serial Number Signature Algorithm ID Issuer Name Validity period Not Before Not After Subject name Subject Public Key Info Public Key Algorithm Subject Public Key Issuer Unique Identifier (optional) Subject Unique Identifier (optional) Extensions (optional) ... Certificate Signature Algorithm Certificate Signature
Certificate ::= SEQUENCE {
tbsCertificate TBSCertificate,
signatureAlgorithm AlgorithmIdentifier,
signatureValue BIT STRING }
TBSCertificate ::= SEQUENCE {
version [0] EXPLICIT Version DEFAULT v1,
serialNumber CertificateSerialNumber,
signature AlgorithmIdentifier,
issuer Name,
validity Validity,
subject Name,
subjectPublicKeyInfo SubjectPublicKeyInfo,
issuerUniqueID [1] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
subjectUniqueID [2] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
extensions [3] EXPLICIT Extensions OPTIONAL
-- If present, version MUST be v3
}
openssl x509 -in wikipedia.crt -text -noout
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
09:de:73:4b:91:75:4c:18:79:c0:ae:4e
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=BE, O=GlobalSign nv-sa, CN=GlobalSign Organization Validation CA - SHA256 - G2
Validity
Not Before: Nov 3 03:42:02 2017 GMT
Not After : Nov 22 07:59:59 2018 GMT
Subject: C=US, ST=California, L=San Francisco, O=Wikimedia Foundation, Inc., CN=*.wikipedia.org
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:ef:53:4d:f8:6f:b7:72:b2:45:a2:0d:29:84:1c:
ae:de:04:ee:16:88:8b:c1:3d:e8:b6:23:a9:75:72:
71:a4:d1:1f:46:03:33:22:f5:72:56:3f:df:1f:2b:
93:d2:41:b7:39:f9:74:4f:20:0a:1d:e9:c0:47:89:
80:0b:5f:68:03
ASN1 OID: prime256v1
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Agreement
Authority Information Access:
CA Issuers - URI:http://secure.globalsign.com/cacert/gsorganizationvalsha2g2r1.crt
OCSP - URI:http://ocsp2.globalsign.com/gsorganizationvalsha2g2
X509v3 Certificate Policies:
Policy: 1.3.6.1.4.1.4146.1.20
CPS: https://www.globalsign.com/repository/
Policy: 2.23.140.1.2.2
X509v3 Basic Constraints:
CA:FALSE
X509v3 CRL Distribution Points:
Full Name:
URI:http://crl.globalsign.com/gs/gsorganizationvalsha2g2.crl
X509v3 Subject Alternative Name:
DNS:*.wikipedia.org, DNS:*.m.mediawiki.org, DNS:*.m.wikibooks.org, DNS:*.m.wikidata.org, DNS:*.m.wikimedia.org, DNS:*.m.wikimediafoundation.org, DNS:*.m.wikinews.org, DNS:*.m.wikipedia.org, DNS:*.m.wikiquote.org, DNS:*.m.wikisource.org, DNS:*.m.wikiversity.org, DNS:*.m.wikivoyage.org, DNS:*.m.wiktionary.org, DNS:*.mediawiki.org, DNS:*.planet.wikimedia.org, DNS:*.wikibooks.org, DNS:*.wikidata.org, DNS:*.wikimedia.org, DNS:*.wikimediafoundation.org, DNS:*.wikinews.org, DNS:*.wikiquote.org, DNS:*.wikisource.org, DNS:*.wikiversity.org, DNS:*.wikivoyage.org, DNS:*.wiktionary.org, DNS:*.wmfusercontent.org, DNS:*.zero.wikipedia.org, DNS:mediawiki.org, DNS:w.wiki, DNS:wikibooks.org, DNS:wikidata.org, DNS:wikimedia.org, DNS:wikimediafoundation.org, DNS:wikinews.org, DNS:wikiquote.org, DNS:wikisource.org, DNS:wikiversity.org, DNS:wikivoyage.org, DNS:wiktionary.org, DNS:wmfusercontent.org, DNS:wikipedia.org
X509v3 Extended Key Usage:
TLS Web Server Authentication, TLS Web Client Authentication
X509v3 Subject Key Identifier:
BC:93:B7:81:F9:8E:73:79:E8:57:77:FF:BB:2D:96:32:72:37:A5:85
X509v3 Authority Key Identifier:
keyid:96:DE:61:F1:BD:1C:16:29:53:1C:C0:CC:7D:3B:83:00:40:E6:1A:7C
1.3.6.1.4.1.11129.2.4.2:
O. ....hp~.....\..=.........._.........F0D. 8....U.0..d...^2n......P]Q. )}... X..FJ.........Q..i.N....h.N`.{...v.V.../.......D.>.Fv....\....U......._.........G0E. ....\...~td...r.&o.(...gC.8u.~.#.!......o...>....n....h0._4HV.P.....v.......X......gp
M...j....J.....G0E. >'...|.n...`|Z..g.P[>S.T.O..u@...!..
!.2......#..qY...(.SR...v..K..u.`..Bi....f..~_.r....{.z......_...1.....G0E.!..&...f.g.TW..|..:h.8B.mw.......7. .....X=.-.tEc.h&.s.0..0...@k.V..
Signature Algorithm: sha256WithRSAEncryption
51:1e:84:93:2e:72:35:97:9b:2e:89:3c:54:07:a9:95:af:ae:
b4:78:97:a9:83:e5:4d:69:48:0b:33:52:6d:ef:98:32:5b:47:
95:93:9b:fe:ef:16:92:7c:80:07:89:9c:c6:d1:ab:9b:e7:63:
40:2e:c5:39:20:65:b5:dd:43:0b:82:4a:7d:e0:3e:b5:5f:1f:
c2:d7:71:0e:4e:dc:2c:ab:86:ac:a6:b5:70:9e:88:dc:6b:ee:
5e:04:95:97:6f:e0:c6:59:6a:7b:1b:c9:a7:a6:a4:e0:a0:81:
55:d6:6c:aa:d0:6b:99:98:8c:cf:0f:c3:44:77:2a:f9:43:87:
c6:67:66:3f:0e:e3:9e:24:c6:ad:fb:6d:49:f6:0d:96:e6:f4:
70:dc:9d:aa:4d:d5:d2:f8:f1:ea:33:6c:83:49:96:66:c5:37:
83:12:1d:d8:08:00:97:a5:e8:e1:2b:31:86:6a:d6:0b:2a:a1:
89:63:48:e0:90:fb:58:e1:32:6a:15:ad:3e:56:c6:95:db:6d:
04:cd:3e:94:58:f6:38:64:d5:6f:4d:a0:e3:98:32:7e:78:52:
d5:fa:c0:95:7b:a5:62:e5:1d:f4:72:93:59:28:44:46:e7:19:
5a:c7:12:90:54:06:26:15:7a:18:8a:51:f4:6c:9e:b3:18:79:
9a:2a:35:08
openssl x509 -in gsorganizationvalsha2g2r1.crt -inform der -noout -pubkey
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAxw5sPyOTf8xwpZ0gww5T
P37ATsKYScpH1SPvAzSFdMijAi5GXAt9yYidT4vw+JxsjFU127/ys+r741bnSkbZ
EyLKNtWbwajjlkOT8gy85vnm6JnIY0h4f1c2aRoZHVrR1H3CnNR/4YASrnrqiOpX
2MoKCjoSSaJiGXoNJPc367RzknsFI5sStc7rKd+kFAK5AaXUppxDZIje+H7+4/Ue
5f7co6jkZjHZTCXpGLmJWQmu6Z0cbTcPSh41ICjir9QhiwHERa1uK2OrkmthCk0g
7XO6fM7+FrXbn4Dw1ots2Qh5Sk94ZdqSvL41+bPE+SeATv+WUuYCIOEHc+ldK72y
8QIDAQAB
-----END PUBLIC KEY-----一月三十日 等待变化等待机会
/* demos/sign/sign.c */
/* sign-it.cpp - Simple test app using SSLeay envelopes to sign data
29.9.1996, Sampo Kellomaki <sampo@iki.fi> */
/* converted to C - eay :-) */
/* reformated a bit and converted to use the more common functions: this was
* initially written at the dawn of time :-) - Steve.
*/
#include <stdio.h>
#include <openssl/rsa.h>
#include <openssl/evp.h>
#include <openssl/objects.h>
#include <openssl/x509.h>
#include <openssl/err.h>
#include <openssl/pem.h>
#include <openssl/ssl.h>
int main ()
{
int err;
int sig_len;
unsigned char sig_buf [4096];
static char certfile[] = "cert.pem";
static char keyfile[] = "key.pem";
static char data[] = "I owe you...";
EVP_MD_CTX md_ctx;
EVP_PKEY * pkey;
FILE * fp;
X509 * x509;
/* Just load the crypto library error strings,
* SSL_load_error_strings() loads the crypto AND the SSL ones */
/* SSL_load_error_strings();*/
ERR_load_crypto_strings();
/* Read private key */
fp = fopen (keyfile, "r");
if (fp == NULL) exit (1);
pkey = PEM_read_PrivateKey(fp, NULL, NULL, NULL);
fclose (fp);
if (pkey == NULL) {
ERR_print_errors_fp (stderr);
exit (1);
}
/* Do the signature */
EVP_SignInit (&md_ctx, EVP_sha1());
EVP_SignUpdate (&md_ctx, data, strlen(data));
sig_len = sizeof(sig_buf);
err = EVP_SignFinal (&md_ctx, sig_buf, &sig_len, pkey);
if (err != 1) {
ERR_print_errors_fp(stderr);
exit (1);
}
EVP_PKEY_free (pkey);
/* Read public key */
fp = fopen (certfile, "r");
if (fp == NULL) exit (1);
x509 = PEM_read_X509(fp, NULL, NULL, NULL);
fclose (fp);
if (x509 == NULL) {
ERR_print_errors_fp (stderr);
exit (1);
}
/* Get public key - eay */
pkey=X509_get_pubkey(x509);
if (pkey == NULL) {
ERR_print_errors_fp (stderr);
exit (1);
}
/* Verify the signature */
EVP_VerifyInit (&md_ctx, EVP_sha1());
EVP_VerifyUpdate (&md_ctx, data, strlen((char*)data));
err = EVP_VerifyFinal (&md_ctx, sig_buf, sig_len, pkey);
EVP_PKEY_free (pkey);
if (err != 1) {
ERR_print_errors_fp (stderr);
exit (1);
}
printf ("Signature Verified Ok.\n");
return(0);
}openssl req -nodes -x509 -sha256 -newkey rsa:4096 -keyout "private_key.pem" -out "certificate.pem" -days 365 -subj "/C=US/ST=CA/L=SAN JOSE/O=PARC22/OU=HOME/CN=NICK SIGN KEY"openssl dgst -sha256 -sign private_key.pem -out nick.sign.sha256 sign.txtopenssl dgst -sha256 -verify <(openssl x509 -in certificate.pem -pubkey -noout) -signature sign_rsa256.signature sign.txtauto eth0
iface eth0 inet static
address 192.168.1.226
netmask 255.255.255.0
network 192.168.1.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-nameservers 192.168.1.1
dns-nameservers 8.8.8.8二月一日 等待变化等待机会
你有没有想过怎样产生质数来生成key作加密运算?openss里的一个demo程序很简单的说明了这个过程的主要函数的用法:BN_generate_prime(结果我google发现它已经deprecated了)000000000009fb50 g DF .text 000000000000000a OPENSSL_1.0.0 BN_is_prime_exVersion definitions:
1 0x01 0x0746be50 libcrypto.so.1.0.0
2 0x00 0x066a2b20 OPENSSL_1.0.0
3 0x00 0x066a2b21 OPENSSL_1.0.1
OPENSSL_1.0.0
4 0x00 0x06a2b214 OPENSSL_1.0.1d
OPENSSL_1.0.1
$ gcc -print-file-name=libcrypto.so
/usr/lib/gcc/x86_64-linux-gnu/4.8/../../../x86_64-linux-gnu/libcrypto.so二月二日 等待变化等待机会
难道我这么多年都白学了?你在链接的搜索位置居然影响到最后结果?比如gcc -o "primeTest" primeTest.c -lcrypto和gcc -lcrypto -o "primeTest" primeTest.c结果大不相同!!!
libs display library search paths
reloc display relocation processing
files display progress for input file
symbols display symbol table processing
bindings display information about symbol binding
versions display version dependencies
scopes display scope information
all all previous options combined
statistics display relocation statistics
unused determined unused DSOs
help display this help message and exit二月三日 等待变化等待机会
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <openssl/bn.h>
void callback(type,
num)
int type, num;
{
// if (type == 0)
// fprintf(stderr, ".");
// else if (type == 1)
// fprintf(stderr, "+");
// else if (type == 2)
// fprintf(stderr, "*");
// fflush(stderr);
}
int newCallback(int a, int b, BN_GENCB* cb)
{
// switch (a)
// {
// case 0:
// //printf("0(%d)", b);
// printf("0");
// break;
// case 1:
// //printf("1[%d]", b);
// printf("1");
// break;
// case 2:
// //printf("2{%d}", b);
// printf("2");
// break;
// default:
// printf("%d", a);
// break;
// }
return 1;
}
char buff[20];
time_t now;
int oldFunc(int argc, char* argv[])
{
BIGNUM* rand = BN_new();;
int num=256;
if (argc >= 2)
{
num=atoi(argv[1]);
if (num == 0)
num=256;
}
fprintf(stderr, "generate a strong prime\n");
now = time(NULL);
strftime(buff, 20, "%Y-%m-%d %H:%M:%S", localtime(&now));
printf("\ntime:[%s]\n", buff);
rand = BN_generate_prime(rand, num, 1, NULL, NULL, callback, NULL);
BN_print_fp(stdout, rand);
now = time(NULL);
strftime(buff, 20, "%Y-%m-%d %H:%M:%S", localtime(&now));
printf("\ntime:[%s]\n", buff);
fprintf(stdout, "\n");
fprintf(stdout, "\n");
return 0;
}
int newFunc(int argc, char *argv[])
{
int num = 256;
if (argc >= 2)
{
num=atoi(argv[1]);
if (num == 0)
{
num=256;
}
}
BIGNUM *bn = BN_new();
BN_GENCB cb;
cb.ver = 2;
cb.cb.cb_2 = newCallback;
cb.arg = NULL;
now = time(NULL);
strftime(buff, 20, "%Y-%m-%d %H:%M:%S", localtime(&now));
printf("\ntime:[%s]\n", buff);
if (!BN_generate_prime_ex(bn, num, 1, NULL, NULL, &cb))
{
printf("Failed to generate prime.\n");
}
else
{
printf("bits:%d\n", num);
BN_print_fp(stdout, bn);
printf("\n");
}
now = time(NULL);
strftime(buff, 20, "%Y-%m-%d %H:%M:%S", localtime(&now));
printf("\ntime:[%s]\n", buff);
BN_free(bn);
return 0;
}
int main(int argc, char* argv[])
{
oldFunc(argc, argv);
newFunc(argc, argv);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <openssl/evp.h>
#include <openssl/rsa.h>
#include <openssl/err.h>
#include <openssl/bio.h>
int printBIO(const char* strCtx, BIO* bio)
{
char buffer[2048+1];
int num = 0;
printf("*******%s begins*****\n", strCtx);
while ((num = BIO_gets(bio, buffer, 2048))>0)
{
buffer[num] = '\0';
printf("%s", buffer);
}
printf("********%s ends*****\n", strCtx);
if (num < 0)
{
printf("BIO_gets error: %s\n", ERR_error_string(ERR_get_error(), NULL));
return -1;
}
return 0;
}
int main(void)
{
EVP_PKEY_CTX *ctx = NULL;
BIO* bio = NULL;
EVP_PKEY *pkey = NULL;
pkey = EVP_PKEY_new();
if (pkey == NULL)
{
printf("EVP_PKEY_new error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
ctx = EVP_PKEY_CTX_new_id(EVP_PKEY_RSA, NULL);
if (!ctx)
{
printf("EVP_PKEY_CTX_new_id error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
if (EVP_PKEY_keygen_init(ctx) <= 0)
{
printf("EVP_PKEY_CTX_new_id error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
if (EVP_PKEY_CTX_set_rsa_keygen_bits(ctx, 2048) <= 0)
{
printf("EVP_PKEY_CTX_set_rsa_keygen_bits error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
/* Generate key */
if (EVP_PKEY_keygen(ctx, &pkey) <= 0)
{
printf("EVP_PKEY_keygen error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
bio = BIO_new(BIO_s_mem());
if (bio == NULL)
{
printf("BIO_new error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
if (EVP_PKEY_print_public(bio, pkey, 1, NULL)!= 1)
{
printf("EVP_PKEY_print_public error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
if (printBIO("public key", bio) < 0)
{
printf("print public key failed\n");
goto clear;
}
if (EVP_PKEY_print_private(bio, pkey, 1, NULL)!= 1)
{
printf("EVP_PKEY_print_private error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
if (printBIO("private key", bio) < 0)
{
printf("print private key failed\n");
goto clear;
}
if (EVP_PKEY_print_params(bio, pkey, 1, NULL)!= 1)
{
printf("EVP_PKEY_print_params error: %s\n", ERR_error_string(ERR_get_error(), NULL));
goto clear;
}
if (printBIO("key params", bio) < 0)
{
printf("print key params failed\n");
goto clear;
}
clear:
if (pkey)
{
EVP_PKEY_free(pkey);
}
if (ctx)
{
EVP_PKEY_CTX_free(ctx);
}
if (bio)
{
BIO_free(bio);
}
return 0;
}
*******public key begins*****
Public-Key: (2048 bit)
Modulus:
00:c0:06:57:34:eb:12:9a:87:b1:a9:53:6d:b8:a6:
c1:99:6d:35:53:b3:c0:01:c0:5b:1b:1f:8e:ca:ec:
28:9f:29:d3:62:b0:fa:f9:38:72:f7:14:18:1b:fa:
0c:28:45:2b:c2:39:35:2e:9f:c3:f2:47:a8:ba:5b:
53:c6:db:be:d1:6d:67:d3:15:6b:d0:6d:db:5a:1f:
2b:70:1e:8d:30:eb:12:29:9f:83:e0:0f:3b:a3:76:
2e:12:61:16:d8:34:54:cd:a6:7e:71:3d:68:67:13:
b1:37:95:66:24:c3:3e:2e:6a:b2:f1:a2:9c:a7:24:
44:58:21:28:b5:b1:8c:32:a6:77:44:be:11:9b:df:
74:77:36:2f:06:2b:8e:52:47:67:10:26:ef:d1:2b:
42:f7:6c:b0:bb:98:36:0e:bd:1e:a2:58:68:20:7c:
35:e9:55:c5:6c:bb:c8:e1:6e:99:d4:ec:f3:59:14:
ea:3a:03:36:20:95:90:e9:ad:8b:09:49:9b:65:b2:
65:14:00:05:4a:c1:bb:15:6d:92:78:2c:a1:44:f9:
9a:59:28:ab:6c:73:5e:65:cb:81:20:8c:62:2f:3a:
3b:7a:da:a1:84:e3:d4:84:e5:9f:38:e5:ae:22:3f:
92:03:42:ce:72:49:6c:f9:7f:9a:98:ce:82:94:22:
c0:2f
Exponent: 65537 (0x10001)
********public key ends*****
*******private key begins*****
Private-Key: (2048 bit)
modulus:
00:c0:06:57:34:eb:12:9a:87:b1:a9:53:6d:b8:a6:
c1:99:6d:35:53:b3:c0:01:c0:5b:1b:1f:8e:ca:ec:
28:9f:29:d3:62:b0:fa:f9:38:72:f7:14:18:1b:fa:
0c:28:45:2b:c2:39:35:2e:9f:c3:f2:47:a8:ba:5b:
53:c6:db:be:d1:6d:67:d3:15:6b:d0:6d:db:5a:1f:
2b:70:1e:8d:30:eb:12:29:9f:83:e0:0f:3b:a3:76:
2e:12:61:16:d8:34:54:cd:a6:7e:71:3d:68:67:13:
b1:37:95:66:24:c3:3e:2e:6a:b2:f1:a2:9c:a7:24:
44:58:21:28:b5:b1:8c:32:a6:77:44:be:11:9b:df:
74:77:36:2f:06:2b:8e:52:47:67:10:26:ef:d1:2b:
42:f7:6c:b0:bb:98:36:0e:bd:1e:a2:58:68:20:7c:
35:e9:55:c5:6c:bb:c8:e1:6e:99:d4:ec:f3:59:14:
ea:3a:03:36:20:95:90:e9:ad:8b:09:49:9b:65:b2:
65:14:00:05:4a:c1:bb:15:6d:92:78:2c:a1:44:f9:
9a:59:28:ab:6c:73:5e:65:cb:81:20:8c:62:2f:3a:
3b:7a:da:a1:84:e3:d4:84:e5:9f:38:e5:ae:22:3f:
92:03:42:ce:72:49:6c:f9:7f:9a:98:ce:82:94:22:
c0:2f
publicExponent: 65537 (0x10001)
privateExponent:
64:9f:6d:f7:36:ef:6a:b6:8c:6c:74:61:5c:8f:55:
87:b6:68:69:52:19:dd:51:14:ec:a3:9e:c9:ca:f2:
86:64:fe:76:0a:d3:98:e0:f1:ad:73:84:26:b4:e2:
c5:ff:69:2c:bf:99:94:b2:f7:94:ef:e4:04:b3:72:
b5:13:d5:6c:1c:ee:78:f8:12:a5:07:cc:17:ef:99:
6d:89:34:e7:5b:67:0b:14:a1:a0:39:9b:40:ce:de:
d9:96:b2:c7:dc:b4:4b:87:61:5e:a9:95:19:de:81:
d0:e4:a2:bf:c4:e7:c2:9e:fa:e2:10:1a:12:a3:b8:
84:8d:eb:ad:3a:3a:83:17:39:59:4d:9b:8c:76:73:
0d:8c:dc:e0:dd:21:0d:af:45:4a:29:57:e1:04:df:
9e:9c:26:dc:72:7b:5b:e5:5c:a7:0f:d7:db:f0:fe:
2b:3d:b5:f8:00:5c:ee:1f:b2:ca:04:8d:3a:94:26:
86:08:1a:b1:1e:9b:df:81:82:ae:d9:db:6f:74:9a:
dc:7c:f9:f0:f0:62:c4:2a:c6:89:84:e5:9d:5e:da:
54:d4:c5:da:2d:fd:b2:6a:ab:d7:d4:ee:8d:bf:d7:
e5:43:ef:e8:d8:88:0b:0d:13:58:26:45:d9:3a:1f:
ee:d9:74:dd:f2:75:cb:1c:1b:35:57:c6:3d:d4:2a:
a1
prime1:
00:ff:70:89:15:d8:db:20:f9:38:05:bc:83:7a:c0:
da:29:ed:96:6e:21:0b:65:1e:cd:dd:a6:76:3e:13:
d0:39:54:9b:bb:0c:d4:c6:65:34:ee:b2:66:5b:6a:
c3:c9:f1:ab:96:20:8f:4a:e1:b1:67:bc:79:aa:9d:
33:9f:2d:23:1f:4a:b1:7b:b1:1b:43:7a:f8:35:b7:
b1:c3:70:85:b2:4e:00:24:d0:3c:67:58:7f:19:19:
51:95:da:99:23:b9:c9:db:6c:da:8c:91:08:8f:02:
af:5a:82:e6:84:c1:73:95:b9:3f:0f:e6:79:76:18:
e3:69:c8:75:ac:ba:8e:dc:97
prime2:
00:c0:72:30:62:9a:41:8f:78:72:85:8f:88:c8:8a:
66:f8:46:75:d5:97:a3:76:5a:4c:a2:cd:9e:aa:f5:
4c:a2:e5:7d:96:ff:94:93:38:99:d4:7e:61:f9:51:
e5:b5:cc:a0:eb:ae:70:d4:ce:8a:c8:50:63:c8:60:
34:8c:8b:81:19:43:cf:0d:d8:60:68:6f:06:b9:59:
66:08:65:a0:78:2f:12:af:e7:c7:9d:67:9b:e4:54:
17:88:96:77:96:48:20:c3:ba:1f:d4:36:64:37:b8:
97:56:47:82:91:7d:8a:92:5a:bb:64:cc:9c:7c:6b:
52:a8:66:e3:ab:73:bb:74:29
exponent1:
1d:c3:2a:f5:d4:b2:93:80:f6:3a:14:e0:ec:e8:93:
82:d7:1f:f3:ec:fd:ba:e6:7f:ee:17:7b:27:78:7f:
86:6e:89:46:9e:14:1c:99:a6:35:39:ac:1b:72:b1:
25:52:77:3f:a2:c3:8f:62:04:9d:a5:a4:37:70:e1:
96:e6:57:75:49:ea:ac:12:d2:ae:66:21:8d:80:bd:
c1:9b:d6:b8:13:c6:88:83:8a:c6:2f:d5:7f:43:27:
f2:61:e9:fd:f3:a3:c5:61:45:85:a3:50:6f:f9:4c:
1d:2b:ab:58:44:82:07:2b:f2:61:13:e5:8b:11:13:
4e:3c:01:1a:03:12:aa:39
exponent2:
3c:38:7f:63:9b:99:c0:67:94:8e:ae:e7:c2:b9:6c:
97:6c:95:1b:0d:a4:9d:38:8c:9a:b5:75:5d:51:fd:
75:4c:13:0c:d9:55:88:ec:41:56:f9:65:77:3b:65:
82:8a:52:20:ee:29:68:ae:69:47:5d:c0:9b:c7:5f:
2a:4b:cd:4e:36:a5:e8:53:39:77:f4:a6:4a:01:eb:
a7:dd:05:66:16:74:e6:8e:c5:2c:40:6b:cb:fb:74:
91:cd:64:06:a6:f3:79:cc:18:81:b3:b3:90:ac:36:
cf:4c:f9:52:c5:d2:43:12:19:69:e5:8d:62:71:c3:
1f:e7:72:7f:08:6c:34:61
coefficient:
00:db:d4:8c:80:bc:17:3f:f5:68:51:da:d3:a9:8d:
01:50:e4:5d:a5:c1:bc:55:20:83:64:b5:2b:0e:cb:
a6:b5:d6:8f:0c:7c:d8:c4:2e:a8:72:ed:dc:a3:d3:
a7:73:be:05:33:27:bd:59:7e:01:e1:9f:88:08:73:
ee:ee:9a:1e:cf:19:28:1e:dc:b8:0d:ef:1b:50:91:
d3:0b:f9:93:6a:52:99:9f:8d:74:80:9b:51:87:0e:
c2:b3:a9:7f:d5:79:1c:4b:88:bc:5e:16:42:f2:92:
e9:d8:78:de:68:1f:ef:43:24:6a:ad:3d:30:c3:76:
f5:c1:4f:94:9b:df:83:ce:9e
********private key ends*****
*******key params begins*****
Parameters algorithm "rsaEncryption" unsupported
********key params ends*****二月五日 等待变化等待机会
照猫画虎式的把manpage的例子代码稍微的实践了一下:
int signTest(EVP_PKEY *pkey, const unsigned char* msg, size_t msgSize, unsigned char** sig, size_t* sigSize)
{
if (pkey == NULL || msg == NULL || msgSize == 0 || sig == NULL || sigSize== NULL)
{
printf("invalid parameter!\n");
return -1;
}
int result = 0;
EVP_PKEY_CTX *ctx = NULL;
ctx = EVP_PKEY_CTX_new(pkey, NULL); //a very different ctx from key generation
if (!ctx)
{
result = ERR_get_error();
printf("EVP_PKEY_CTX_new error: %s\n", ERR_error_string(result, NULL));
goto clear;
}
if (EVP_PKEY_CTX_set_rsa_padding(ctx, RSA_PKCS1_PADDING) <= 0)
{
result = ERR_get_error();
printf("EVP_PKEY_CTX_set_rsa_padding error: %s\n", ERR_error_string(result, NULL));
goto clear;
}
if (EVP_PKEY_CTX_set_signature_md(ctx, EVP_sha256()) <= 0)
{
result = ERR_get_error();
printf("EVP_PKEY_CTX_set_signature_md error: %s\n", ERR_error_string(result, NULL));
goto clear;
}
/* Determine buffer length */
if (EVP_PKEY_sign(ctx, NULL, sigSize, msg, msgSize) <= 0)
{
result = ERR_get_error();
printf("EVP_PKEY_sign error: %s\n", ERR_error_string(result, NULL));
goto clear;
}
*sig = OPENSSL_malloc(sigSize);
if (*sig == NULL)
{
result = ERR_get_error();
printf("OPENSSL_malloc error: %s\n", ERR_error_string(result, NULL));
goto clear;
}
if (EVP_PKEY_sign(ctx, *sig, sigSize, msg, msgSize) <= 0)
{
OPENSSL_free(*sig);
result = ERR_get_error();
printf("OPENSSL_malloc error: %s\n", ERR_error_string(result, NULL));
goto clear;
}
clear:
if (ctx)
{
EVP_PKEY_CTX_free(ctx);
}
return result;
}__FILE__ This macro expands to the name of the current input file, in the form of a C string constant. This is the path by which the preprocessor opened the file, not the short name specified in ‘#include’ or as the input file name argument. For example, "/usr/local/include/myheader.h" is a possible expansion of this macro.而我遇到的恰恰是在eclipse里得到的是相对路径而非绝对路径,经过一些探查我发现这个宏的定义实际上是makefile在传递给gcc的时候的代码文件名,也就是说传递给gcc的参数而已,所以,eclipse通过一个一致性的makefile的设置导致传递给gcc的../src/src.c这样的文件名,所以,我的代码里也就获得了这样的__FILE__的值。
二月七日 等待变化等待机会
我花了两天时间才开始意识到我也同样的被文档所误导,没有意识到EVP_PKEY_sign的传入参数不是用户的数据而是它的digest,这个实际上对于熟悉加密算法的人其实是显而易见的,所以,我犯了这个错误只能证明我的无知,当然对于与我犯了相似错误的人没有任何的不敬的意思,我只是对于自己的不满而已。其实那位同道所领悟的远远比我多。二月八日 等待变化等待机会
/*
* digestTest.c
*
* Created on: Feb 7, 2018
* Author: nick
*/
/*
============================================================================
Name : keyGenTest.c
Author : Nick Huang
Version : 1.0
Copyright : Your copyright notice
Description : Hello World in C, Ansi-style
============================================================================
*/
#include <stdio.h>
#include <stdlib.h>
#include <openssl/evp.h>
#include <openssl/rsa.h>
#include <openssl/err.h>
#include <openssl/bio.h>
#define HANDLE_ERR(func)\
printf("%s: %s\n", #func, ERR_reason_error_string(ERR_get_error())); result = -1; goto clear;
/* Bogus key and IV: we'd normally set these from
* another source.
*/
unsigned char key[EVP_MAX_KEY_LENGTH] = "01234567890123456789012345678901";
unsigned char iv[EVP_MAX_IV_LENGTH] = "0123456789012345";
#define CIPHER EVP_aes_256_cbc()[1]
const char* StrPrivateKeyFileName="privateKey.pem";
const char* StrPublicKeyFileName="publicKey.pem";
const char* StrPrivateKeyTextFileName="privateKey.txt";
const char* StrPublicKeyTextFileName="publicKey.txt";
const char* StrParamTextFileName="param.txt";
const char* StrCipherFileName="cipher.txt";
const char* StrPlainFileName="plain.txt";
int printBIO(const char* strCtx, BIO* bio)
{
char buffer[2048+1];
int num = 0;
printf("*******%s begins*****\n", strCtx);
while ((num = BIO_gets(bio, buffer, 2048))>0)
{
buffer[num] = '\0';
printf("%s", buffer);
}
printf("********%s ends*****\n", strCtx);
if (num < 0)
{
printf("BIO_gets error: %s\n", ERR_reason_error_string(ERR_get_error()));
return -1;
}
return 0;
}
int printKey(EVP_PKEY_CTX *ctx, EVP_PKEY *pkey)
{
int result = 0;
BIO* bio = NULL;
bio = BIO_new(BIO_s_mem());
if (bio == NULL)
{
HANDLE_ERR(BIO_new);
}
if (EVP_PKEY_print_public(bio, pkey, 1, NULL)!= 1)
{
HANDLE_ERR(EVP_PKEY_print_public);
}
if (printBIO("public key", bio) < 0)
{
HANDLE_ERR(printBIO);
}
if (EVP_PKEY_print_private(bio, pkey, 1, NULL)!= 1)
{
HANDLE_ERR(EVP_PKEY_print_private);
}
if (printBIO("private key", bio) < 0)
{
HANDLE_ERR(printBIO);
}
if (EVP_PKEY_print_params(bio, pkey, 1, NULL)!= 1)
{
HANDLE_ERR(EVP_PKEY_print_params);
}
if (printBIO("key params", bio) < 0)
{
HANDLE_ERR(printBIO);
}
clear:
if (bio)
{
BIO_free(bio);
}
return result;
}
int printKeyFile(EVP_PKEY_CTX *ctx, EVP_PKEY *pkey)
{
int result = 0;
BIO* bio = NULL;
bio = BIO_new_file(StrPublicKeyTextFileName, "w+b");
if (bio == NULL)
{
HANDLE_ERR(BIO_new);
}
if (EVP_PKEY_print_public(bio, pkey, 1, NULL)!= 1)
{
HANDLE_ERR(EVP_PKEY_print_public);
}
if (bio)
{
BIO_free(bio);
bio = NULL;
}
bio = BIO_new_file(StrPrivateKeyTextFileName, "w+b");
if (bio == NULL)
{
HANDLE_ERR(BIO_new);
}
if (EVP_PKEY_print_private(bio, pkey, 1, NULL)!= 1)
{
HANDLE_ERR(EVP_PKEY_print_private);
}
if (bio)
{
BIO_free(bio);
bio = NULL;
}
bio = BIO_new_file(StrParamTextFileName, "w+b");
if (bio == NULL)
{
HANDLE_ERR(BIO_new);
}
if (EVP_PKEY_print_params(bio, pkey, 1, NULL)!= 1)
{
HANDLE_ERR(EVP_PKEY_print_params);
}
clear:
if (bio)
{
BIO_free(bio);
}
return result;
}
int createKey(unsigned int nBits, EVP_PKEY **ppkey)
{
int result = 0;
ERR_load_crypto_strings();
EVP_PKEY_CTX *ctx = NULL;
EVP_PKEY *pkey = NULL;
pkey = EVP_PKEY_new();
if (pkey == NULL)
{
HANDLE_ERR(EVP_PKEY_new);
}
ctx = EVP_PKEY_CTX_new_id(EVP_PKEY_RSA, NULL);
if (!ctx)
{
HANDLE_ERR(EVP_PKEY_CTX_new_id);
}
if (EVP_PKEY_keygen_init(ctx) <= 0)
{
HANDLE_ERR(EVP_PKEY_keygen_init);
}
if (EVP_PKEY_CTX_set_rsa_padding(ctx, RSA_PKCS1_PADDING) <= 0)
{
HANDLE_ERR(EVP_PKEY_CTX_set_rsa_padding);
}
if (EVP_PKEY_CTX_set_rsa_keygen_bits(ctx, nBits [2]) <= 0)
{
HANDLE_ERR(EVP_PKEY_CTX_set_rsa_keygen_bits);
}
/* Generate key */
if (EVP_PKEY_keygen(ctx, &pkey) <= 0)
{
HANDLE_ERR(EVP_PKEY_keygen);
}
if (printKey(ctx, pkey) != 0)
{
HANDLE_ERR(testKey);
}
if (printKeyFile(ctx, pkey) != 0)
{
HANDLE_ERR(printKeyFile);
}
clear:
if (result == 0)
{
*ppkey = pkey;
}
else
{
EVP_PKEY_free(pkey);
}
if (ctx)
{
EVP_PKEY_CTX_free(ctx);
}
return result;
}
int encrypt(EVP_PKEY *pkey)
{
const unsigned int BufferSize = 1024;
int toEncrypt = 1;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char inbuf[BufferSize], outbuf[BufferSize + EVP_MAX_BLOCK_LENGTH];
int inlen, outlen;
FILE* in = NULL;
FILE* out = NULL;
/* Don't set key or IV because we will modify the parameters */
EVP_CIPHER_CTX ctx;
in = fopen(__FILE__, "r+b");
if (in == NULL)
{
HANDLE_ERR(fopen);
}
out = fopen(StrCipherFileName, "w+b");
if (out == NULL)
{
HANDLE_ERR(fopen);
}
EVP_CIPHER_CTX_init(&ctx);
if (EVP_CipherInit_ex(&ctx, CIPHER, NULL, NULL, NULL, toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
if (EVP_CIPHER_CTX_set_key_length(&ctx, EVP_CIPHER_key_length(CIPHER)) <= 0)
{
HANDLE_ERR(EVP_CIPHER_CTX_set_key_length);
}
/* We finished modifying parameters so now we can set key and IV */
if (EVP_CipherInit_ex(&ctx, NULL, NULL, key, iv, toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
printf("Length of the key is %d\n",EVP_CIPHER_key_length(CIPHER));
printf("Length of the IV is %d\n",EVP_CIPHER_CTX_iv_length(&ctx));
for(;;)
{
inlen = fread(inbuf, 1, BufferSize, in);
if(inlen <= 0)
{
break;
}
if(EVP_CipherUpdate(&ctx, outbuf, &outlen, inbuf, inlen) <= 0)
{
HANDLE_ERR(EVP_CipherUpdate);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
}
outlen = EVP_MAX_BLOCK_LENGTH;[3]
if(EVP_CipherFinal_ex(&ctx, outbuf, &outlen) <= 0)
{
HANDLE_ERR(EVP_CipherFinal_ex);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
clear:
EVP_CIPHER_CTX_cleanup(&ctx);
if (in)
{
fclose(in);
}
if (out)
{
fclose(out);
}
return result;
}
int decrypt(EVP_PKEY *pkey)
{
const unsigned int BufferSize = 1024;
int toEncrypt = 0;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char inbuf[BufferSize], outbuf[BufferSize + EVP_MAX_BLOCK_LENGTH];
int inlen, outlen;
FILE* in = NULL;
FILE* out = NULL;
/* Don't set key or IV because we will modify the parameters */
EVP_CIPHER_CTX ctx;
in = fopen(StrCipherFileName, "r+b");
if (in == NULL)
{
HANDLE_ERR(fopen);
}
out = fopen(StrPlainFileName, "w+b");
if (out == NULL)
{
HANDLE_ERR(fopen);
}
EVP_CIPHER_CTX_init(&ctx);
if (EVP_CipherInit_ex(&ctx, CIPHER, NULL, NULL, NULL, toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
if (EVP_CIPHER_CTX_set_key_length(&ctx, EVP_CIPHER_key_length(CIPHER)) <= 0)
{
HANDLE_ERR(EVP_CIPHER_CTX_set_key_length);
}
/* We finished modifying parameters so now we can set key and IV */
if (EVP_CipherInit_ex(&ctx, NULL, NULL, key, iv, toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
printf("Length of the key is %d\n",EVP_CIPHER_key_length(CIPHER));
printf("Length of the IV is %d\n",EVP_CIPHER_CTX_iv_length(&ctx));
for(;;)
{
inlen = fread(inbuf, 1, BufferSize, in);
if(inlen <= 0)
{
break;
}
if(EVP_CipherUpdate(&ctx, outbuf, &outlen, inbuf, inlen) <= 0)
{
HANDLE_ERR(EVP_CipherUpdate);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
}
outlen = EVP_MAX_BLOCK_LENGTH;[3]
if(EVP_CipherFinal_ex(&ctx, outbuf, &outlen) <= 0)
{
HANDLE_ERR(EVP_CipherFinal_ex);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
clear:
EVP_CIPHER_CTX_cleanup(&ctx);
if (in)
{
fclose(in);
}
if (out)
{
fclose(out);
}
return result;
}
int verify()
{
const unsigned int BufferSize = 1024;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char inbuf[BufferSize], outbuf[BufferSize];
int inlen, outlen;
FILE* in = NULL;
FILE* out = NULL;
in = fopen(__FILE__, "r+b");
if (in == NULL)
{
HANDLE_ERR(fopen);
}
out = fopen(StrPlainFileName, "r+b");
if (out == NULL)
{
HANDLE_ERR(fopen);
}
for(;;)
{
inlen = fread(inbuf, 1, BufferSize, in);
outlen =fread(outbuf, 1, BufferSize, out);
if (inlen != outlen)
{
HANDLE_ERR(EVP_CipherFinal_ex);
}
if (inlen == 0)
{
break;
}
if (memcmp(inbuf, outbuf, inlen) != 0)
{
HANDLE_ERR(memcmp);
}
}
clear:
if (in)
{
fclose(in);
}
if (out)
{
fclose(out);
}
return result;
}
int saveKey(EVP_PKEY *pkey)
{
int result = 0;
FILE* fp = NULL;
fp = fopen(StrPublicKeyFileName, "w+b");
if (fp == NULL)
{
HANDLE_ERR(fopen);
}
if (PEM_write_PUBKEY(fp, pkey) <= 0)
{
HANDLE_ERR(PEM_write_PUBKEY);
}
fclose(fp);
fp = NULL;
fp = fopen(StrPrivateKeyFileName, "w+b");
if (fp == NULL)
{
HANDLE_ERR(fopen);
}
if (PEM_write_PrivateKey(fp, pkey, NULL, NULL, 0, NULL, NULL) <= 0)
{
HANDLE_ERR(PEM_write_PrivateKey);
}
fclose(fp);
fp = NULL;
clear:
if (fp != NULL)
{
fclose(fp);
}
return result;
}
int loadKey(EVP_PKEY **ppkey)
{
int result = 0;
FILE* fp = NULL;
fp = fopen(StrPublicKeyFileName, "r+b");
if (fp == NULL)
{
HANDLE_ERR(fopen);
}
if (PEM_read_PUBKEY(fp, ppkey, NULL, NULL) == NULL)
{
HANDLE_ERR(PEM_read_PUBKEY);
}
fclose(fp);
fp = NULL;
fp = fopen(StrPrivateKeyFileName, "r+b");
if (fp == NULL)
{
HANDLE_ERR(fopen);
}
if (PEM_read_PrivateKey(fp, ppkey, NULL, NULL) == NULL)
{
HANDLE_ERR(PEM_read_PrivateKey);
}
fclose(fp);
fp = NULL;
clear:
if (fp != NULL)
{
fclose(fp);
}
return result;
}
int main()
{
EVP_PKEY *pkey = NULL;
if (createKey(2048, &pkey) == 0)
{
printf("createKey succeeds!\n");
if (encrypt(pkey) == 0)
{
printf("1. encrypt succeeds\n");
if (decrypt(pkey) == 0)
{
printf("1. decrypt succeeds\n");
if (verify() == 0)
{
printf("1. verify succeeds\n");
}
}
}
if (saveKey(pkey) == 0)
{
EVP_PKEY_free(pkey);
pkey = NULL;
printf("saveKey succeeds\n");
if (loadKey(&pkey) == 0)
{
printf("loadKey succeeds\n");
if (encrypt(pkey) == 0)
{
printf("2. encrypt succeeds\n");
if (decrypt(pkey) == 0)
{
printf("2. decrypt succeeds\n");
if (verify() == 0)
{
printf("2. verify succeeds\n");
}
}
}
}
}
OPENSSL_free(pkey);
}
return 0;
}
The content of the RSA private key is as follows:
-----BEGIN RSA PRIVATE KEY-----
RSAPrivateKey ::= SEQUENCE {
version Version,
modulus INTEGER, -- n
publicExponent INTEGER, -- e
privateExponent INTEGER, -- d
prime1 INTEGER, -- p
prime2 INTEGER, -- q
exponent1 INTEGER, -- d mod (p-1)
exponent2 INTEGER, -- d mod (q-1)
coefficient INTEGER, -- (inverse of q) mod p
otherPrimeInfos OtherPrimeInfos OPTIONAL
}
-----END RSA PRIVATE KEY-----
while a RSA public key contains only the following data:
-----BEGIN RSA PUBLIC KEY-----
RSAPublicKey ::= SEQUENCE {
modulus INTEGER, -- n
publicExponent INTEGER -- e
}
-----END RSA PUBLIC KEY-----
and this explains why the private key block is larger.
Note that a more standard format for non-RSA public keys is
-----BEGIN PUBLIC KEY-----
PublicKeyInfo ::= SEQUENCE {
algorithm AlgorithmIdentifier,
PublicKey BIT STRING
}
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parameters ANY DEFINED BY algorithm OPTIONAL
}
-----END PUBLIC KEY-----二月十二日 等待变化等待机会
#include <openssl/err.h>
#include <openssl/ssl.h>
#define HANDLE_ERR(func)\
printf("%s: %s\n", #func, ERR_reason_error_string(ERR_get_error())); goto clear;
int main()
{
SSL_CTX *ctx=NULL;
const SSL_METHOD *meth=SSLv3_client_method();<[2]
BIO *STDout=NULL;
SSL *ssl=NULL;
SSL_load_error_strings();
OpenSSL_add_ssl_algorithms();
ctx=SSL_CTX_new(meth);
if (ctx == NULL)
{
HANDLE_ERR(SSL_CTX_new);
}
ssl=SSL_new(ctx);
if (ssl == NULL)
{
HANDLE_ERR(SSL_new);
}
STDout=BIO_new_fp(stdout,BIO_NOCLOSE);
if (STDout == NULL)
{
HANDLE_ERR(BIO_new_fp);
}
for (int i=0; ; i++)
{
SSL_CIPHER *c = NULL;
STACK_OF(SSL_CIPHER) *sk = NULL;
sk = SSL_get_ciphers(ssl);
if ((sk == NULL) || (sk_SSL_CIPHER_num(sk) <= i))
{
BIO_printf(STDout,"number %d invalid\n", i);
break;
}
c=sk_SSL_CIPHER_value(sk,i);
if (c != NULL)
{
BIO_printf(STDout,"number[%d]:%s [%lu] [%s] [%d]\n", i, SSL_CIPHER_get_name(c),
SSL_CIPHER_get_id(c),
SSL_CIPHER_get_version(c),
SSL_CIPHER_get_bits(c, NULL));
const EVP_CIPHER* evp_cipher = EVP_get_cipherbynid(SSL_CIPHER_get_id(c));[1]
if (evp_cipher)
{
BIO_printf(STDout, "name:[%s];nid:[%d];key:[%d];iv:[%d];block:[%d];flags:[%lu];",
EVP_CIPHER_name(evp_cipher),
EVP_CIPHER_nid(evp_cipher),
EVP_CIPHER_key_length(evp_cipher),
EVP_CIPHER_iv_length(evp_cipher),
EVP_CIPHER_block_size(evp_cipher),
EVP_CIPHER_flags(evp_cipher));
}
}
else
{
break;
}
}
BIO_printf(STDout,"\n");
clear:
if (ctx)
{
SSL_CTX_free(ctx);
}
if (STDout)
{
BIO_free(STDout);
}
if (ssl)
{
SSL_free(ssl);
}
return 0;
}
number[0]:ECDHE-RSA-AES256-GCM-SHA384 [50380848] [TLSv1/SSLv3] [256]
number[1]:ECDHE-ECDSA-AES256-GCM-SHA384 [50380844] [TLSv1/SSLv3] [256]
number[2]:ECDHE-RSA-AES256-SHA384 [50380840] [TLSv1/SSLv3] [256]
number[3]:ECDHE-ECDSA-AES256-SHA384 [50380836] [TLSv1/SSLv3] [256]
number[4]:ECDHE-RSA-AES256-SHA [50380820] [TLSv1/SSLv3] [256]
number[5]:ECDHE-ECDSA-AES256-SHA [50380810] [TLSv1/SSLv3] [256]
number[6]:SRP-DSS-AES-256-CBC-SHA [50380834] [TLSv1/SSLv3] [256]
number[7]:SRP-RSA-AES-256-CBC-SHA [50380833] [TLSv1/SSLv3] [256]
number[8]:DHE-DSS-AES256-GCM-SHA384 [50331811] [TLSv1/SSLv3] [256]
number[9]:DHE-RSA-AES256-GCM-SHA384 [50331807] [TLSv1/SSLv3] [256]
number[10]:DHE-RSA-AES256-SHA256 [50331755] [TLSv1/SSLv3] [256]
number[11]:DHE-DSS-AES256-SHA256 [50331754] [TLSv1/SSLv3] [256]
number[12]:DHE-RSA-AES256-SHA [50331705] [TLSv1/SSLv3] [256]
number[13]:DHE-DSS-AES256-SHA [50331704] [TLSv1/SSLv3] [256]
number[14]:DHE-RSA-CAMELLIA256-SHA [50331784] [TLSv1/SSLv3] [256]
number[15]:DHE-DSS-CAMELLIA256-SHA [50331783] [TLSv1/SSLv3] [256]
number[16]:ECDH-RSA-AES256-GCM-SHA384 [50380850] [TLSv1/SSLv3] [256]
number[17]:ECDH-ECDSA-AES256-GCM-SHA384 [50380846] [TLSv1/SSLv3] [256]
number[18]:ECDH-RSA-AES256-SHA384 [50380842] [TLSv1/SSLv3] [256]
number[19]:ECDH-ECDSA-AES256-SHA384 [50380838] [TLSv1/SSLv3] [256]
number[20]:ECDH-RSA-AES256-SHA [50380815] [TLSv1/SSLv3] [256]
number[21]:ECDH-ECDSA-AES256-SHA [50380805] [TLSv1/SSLv3] [256]
number[22]:AES256-GCM-SHA384 [50331805] [TLSv1/SSLv3] [256]
number[23]:AES256-SHA256 [50331709] [TLSv1/SSLv3] [256]
number[24]:AES256-SHA [50331701] [TLSv1/SSLv3] [256]
number[25]:CAMELLIA256-SHA [50331780] [TLSv1/SSLv3] [256]
number[26]:PSK-AES256-CBC-SHA [50331789] [TLSv1/SSLv3] [256]
number[27]:ECDHE-RSA-DES-CBC3-SHA [50380818] [TLSv1/SSLv3] [168]
number[28]:ECDHE-ECDSA-DES-CBC3-SHA [50380808] [TLSv1/SSLv3] [168]
number[29]:SRP-DSS-3DES-EDE-CBC-SHA [50380828] [TLSv1/SSLv3] [168]
number[30]:SRP-RSA-3DES-EDE-CBC-SHA [50380827] [TLSv1/SSLv3] [168]
number[31]:EDH-RSA-DES-CBC3-SHA [50331670] [TLSv1/SSLv3] [168]
number[32]:EDH-DSS-DES-CBC3-SHA [50331667] [TLSv1/SSLv3] [168]
number[33]:ECDH-RSA-DES-CBC3-SHA [50380813] [TLSv1/SSLv3] [168]
number[34]:ECDH-ECDSA-DES-CBC3-SHA [50380803] [TLSv1/SSLv3] [168]
number[35]:DES-CBC3-SHA [50331658] [TLSv1/SSLv3] [168]
number[36]:PSK-3DES-EDE-CBC-SHA [50331787] [TLSv1/SSLv3] [168]
number[37]:ECDHE-RSA-AES128-GCM-SHA256 [50380847] [TLSv1/SSLv3] [128]
number[38]:ECDHE-ECDSA-AES128-GCM-SHA256 [50380843] [TLSv1/SSLv3] [128]
number[39]:ECDHE-RSA-AES128-SHA256 [50380839] [TLSv1/SSLv3] [128]
number[40]:ECDHE-ECDSA-AES128-SHA256 [50380835] [TLSv1/SSLv3] [128]
number[41]:ECDHE-RSA-AES128-SHA [50380819] [TLSv1/SSLv3] [128]
number[42]:ECDHE-ECDSA-AES128-SHA [50380809] [TLSv1/SSLv3] [128]
number[43]:SRP-DSS-AES-128-CBC-SHA [50380831] [TLSv1/SSLv3] [128]
number[44]:SRP-RSA-AES-128-CBC-SHA [50380830] [TLSv1/SSLv3] [128]
number[45]:DHE-DSS-AES128-GCM-SHA256 [50331810] [TLSv1/SSLv3] [128]
number[46]:DHE-RSA-AES128-GCM-SHA256 [50331806] [TLSv1/SSLv3] [128]
number[47]:DHE-RSA-AES128-SHA256 [50331751] [TLSv1/SSLv3] [128]
number[48]:DHE-DSS-AES128-SHA256 [50331712] [TLSv1/SSLv3] [128]
number[49]:DHE-RSA-AES128-SHA [50331699] [TLSv1/SSLv3] [128]
number[50]:DHE-DSS-AES128-SHA [50331698] [TLSv1/SSLv3] [128]
number[51]:DHE-RSA-SEED-SHA [50331802] [TLSv1/SSLv3] [128]
number[52]:DHE-DSS-SEED-SHA [50331801] [TLSv1/SSLv3] [128]
number[53]:DHE-RSA-CAMELLIA128-SHA [50331717] [TLSv1/SSLv3] [128]
number[54]:DHE-DSS-CAMELLIA128-SHA [50331716] [TLSv1/SSLv3] [128]
number[55]:ECDH-RSA-AES128-GCM-SHA256 [50380849] [TLSv1/SSLv3] [128]
number[56]:ECDH-ECDSA-AES128-GCM-SHA256 [50380845] [TLSv1/SSLv3] [128]
number[57]:ECDH-RSA-AES128-SHA256 [50380841] [TLSv1/SSLv3] [128]
number[58]:ECDH-ECDSA-AES128-SHA256 [50380837] [TLSv1/SSLv3] [128]
number[59]:ECDH-RSA-AES128-SHA [50380814] [TLSv1/SSLv3] [128]
number[60]:ECDH-ECDSA-AES128-SHA [50380804] [TLSv1/SSLv3] [128]
number[61]:AES128-GCM-SHA256 [50331804] [TLSv1/SSLv3] [128]
number[62]:AES128-SHA256 [50331708] [TLSv1/SSLv3] [128]
number[63]:AES128-SHA [50331695] [TLSv1/SSLv3] [128]
number[64]:SEED-SHA [50331798] [TLSv1/SSLv3] [128]
number[65]:CAMELLIA128-SHA [50331713] [TLSv1/SSLv3] [128]
number[66]:PSK-AES128-CBC-SHA [50331788] [TLSv1/SSLv3] [128]
number[67]:ECDHE-RSA-RC4-SHA [50380817] [TLSv1/SSLv3] [128]
number[68]:ECDHE-ECDSA-RC4-SHA [50380807] [TLSv1/SSLv3] [128]
number[69]:ECDH-RSA-RC4-SHA [50380812] [TLSv1/SSLv3] [128]
number[70]:ECDH-ECDSA-RC4-SHA [50380802] [TLSv1/SSLv3] [128]
number[71]:RC4-SHA [50331653] [TLSv1/SSLv3] [128]
number[72]:RC4-MD5 [50331652] [TLSv1/SSLv3] [128]
number[73]:PSK-RC4-SHA [50331786] [TLSv1/SSLv3] [128]
number[74]:EDH-RSA-DES-CBC-SHA [50331669] [TLSv1/SSLv3] [56]
number[75]:EDH-DSS-DES-CBC-SHA [50331666] [TLSv1/SSLv3] [56]
number[76]:DES-CBC-SHA [50331657] [TLSv1/SSLv3] [56]
number[77]:EXP-EDH-RSA-DES-CBC-SHA [50331668] [TLSv1/SSLv3] [40]
number[78]:EXP-EDH-DSS-DES-CBC-SHA [50331665] [TLSv1/SSLv3] [40]
number[79]:EXP-DES-CBC-SHA [50331656] [TLSv1/SSLv3] [40]
number[80]:EXP-RC2-CBC-MD5 [50331654] [TLSv1/SSLv3] [40]
number[81]:EXP-RC4-MD5 [50331651] [TLSv1/SSLv3] [40]
number 82 invalid二月十三日 等待变化等待机会
我可能又忘记了这个语法,就是cifs的路径形式:mount -t cifs -o,user=myuser,password=mypasswd //172.17.245.230/repository repositary二月十四日 等待变化等待机会
我花了差不多两天时间在寻找ssl_cipher和EVP_cipher之间的关联,或者说在寻找两个体系遍历的方式。前者有现成的函数,而后者我花了很久才google到,然后就忘了存那个链接于是这个就无耻的成了我自己的成果了。不过我依稀记得原来作者提到这段小代码是在原来openssl里的一段,实在是不值一提了。
static void show_ciphers(const OBJ_NAME *name,void *bio_)
{
BIO *bio=bio_;
if (islower(name->name[0]) || name->alias)[2]
{
//printf("alias: %s\n", name->name);
}
else
{
BIO_printf(bio,"%s\n",name->name);
}
}
void collectCipherName()
{
OpenSSL_add_all_algorithms();
BIO* bio = BIO_new(BIO_s_mem());
OBJ_NAME_do_all_sorted(OBJ_NAME_TYPE_CIPHER_METH,
show_ciphers,
bio);
char *bptr = NULL;
int size = BIO_get_mem_data(bio, &bptr);
BIO_set_close(bio, BIO_NOCLOSE);[1]
printf("[%d]\n", size);
printf("%s\n", bptr);
BIO_free(bio);
}
AES128
AES192
AES256
BF
CAMELLIA128
CAMELLIA192
CAMELLIA256
CAST
CAST-cbc
DES
DES3
DESX
RC2
SEED
aes128
aes192
aes256
bf
blowfish
camellia128
camellia192
camellia256
cast
cast-cbc
des
des3
desx
rc2
seed
AES-128-CBC
AES-128-CBC-HMAC-SHA1
AES-128-CFB
AES-128-CFB1
AES-128-CFB8
AES-128-CTR
AES-128-ECB
AES-128-OFB
AES-128-XTS
AES-192-CBC
AES-192-CFB
AES-192-CFB1
AES-192-CFB8
AES-192-CTR
AES-192-ECB
AES-192-OFB
AES-256-CBC
AES-256-CBC-HMAC-SHA1
AES-256-CFB
AES-256-CFB1
AES-256-CFB8
AES-256-CTR
AES-256-ECB
AES-256-OFB
AES-256-XTS
BF-CBC
BF-CFB
BF-ECB
BF-OFB
CAMELLIA-128-CBC
CAMELLIA-128-CFB
CAMELLIA-128-CFB1
CAMELLIA-128-CFB8
CAMELLIA-128-ECB
CAMELLIA-128-OFB
CAMELLIA-192-CBC
CAMELLIA-192-CFB
CAMELLIA-192-CFB1
CAMELLIA-192-CFB8
CAMELLIA-192-ECB
CAMELLIA-192-OFB
CAMELLIA-256-CBC
CAMELLIA-256-CFB
CAMELLIA-256-CFB1
CAMELLIA-256-CFB8
CAMELLIA-256-ECB
CAMELLIA-256-OFB
CAST5-CBC
CAST5-CFB
CAST5-ECB
CAST5-OFB
DES-CBC
DES-CFB
DES-CFB1
DES-CFB8
DES-ECB
DES-EDE
DES-EDE-CBC
DES-EDE-CFB
DES-EDE-OFB
DES-EDE3
DES-EDE3-CBC
DES-EDE3-CFB
DES-EDE3-CFB1
DES-EDE3-CFB8
DES-EDE3-OFB
DES-OFB
DESX-CBC
RC2-40-CBC
RC2-64-CBC
RC2-CBC
RC2-CFB
RC2-ECB
RC2-OFB
RC4
RC4-40
RC4-HMAC-MD5
SEED-CBC
SEED-CFB
SEED-ECB
SEED-OFB二月十五日 等待变化等待机会
我的网络完全碎片化了,因为motorola的cable modem自带无线路由和switch功能,但是它的两个wifi都是在不同的子网里的,而我原来的两个路由器通过交换机连进网络后也只能在自己的子网,于是我不知道怎样才能访问我的扫描仪了。不过使用nmap -sn 192.168.1.0/24扫描我又找到了原来的NAS在192.168.1.6,为什么会这样呢?我猜想是我之前把synalogy的这个nas设定为固定ip,结果它就只有在192.168.1.x的这个子网内,而我的新cable modem只能够在192.168.0.1,因为其中的一个它自带的wifi在192.168.1.1,结果这个nas就只能在自己的子网里重新分配ip?总之我不是很明白怎么发生的。nmap的/24是256个ip的意思,我照猫画虎使用/16导致65536个ip去扫描。无意中发现主机的另一个网卡被分配到192.168.1.6结果我以前设置的micro_httpd居然还在工作。这个设置其实很简单直接follow它的manpage,在/etc/inetd.conf和/etc/services里各自加一行,不过要注意就是它只会找index.html的文件。为了重新启动inetd我不得不下载了inetutils-inetd。我的/etc/inetd.conf增加了一行:micro-http stream tcp nowait nick /usr/sbin/micro-httpd micro-httpd /BigDisk/diabloforum/public_html同样的在/etc/services里增加了一行:
micro-http 80/tcp重启inetd使用inetutils-inetd这个服务。
二月十七日 等待变化等待机会
我整整花了一整天时间在寻找加密操作错误的原因,最后真的是头昏脑胀的恶心的受不了了。结果还是没有完全解决,不过我已经至少缩小了范围,就是说这三个算法我的程序肯定是不完善:"AES-128-CBC-HMAC-SHA1", "AES-256-CBC-HMAC-SHA1", "DES-EDE3-CFB1",具体的原因我打算重点的debug,也许自己编译openssl的debug版本跟踪一下吧。这里是一个比较稳定的版本,其实和之前的做法差别不大,就是说完善了一些的小的细节,比如比对文件就是比较原文和解密后的文件时候其实很罗嗦的,因为你不能因为两个文件的fread指定读取的字节数返回不同就武断说两个文件不同,因为,fread的返回字节数其实已经是有内部缓存了,还有很多的情况要处理,写起来麻烦,所以,我就直接使用diff了,因为我只关心一个yes/no的结果而已。
#include <openssl/err.h>
#include <openssl/ssl.h>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <cctype>
#include <iostream>
#include <vector>
#include <string>
using namespace std;
#define HANDLE_ERR(func)\
printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error())); result = -1; goto clear;
static void collect_ciphers(const OBJ_NAME *name,void *vect)
{
vector<string>* pvect = (vector<string>*) vect;
if (islower(name->name[0]) || name->alias)
{
//printf("%s\n", name->name);
}
else
{
pvect->push_back(name->name);
}
}
void collectCipherName(vector<string>& vect)
{
OBJ_NAME_do_all_sorted(OBJ_NAME_TYPE_CIPHER_METH,
collect_ciphers,
&vect);
}
int encrypt(const string& strName, const EVP_CIPHER* cipher, string& strKey, string& strIV)
{
const unsigned int BufferSize = 1024;
int toEncrypt = 1;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char inbuf[BufferSize], outbuf[BufferSize + EVP_MAX_BLOCK_LENGTH];
int inlen, outlen;
FILE* in = NULL;
FILE* out = NULL;
/* Don't set key or IV because we will modify the parameters */
EVP_CIPHER_CTX ctx;
int keyLength = 0;
int ivLength = 0;
const string strFileName = "/tmp/" + strName;
in = fopen(__FILE__, "r");
if (in == NULL)
{
HANDLE_ERR(fopen);
}
out = fopen(strFileName.c_str(), "w");
if (out == NULL)
{
HANDLE_ERR(fopen);
}
EVP_CIPHER_CTX_init(&ctx);
if (EVP_CipherInit_ex(&ctx, cipher, NULL, NULL, NULL, toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
if (EVP_CIPHER_CTX_set_key_length(&ctx, EVP_CIPHER_key_length(cipher)) <= 0)
{
HANDLE_ERR(EVP_CIPHER_CTX_set_key_length);
}
// let's randomize key and iv
keyLength = EVP_CIPHER_key_length(cipher);
strKey.resize(keyLength);
for (int i = 0; i < keyLength; i ++)
{
strKey[i] = random()%2==1?random()%26 + 'A':random()%26 + 'a';
}
ivLength = EVP_CIPHER_CTX_iv_length(&ctx);
strIV.resize(ivLength);
for (int i = 0; i < ivLength; i ++)
{
strIV[i] = random()%2==1?random()%26 + 'A':random()%26 + 'a';
}
/* We finished modifying parameters so now we can set key and IV */
if (EVP_CipherInit_ex(&ctx, NULL, NULL, (const unsigned char*)strKey.c_str(), (const unsigned char*)strIV.c_str(), toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
while (!ferror(in))
{
inlen = fread(inbuf, 1, BufferSize, in);
if(inlen <= 0)
{
if (feof(in))
{
break;
}
}
else
{
if(EVP_CipherUpdate(&ctx, outbuf, &outlen, inbuf, inlen) <= 0)
{
HANDLE_ERR(EVP_CipherUpdate);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
}
}
if (ferror(in))
{
HANDLE_ERR(ferror);
}
if(EVP_CipherFinal_ex(&ctx, outbuf, &outlen) <= 0)
{
HANDLE_ERR(EVP_CipherFinal_ex);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
clear:
EVP_CIPHER_CTX_cleanup(&ctx);
if (in)
{
fclose(in);
}
if (out)
{
fclose(out);
}
fflush(NULL);
return result;
}
int verify(const string& src, const string& tgt)
{
string cmd = "diff -q " + src + " " + tgt;
int ret = system(cmd.c_str());
return WEXITSTATUS(ret);
}
int decrypt(const string& strCipherName, const EVP_CIPHER* cipher, const string& strKey, const string& strIV)
{
const unsigned int BufferSize = 1024;
int toEncrypt = 0;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char inbuf[BufferSize], outbuf[BufferSize + EVP_MAX_BLOCK_LENGTH];
int inlen, outlen;
int tmpOut = 0, tmpTotal = 0;
FILE* in = NULL;
FILE* out = NULL;
/* Don't set key or IV because we will modify the parameters */
EVP_CIPHER_CTX ctx;
const string strPlainName = "/tmp/" + strCipherName + ".txt";
const string strCipherFileName = "/tmp/"+strCipherName;
in = fopen(strCipherFileName.c_str(), "r");
if (in == NULL)
{
HANDLE_ERR(fopen);
}
out = fopen(strPlainName.c_str(), "w");
if (out == NULL)
{
HANDLE_ERR(fopen);
}
EVP_CIPHER_CTX_init(&ctx);
if (EVP_CipherInit_ex(&ctx, cipher, NULL, NULL, NULL, toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
if (EVP_CIPHER_CTX_set_key_length(&ctx, EVP_CIPHER_key_length(cipher)) <= 0)
{
HANDLE_ERR(EVP_CIPHER_CTX_set_key_length);
}
/* We finished modifying parameters so now we can set key and IV */
if (EVP_CipherInit_ex(&ctx, NULL, NULL, (const unsigned char*)strKey.c_str(),
(const unsigned char*)strIV.c_str(),
toEncrypt) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
while (!ferror(in) && !ferror(out))
{
inlen = fread(inbuf, 1, BufferSize, in);
if(inlen <= 0)
{
if (feof(in))
{
break;
}
}
else
{
if(EVP_CipherUpdate(&ctx, outbuf, &outlen, inbuf, inlen) <= 0)
{
HANDLE_ERR(EVP_CipherUpdate);
}
tmpTotal = 0;
while (tmpTotal < outlen)
{
tmpOut = fwrite(outbuf, 1, outlen, out);
if (tmpOut <= 0)
{
HANDLE_ERR(fwrite);
}
else
{
tmpTotal+= tmpOut;
outlen -= tmpOut;
}
}
}
}
if (ferror(in) && ferror(out))
{
HANDLE_ERR(ferror);
}
if(EVP_CipherFinal_ex(&ctx, outbuf, &outlen) <= 0)
{
HANDLE_ERR(EVP_CipherFinal_ex);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
fflush(in);
fflush(out);
if (verify(__FILE__, strPlainName) != 0)
{
HANDLE_ERR(verify);
}
clear:
EVP_CIPHER_CTX_cleanup(&ctx);
if (in)
{
fclose(in);
}
if (out)
{
fclose(out);
}
return result;
}
int main()
{
OpenSSL_add_all_algorithms();
vector<string> vect;
collectCipherName(vect);
for (size_t i = 0; i < vect.size(); i ++)
{
if (vect[i].compare("AES-128-CBC-HMAC-SHA1") == 0
|| vect[i].compare("AES-256-CBC-HMAC-SHA1") == 0
|| vect[i].compare("DES-EDE3-CFB1") == 0)
{
continue;
}
const EVP_CIPHER* cipher = EVP_get_cipherbyname(vect[i].c_str());
if (cipher)
{
string strKey, strIV;
if (encrypt(vect[i], cipher, strKey, strIV) == 0)
{
cout << "encrypt method " << vect[i] << " succeeded " << endl;
if (decrypt(vect[i], cipher, strKey, strIV) == 0)
{
cout << "decrypt method " << vect[i] << " succeeded " << endl;
}
else
{
cout << "decrypt method " << vect[i] << " failed " << endl;
break;
}
}
else
{
cout << "encrypt method " << vect[i] << " failed " << endl;
break;
}
}
}
return 0;
}
all:
g++ -std=c++98 -g -O0 cryptoTest.cpp -o cryptoTest -lcrypto -lssl
clean:
rm -f cryptoTest二月十八日 等待变化等待机会
这件简单的事情折腾了我许久,就是怎样编译一个openssl的静态库,同时我还想要debug build因为想要gdb看看是怎么执行的,所以,我也需要它的apps,就是openssl的binary executable。一层窗户纸捅破是不值钱的,可是我看了它的说明和wiki怎么也想不出怎么办?实际上本来是有线索的,因为我编译的静态库链接的时候总是有很多链接错误。最后我的编译命令如此:g++ -std=c++98 -g -O0 -I/BigDisk/openssl-1.0.1f/include\
cryptoTest.cpp -static -L/BigDisk/openssl-1.0.1f -lssl \
-L/BigDisk/openssl-1.0.1f -lcrypto -ldl -o cryptoTest./config -d no-shared threads -lpthread
int encrypt(const string& strName, const EVP_CIPHER* cipher, string& strKey, string& strIV)
{
const unsigned int BufferSize = 1024;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char inbuf[BufferSize], outbuf[BufferSize + EVP_MAX_BLOCK_LENGTH];
int inlen, outlen;
FILE* in = NULL;
FILE* out = NULL;
EVP_CIPHER_CTX ctx;
int keyLength = 0;
int ivLength = 0;
const string strFileName = "/tmp/" + strName;
in = fopen(__FILE__, "r");
if (in == NULL)
{
HANDLE_ERR(fopen);
}
out = fopen(strFileName.c_str(), "w");
if (out == NULL)
{
HANDLE_ERR(fopen);
}
EVP_CIPHER_CTX_init(&ctx);
// let's randomize key and iv
keyLength = EVP_CIPHER_key_length(cipher);
strKey.resize(keyLength);
for (int i = 0; i < keyLength; i ++)
{
strKey[i] = random()%2==1?random()%26 + 'A':random()%26 + 'a';
}
ivLength = EVP_CIPHER_iv_length(cipher);
strIV.resize(ivLength);
for (int i = 0; i < ivLength; i ++)
{
strIV[i] = random()%2==1?random()%26 + 'A':random()%26 + 'a';
}
if (EVP_EncryptInit(&ctx, cipher, (const unsigned char*)strKey.c_str(), (const unsigned char*)strIV.c_str()) <= 0)
{
HANDLE_ERR(EVP_CipherInit_ex);
}
while (!ferror(in))
{
inlen = fread(inbuf, 1, BufferSize, in);
if(inlen <= 0)
{
if (feof(in))
{
break;
}
}
else
{
if(EVP_EncryptUpdate(&ctx, outbuf, &outlen, inbuf, inlen) <= 0)
{
HANDLE_ERR(EVP_CipherUpdate);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
}
}
if (ferror(in))
{
HANDLE_ERR(ferror);
}
if(EVP_EncryptFinal(&ctx, outbuf, &outlen) <= 0)
{
HANDLE_ERR(EVP_CipherFinal_ex);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
clear:
EVP_CIPHER_CTX_cleanup(&ctx);
if (in)
{
fclose(in);
}
if (out)
{
fclose(out);
}
fflush(NULL);
return result;
}
int verify(const string& src, const string& tgt)
{
string cmd = "diff -q " + src + " " + tgt;
int ret = system(cmd.c_str());
return WEXITSTATUS(ret);[2]
}
int decrypt(const string& strCipherName, const EVP_CIPHER* cipher, const string& strKey, const string& strIV)
{
const unsigned int BufferSize = 1024;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char inbuf[BufferSize], outbuf[BufferSize + EVP_MAX_BLOCK_LENGTH];
int inlen, outlen;
int tmpOut = 0, tmpTotal = 0;
FILE* in = NULL;
FILE* out = NULL;
EVP_CIPHER_CTX ctx;
const string strPlainName = "/tmp/" + strCipherName + ".txt";
const string strCipherFileName = "/tmp/"+strCipherName;
in = fopen(strCipherFileName.c_str(), "r");
if (in == NULL)
{
HANDLE_ERR(fopen);
}
out = fopen(strPlainName.c_str(), "w");
if (out == NULL)
{
HANDLE_ERR(fopen);
}
EVP_CIPHER_CTX_init(&ctx);
if (EVP_DecryptInit(&ctx, cipher, (const unsigned char*)strKey.c_str(),
(const unsigned char*)strIV.c_str()) <= 0)[1]
{
HANDLE_ERR(EVP_CipherInit_ex);
}
while (!ferror(in) && !ferror(out))
{
inlen = fread(inbuf, 1, BufferSize, in);
if(inlen <= 0)
{
if (feof(in))
{
break;
}
}
else
{
if(EVP_DecryptUpdate(&ctx, outbuf, &outlen, inbuf, inlen) <= 0)
{
HANDLE_ERR(EVP_CipherUpdate);
}
tmpTotal = 0;
while (tmpTotal < outlen)
{
tmpOut = fwrite(outbuf, 1, outlen, out);
if (tmpOut <= 0)
{
HANDLE_ERR(fwrite);
}
else
{
tmpTotal+= tmpOut;
outlen -= tmpOut;
}
}
}
}
if (ferror(in) && ferror(out))
{
HANDLE_ERR(ferror);
}
if(EVP_DecryptFinal(&ctx, outbuf, &outlen) <= 0)
{
HANDLE_ERR(EVP_CipherFinal_ex);
}
if (fwrite(outbuf, 1, outlen, out) != outlen)
{
HANDLE_ERR(fwrite);
}
fflush(in);
fflush(out);
if (verify(__FILE__, strPlainName) != 0)
{
HANDLE_ERR(verify);
}
clear:
EVP_CIPHER_CTX_cleanup(&ctx);
if (in)
{
fclose(in);
}
if (out)
{
fclose(out);
}
return result;
}二月十九日 等待变化等待机会
#include <openssl/err.h>
#include <openssl/ssl.h>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <cctype>
#include <iostream>
#include <vector>
#include <string>
using namespace std;
#define HANDLE_ERR(func)\
printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error())); result = -1; goto clear;
static void collect_ciphers(const OBJ_NAME *name,void *vect)
{
vector<string>* pvect = (vector<string>*) vect;
if (islower(name->name[0]) || name->alias)
{
//printf("%s\n", name->name);
}
else
{
pvect->push_back(name->name);
}
}
void collectCipherName(vector<string>& vect)
{
OBJ_NAME_do_all_sorted(OBJ_NAME_TYPE_CIPHER_METH,
collect_ciphers,
&vect);
}
void getKey(const EVP_CIPHER* cipher, string& strKey, string& strIV)
{
int keyLength = 0;
int ivLength = 0;
// let's randomize key and iv
keyLength = EVP_CIPHER_key_length(cipher);
strKey.resize(keyLength);
for (int i = 0; i < keyLength; i ++)
{
strKey[i] = random()%2==1?random()%26 + 'A':random()%26 + 'a';
}
ivLength = EVP_CIPHER_iv_length(cipher);
strIV.resize(ivLength);
for (int i = 0; i < ivLength; i ++)
{
strIV[i] = random()%2==1?random()%26 + 'A':random()%26 + 'a';
}
}
int verify(const string& strName)
{
const string src = __FILE__;
const string tgt = "/tmp/" + strName + ".txt";;
string cmd = "diff -q " + src + " " + tgt;
int ret = system(cmd.c_str());
return WEXITSTATUS(ret);
}
int crypt(const string& strName, const EVP_CIPHER* cipher, string& strKey, string& strIV, int encrypt)
{
const unsigned int BufferSize = 8*1024;
int result = 0;
/* Allow enough space in output buffer for additional block */
unsigned char buf[EVP_ENCODE_LENGTH(BufferSize)];
int inlen, outlen;
BIO* in = NULL;
BIO* out = NULL;
BIO* benc = NULL;
EVP_CIPHER_CTX* ctx = NULL;
string strInFileName;
string strOutFileName;
if (encrypt)
{
strInFileName = __FILE__;
strOutFileName = "/tmp/" + strName;
}
else
{
strInFileName = "/tmp/" + strName;
strOutFileName = "/tmp/" + strName + ".txt";
}
in = BIO_new(BIO_s_file());
if (in == NULL)
{
HANDLE_ERR(BIO_new);
}
if (BIO_read_filename(in,(void*)strInFileName.c_str()) <= 0)
{
HANDLE_ERR(BIO_read_filename);
}
out = BIO_new(BIO_s_file());
if (out == NULL)
{
HANDLE_ERR(BIO_new);
}
if (BIO_write_filename(out, (void*)strOutFileName.c_str()) <= 0)
{
HANDLE_ERR(BIO_write_filename);
}
if ((benc = BIO_new(BIO_f_cipher())) == NULL)
{
HANDLE_ERR(BIO_new);
}
if (BIO_get_cipher_ctx(benc, &ctx) <= 0)
{
HANDLE_ERR(BIO_get_cipher_ctx);
}
if (!EVP_CipherInit_ex(ctx, cipher, NULL, NULL, NULL, encrypt))
{
HANDLE_ERR(EVP_CipherInit_ex);
}
if (!EVP_CipherInit_ex(ctx, NULL, NULL, (const unsigned char*)strKey.c_str(),
(const unsigned char*)strIV.c_str(), encrypt))
{
HANDLE_ERR(EVP_CipherInit_ex);
}
if ((out = BIO_push(benc,out)) == NULL)
{
HANDLE_ERR(BIO_push);
}
while (true)
{
inlen = BIO_read(in, (char *)buf, BufferSize);
if (inlen <= 0)
{
break;
}
if (BIO_write(out, (char *)buf, inlen) != inlen)
{
HANDLE_ERR(BIO_write);
}
}
if (!BIO_flush(out))
{
HANDLE_ERR(BIO_flush);
}
clear:
if (in)
{
BIO_free(in);
}
if (out)
{
BIO_free_all(out);
}
// if (benc)
// {
// BIO_free(benc);
// }
return result;
}
int main()
{
CRYPTO_malloc_init();
ERR_load_crypto_strings();
OpenSSL_add_all_algorithms();
vector<string> vect;
collectCipherName(vect);
for (size_t i = 0; i < vect.size(); i ++)
{
if ((vect[i].compare("AES-128-CBC-HMAC-SHA1") == 0
|| vect[i].compare("AES-256-CBC-HMAC-SHA1") == 0
|| vect[i].compare("DES-EDE3-CFB1") == 0))
{
continue;
}
const EVP_CIPHER* cipher = EVP_get_cipherbyname(vect[i].c_str());
if (cipher)
{
string strKey, strIV;
getKey(cipher, strKey, strIV);
if (crypt(vect[i], cipher, strKey, strIV, 1) == 0)
{
cout << "encrypt method " << vect[i] << " succeeded " << endl;
if (crypt(vect[i], cipher, strKey, strIV, 0) == 0)
{
cout << "decrypt method " << vect[i] << " succeeded " << endl;
if (verify(vect[i]) == 0)
{
cout << "verify method " << vect[i] << " succeeded " << endl;
}
else
{
cout << "verify method " << vect[i] << " failed " << endl;
break;
}
}
else
{
cout << "decrypt method " << vect[i] << " failed " << endl;
break;
}
}
else
{
cout << "encrypt method " << vect[i] << " failed " << endl;
break;
}
}
}
return 0;
}#include<fstream>
#include<string>
#include <cstring>
#include<ctype.h>
#include <cstdlib>
#include <iostream>
#define _TABSIZE 4
using namespace std;
int tabsize = _TABSIZE;
class token {
public:
token() : _what(code) {}
protected:
enum type {code, comment, pp, keyword};
string _str;
type _what;
friend istream& operator>>(istream&, token&);
friend ostream& operator<<(ostream&, const token&);
};
bool iskeyword(const string& s)
{
static const char* keywords[] = {
"and",
"and_eq",
"asm",
"auto",
"bitand",
"bitor",
"bool",
"break",
"case",
"catch",
"char",
"class",
"compl",
"const",
"const_cast",
"continue",
"default",
"delete",
"do",
"double",
"dynamic_cast",
"else",
"enum",
"explicit",
"export",
"extern",
"false",
"float",
"for",
"friend",
"goto",
"if",
"inline",
"int",
"long",
"mutable",
"namespace",
"new",
"not",
"not_eq",
"operator",
"or",
"or_eq",
"private",
"protected",
"public",
"register",
"reinterpret_cast",
"return",
"short",
"signed",
"sizeof",
"static",
"static_cast",
"struct",
"switch",
"template",
"this",
"throw",
"true",
"try",
"typedef",
"typeid",
"typename",
"union",
"unsigned",
"using",
"virtual",
"void",
"volatile",
"wchar_t",
"while",
"xor",
"xor_eq"
};
for (size_t i = 0; i < sizeof(keywords) / sizeof(char*); i++)
if (string(keywords[i]) == s)
return true;
return false;
}
bool containspp(const string& s)
{
static const char* pptokens[] = {
"define",
"elif",
"else",
"endif",
"error",
"if",
"ifdef",
"ifndef",
"include",
"line",
"pragma",
"undef"
};
for (size_t i = 0; i < sizeof(pptokens) / sizeof(char*); i++)
if (s.find(pptokens[i]) != string::npos)
return true;
return false;
}
istream& operator>>(istream& is, token& t)
{
t._str = "", t._what = token::code;
int c = is.get();
switch (c) {
case '/':
c = is.get();
if (c == '*') {
t._str = "/*";
t._what = token::comment;
while (1) {
c = is.get();
if (c == EOF)
return is.unget(), is.clear(), is;
if (c == '/') {
if (t._str.length() > 2 &&
t._str[t._str.length() - 1] == '*') {
return t._str += '/', is;
}
}
t._str += (char)c;
}
} else if (c == '/') {
t._str = "//";
t._what = token::comment;
c = is.get();
while (c != '\n' && c != EOF) {
t._str += (char)c;
c = is.get();
}
if (c == '\n') {
t._str += '\n';
}
return is;
}
t._str = '/';
return is.unget(), is.clear(), is;
case '#':
t._str = '#';
c = is.get();
while (strchr(" \r\n\t", c)) {
t._str += (char)c;
c = is.get();
}
if (c == EOF)
return is.unget(), is.clear(), is;
while (strchr("abcdefghijklmnopqrstuvwxyz", c)) {
t._str += (char)c;
c = is.get();
}
is.unget(), is.clear();
if (containspp(t._str))
t._what = token::pp;
return is;
case '\'':
case '"': {
char q = (char)c;
t._str = q;
while (1) {
c = is.get();
if (c == EOF)
return is.unget(), is.clear(), is;
if (c == q) {
if (t._str.length() >= 2) {
if (!(t._str[t._str.length() - 1] == '\\' &&
t._str[t._str.length() - 2] != '\\'))
return t._str += q, is;
} else {
return t._str += q, is;
}
}
t._str += (char)c;
}
}
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
case 'g':
case 'i':
case 'l':
case 'm':
case 'n':
case 'o':
case 'p':
case 'r':
case 's':
case 't':
case 'u':
case 'v':
case 'w':
case 'x':
t._str += (char)c;
c = is.get();
while (isalpha(c) || isdigit(c) || c == '_') {
t._str += (char)c;
c = is.get();
}
is.unget(), is.clear();
if (iskeyword(t._str))
t._what = token::keyword;
return is;
case EOF:
return is;
default:
t._str += (char)c;
c = is.get();
while (c != '/' && c != '#' && !strchr("abcdefgilmnoprstuvwx", c) &&
c != '\'' && c != '"' && c != EOF) {
t._str += (char)c;
c = is.get();
}
is.unget(), is.clear();
return is;
}
}
string html(const string& s)
{
string s1;
string::size_type i;
for (i = 0; i < s.length(); i++) {
switch (s[i]) {
case '&':
s1 += "&";
break;
case '<':
s1 += "<";
break;
case '>':
s1 += ">";
break;
case '"':
s1 += """;
break;
case '\t':
// I suspect this is correct for tab?
//s1.append(tabsize, ' ');
s1 += "	";
break;
default:
s1 += s[i];
}
}
return s1;
}
ostream& operator<<(ostream& os, const token& t)
{
if (t._what == token::code)
os << html(t._str);
else if (t._what == token::comment)
os << "<span class=comment>" << html(t._str) << "</span>";
else if (t._what == token::keyword)
os << "<span class=keyword>" << html(t._str) << "</span>";
else if (t._what == token::pp)
os << "<span class=pp>" << html(t._str) << "</span>";
else
os << html(t._str);
return os;
}
int main(int argc, char **argv)
{
if (argc != 2 && argc != 3) {
cout << "usage: cpphtml srcfile [tab size]" << endl;
return 0;
}
ifstream is(argv[1]);
if (!is.good()) {
cerr << "bad input file" << endl;
return -1;
}
if (argc == 3) {
tabsize = atoi(argv[2]);
if (tabsize <= 0)
tabsize = _TABSIZE;
}
// let's use htm or html ext to generate new file
string outName = argv[1];
outName += ".htm";
ofstream out(outName.c_str(), std::fstream::out);
if (!out.good())
{
cerr << "bad output file" << endl;
return -1;
}
//actually what I want is a embedded part of html, not whole file
// out << "<html><head><style>";
// out << ".keyword{color:rgb(0,0,255);}";
// out << ".comment{color:rgb(0,128,0);}";
// out << ".pp{color:rgb(0,0,255);}";
// out << "</style><body>";
out << "<pre style=\"font-family:courier;font-size:10pt\">";
token t;
while (is >> t) {
out << t;
}
//out << "</pre></body></html>";
out << "</pre>";
return 0;
}
/* * keyTest.cpp * * Created on: Feb 19, 2018 * Author: nick */ #include <openssl/ssl.h> #include <openssl/crypto.h> #include <openssl/evp.h> #include <openssl/asn1t.h> #include <openssl/err.h> #include <cstdio> #include <iostream> #include <cstring> using namespace std; int main() { OPENSSL_init(); CRYPTO_malloc_init(); ERR_load_crypto_strings(); OpenSSL_add_all_algorithms(); for (int i = 0; i < EVP_PKEY_asn1_get_count(); i++) { const EVP_PKEY_ASN1_METHOD * ameth = EVP_PKEY_asn1_get0(i); int pkeyId=0, pkeyBaseId = 0; const char* pinfo = NULL, *pstr = NULL; if (EVP_PKEY_asn1_get0_info(&pkeyId, &pkeyBaseId, NULL, &pinfo, &pstr, ameth) > 0) { pinfo = pinfo?pinfo:" none "; pstr = pstr?pstr:" none "; cout << pkeyId << "|" << pkeyBaseId << "|" << pinfo << "|" << pstr << endl; } } }
6|6|OpenSSL RSA method|RSA
19|6| none | none
28|28|OpenSSL PKCS#3 DH method|DH
66|116| none | none
67|116| none | none
70|116| none | none
113|116| none | none
116|116|OpenSSL DSA method|DSA
408|408|OpenSSL EC algorithm|EC
855|855|OpenSSL HMAC method|HMAC
894|894|OpenSSL CMAC method|CMAC二月二十日 等待变化等待机会
/* * keyTest.cpp * * Created on: Feb 19, 2018 * Author: nick */ #include <openssl/ssl.h> #include <openssl/crypto.h> #include <openssl/evp.h> #include <openssl/asn1t.h> #include <openssl/err.h> #include <cstdio> #include <iostream> #include <cstring> using namespace std; #define HANDLE_ERR(func)\ printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error())); goto clear; static int genpkey_cb(EVP_PKEY_CTX *ctx) { char c='*'; BIO *b = (BIO*)EVP_PKEY_CTX_get_app_data(ctx); int p; p = EVP_PKEY_CTX_get_keygen_info(ctx, 0); if (p == 0) c='.'; if (p == 1) c='+'; if (p == 2) c='*'; if (p == 3) c='\n'; BIO_write(b,&c,1); (void)BIO_flush(b); return 1; } int main() { EVP_PKEY_CTX *ctx = NULL; BIO* out = NULL; EVP_PKEY *pkey = NULL; OPENSSL_init(); CRYPTO_malloc_init(); ERR_load_crypto_strings(); OpenSSL_add_all_algorithms(); for (int i = 0; i < EVP_PKEY_asn1_get_count(); i++) { const EVP_PKEY_ASN1_METHOD * ameth = EVP_PKEY_asn1_get0(i); int pkeyId=0; const char* pinfo = NULL, *pstr = NULL; if (EVP_PKEY_asn1_get0_info(&pkeyId, NULL, NULL, &pinfo, &pstr, ameth) > 0) { pinfo = pinfo?pinfo:" none "; pstr = pstr?pstr:" none "; cout << pkeyId << "|" << pinfo << "|" << pstr << endl; ctx = EVP_PKEY_CTX_new_id(pkeyId, NULL); if (!ctx) { HANDLE_ERR(EVP_PKEY_CTX_new_id); } if (EVP_PKEY_keygen_init(ctx) <= 0) { HANDLE_ERR(EVP_PKEY_keygen_init); } out = BIO_new_fp (stdout, BIO_NOCLOSE); if (!out) { HANDLE_ERR(BIO_new_fp); } EVP_PKEY_CTX_set_cb(ctx, genpkey_cb); EVP_PKEY_CTX_set_app_data(ctx, out); if (EVP_PKEY_keygen(ctx, &pkey) <= 0) { HANDLE_ERR(EVP_PKEY_keygen); } if (EVP_PKEY_print_private(out, pkey, 0, NULL) <= 0) { HANDLE_ERR(EVP_PKEY_print_private); } clear: if (ctx) { EVP_PKEY_CTX_free(ctx); } } } return 0; }
int main()
{
unsigned char* seed = NULL;
int seedlen = 100;
int result = -1;
int nbits = 2048;
DSA* dsa = DSA_new();
seed = (unsigned char*)malloc(seedlen);
for (int i = 0; i < seedlen; i ++)
{
seed[i] = random()%26+'a';
}
if (DSA_generate_parameters_ex(dsa, nbits, seed, seedlen, NULL, NULL, NULL) <= 0)
{
cout << "failure" << endl;
}
else
{
cout << " succeed " << endl;
result = 0;
}
if (result == 0)
{
DSA_print_fp(stdout, dsa, 4);
}
clear:
if (dsa)
{
DSA_free(dsa);
}
if (seed)
{
free(seed);
}
return result;
}An error occurred during a connection to 172.17.95.20. Cannot communicate securely with peer: no common encryption algorithm(s). Error code: SSL_ERROR_NO_CYPHER_OVERLAPThis is actually an expected behavior as it clearly says the browser and CB500 web server does NOT share common cipher, just as it claims. The following step confirms this issue by: a) find out what cipher CB500 support b) what cipher Firefox support
echo -n | openssl s_client -connect 172.17.95.20:443
… (omit long output)
New, TLSv1/SSLv3, Cipher is DHE-RSA-AES256-GCM-SHA384
…#include "openssl/ssl.h" #include "openssl/err.h" #include <vector> #include <string> #include <iostream> using namespace std; static void list_md_fn(const EVP_MD *m, const char *from, const char *to, void *arg) { const char *mname; /* Skip aliases */ if (!m) return; mname = OBJ_nid2ln(EVP_MD_type(m)); /* Skip shortnames */ if (strcmp(from, mname)) return; /* Skip clones */ if (EVP_MD_flags(m) & EVP_MD_FLAG_PKEY_DIGEST) return; if (strchr(mname, ' ')) mname= EVP_MD_name(m); vector<string>* pvect = (vector<string>*) arg; pvect->push_back(mname); } int main(void) { CRYPTO_malloc_init(); ERR_load_crypto_strings(); OpenSSL_add_all_algorithms(); BIO* bio_err = NULL; vector<string> vect; EVP_MD_do_all_sorted(list_md_fn, &vect); for (size_t i = 0; i < vect.size(); i ++) { cout << vect[i] << endl; } return 0; }
md4
md5
mdc2
ripemd160
sha
sha1
sha224
sha256
sha384
sha512
whirlpool二月二十一日 等待变化等待机会
#include "openssl/ssl.h" #include "openssl/err.h" #include <vector> #include <string> #include <iostream> using namespace std; #define HANDLE_ERR(func)\ printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error())); goto clear; void digest(const string& strMD) { #undef BUFSIZE #define BUFSIZE 1024*8 unsigned char buf[BUFSIZE]; const string strFile = __FILE__; BIO* in = NULL; BIO* bmd = NULL; BIO* inp = NULL; BIO* out = NULL; const EVP_MD *md=NULL; int i = 0, len = 0; in=BIO_new(BIO_s_file()); if (!in) { HANDLE_ERR(BIO_new(BIO_s_file())); } if (BIO_read_filename(in,strFile.c_str()) <= 0) { HANDLE_ERR(BIO_read_filename); } bmd=BIO_new(BIO_f_md()); if (!bmd) { HANDLE_ERR(BIO_new(BIO_f_md())); } out = BIO_new_fp(stdout, BIO_NOCLOSE); if (!out) { HANDLE_ERR(BIO_new_fp); } md = EVP_get_digestbyname(strMD.c_str()); if (!md) { HANDLE_ERR(EVP_get_digestbyname); } if (!BIO_set_md(bmd,md)) { HANDLE_ERR(BIO_set_md); } inp=BIO_push(bmd,in); for (;;) { i=BIO_read(inp,(char *)buf,BUFSIZE); if(i < 0) { HANDLE_ERR(BIO_read); } if (i == 0) break; } len = BIO_gets(inp,(char *)buf,BUFSIZE); if (len < 0) { HANDLE_ERR(BIO_gets); } BIO_printf(out, "%s(%s)", strFile.c_str(), EVP_MD_name(md)); for (i=0; i<(int)len; i++) { BIO_printf(out, "%02x",buf[i]); } BIO_printf(out, "\n"); clear: if (in) { BIO_free(in); } if (bmd) { BIO_free(bmd); } if (out) { BIO_free(out); } }
dgstTest.cpp(MD4)7ed5abb9e73db7e0cdca8087ed47d591
dgstTest.cpp(MD5)d162fb7a450600883e470cd99d11a9bc
dgstTest.cpp(MDC2)c90fded0cbe6d85ee8fd7ed1ffb0caac
dgstTest.cpp(RIPEMD160)100d332f2b9b50fb918d486e99fe663a12bdf3d4
dgstTest.cpp(SHA)67c656842faebf31066f352d5dcd48efd3690e5b
dgstTest.cpp(SHA1)b0267c2d5f35a809d1d1b0e2d3330f3df31b9776
dgstTest.cpp(SHA224)914ad20697d74ef4f6a3ec5ac05e2c92b08bd6356e588035d784134c
dgstTest.cpp(SHA256)510df323593d778558f163ea763599dbe89450caa6a4afbcf6c8da9947e81bd1
dgstTest.cpp(SHA384)af6c9d7710bf42cb183f03cefd4c023f2113a1065b58ec54643d5601e3eb304ad8dc1c4c6c7282c846768864b5b91d90
dgstTest.cpp(SHA512)db57d634a4cbe3c3dddfb0aa5e1affc610b4e985a932e64bfe3787cfb682fdd1dcb482047baaa03816db0c5aeee652b978b7bd350c30bd0b4699b223f2cfe5ee
dgstTest.cpp(whirlpool)1d719684050d53c69e8102023fa49341bf61311a081cb369a260a30562b87d942c69923227a8ceb8d3e61086bdf595c316b37cd8c2ebdc8b1b281d1d3b6a2361
二月二十三日 等待变化等待机会
早上写了一个小函数结果忘了,因为又在折腾网络,换回了旧的路由器一切有变了。也许是因为之前设置的静态地址有冲突链接都是出现问题,观察到我的笔记本总是被我的服务器上的dhcp干扰,在/var/lib/dhcp/下可以看到lease文件。同时有些命令很有用的比如:ip route get some-ip,为什么呢?因为今天工作中有客户在现场设置了比较复杂的网络配置,有两个网卡配置了两个网络,然后我们的服务需要监听来自一个网络的命令去查询的时候使用另一个网卡前往另一个网络的设备,那么这个命令就比较有用比traceroute有别样的功能。二月二十五日 等待变化等待机会
case EVP_PKEY_CTRL_DSA_PARAMGEN_MD:
if (EVP_MD_type((const EVP_MD *)p2) != NID_sha1 &&
EVP_MD_type((const EVP_MD *)p2) != NID_sha224 &&
EVP_MD_type((const EVP_MD *)p2) != NID_sha256)
{
DSAerr(DSA_F_PKEY_DSA_CTRL, DSA_R_INVALID_DIGEST_TYPE);
return 0;
}
// This is an obvious typo because md is for digest and for param gen it should be pmd
//dctx->md = p2;
dctx->pmd = p2;
return 1;
#include "openssl/ssl.h"
#include "openssl/err.h"
static void list_md_fn(const EVP_MD *m, const char *from, const char *to, void *arg)
{
if (m)
BIO_printf((BIO*)arg, "%s\n", EVP_MD_name(m));
else
{
// if you read source code, you know this is case of alias
if (!from)
from = "<undefined>";
if (!to)
to = "<undefined>";
BIO_printf((BIO*)arg, "%s => %s\n", from, to);
}
}
static void list_md(BIO *out)
{
EVP_MD_do_all_sorted(list_md_fn, out);
}
static void list_cipher_fn(const EVP_CIPHER *c, const char *from, const char *to, void *arg)
{
if (c)
BIO_printf((BIO*)arg, "%s\n", EVP_CIPHER_name(c));
else
{
if (!from)
from = "<undefined>";
if (!to)
to = "<undefined>";
BIO_printf((BIO*)arg, "%s => %s\n", from, to);
}
}
static void list_cipher(BIO *out)
{
EVP_CIPHER_do_all_sorted(list_cipher_fn, out);
}
static void list_pkey(BIO *out)
{
int i;
for (i = 0; i < EVP_PKEY_asn1_get_count(); i++)
{
const EVP_PKEY_ASN1_METHOD *ameth;
int pkey_id, pkey_base_id, pkey_flags;
const char *pinfo, *pem_str;
ameth = EVP_PKEY_asn1_get0(i);
EVP_PKEY_asn1_get0_info(&pkey_id, &pkey_base_id, &pkey_flags,
&pinfo, &pem_str, ameth);
if (pkey_flags & ASN1_PKEY_ALIAS)
{
BIO_printf(out, "Name: %s\n",
OBJ_nid2ln(pkey_id));
BIO_printf(out, "\tType: Alias to %s\n",
OBJ_nid2ln(pkey_base_id));
}
else
{
BIO_printf(out, "Name: %s\n", pinfo);
BIO_printf(out, "\tType: %s Algorithm\n",
pkey_flags & ASN1_PKEY_DYNAMIC ?
"External" : "Builtin");
BIO_printf(out, "\tOID: %s\n", OBJ_nid2ln(pkey_id));
BIO_printf(out, "\tOID: %d\n", (pkey_id));
if (pem_str == NULL)
pem_str = "(none)";
BIO_printf(out, "\tPEM string: %s\n", pem_str);
}
}
}
int main(void)
{
BIO* out = NULL;
OPENSSL_init();
CRYPTO_malloc_init();
ERR_load_crypto_strings();
OpenSSL_add_all_algorithms();
out = BIO_new_fp(stdout, BIO_NOCLOSE);
if (out)
{
BIO_printf(out, "**************method list*****************\n");
list_md(out);
BIO_printf(out, "**************cipher list*****************\n");
list_cipher(out);
BIO_printf(out, "**************pkey list*****************\n");
list_pkey(out);
BIO_free(out);
}
return 0;
}
int main()
{
BIO* out = NULL;
EVP_PKEY* pkey = NULL;
OPENSSL_init();
CRYPTO_malloc_init();
ERR_load_crypto_strings();
OpenSSL_add_all_algorithms();
out = BIO_new_fp(stdout, BIO_NOCLOSE);
if (out)
{
EVP_PKEY* dsakey = EVP_PKEY_new();
if (dsakey)
{
if (EVP_PKEY_assign_DSA(dsakey, DSA_new())>0)[1]
{
EVP_PKEY_CTX *ctx = EVP_PKEY_CTX_new(dsakey, NULL);
if (ctx)
{
if (EVP_PKEY_paramgen_init(ctx))
{
const char* q_bits = "160";//224; 256;
const char* bits = "2048";
const char* method="sha1"; // "sha224", "sha256";
if (EVP_PKEY_CTX_ctrl_str(ctx, "dsa_paramgen_q_bits", q_bits)>0
&& EVP_PKEY_CTX_ctrl_str(ctx, "dsa_paramgen_bits", bits)>0
&& EVP_PKEY_CTX_ctrl_str(ctx, "dsa_paramgen_md", method)>0)[2]
{
if (EVP_PKEY_paramgen(ctx, &pkey)>=0)[3]
{
EVP_PKEY_print_public(out, pkey, 4, NULL);
EVP_PKEY_print_private(out, pkey, 4, NULL);
}
}
}
EVP_PKEY_CTX_free(ctx);
}
}
EVP_PKEY_free(dsakey);
}
BIO_free(out);
}
return 0;
}}
if (EVP_PKEY_CTX_ctrl(ctx, EVP_PKEY_DSA, EVP_PKEY_OP_PARAMGEN,
EVP_PKEY_CTRL_DSA_PARAMGEN_BITS, nbits, NULL)>0 &&
EVP_PKEY_CTX_ctrl(ctx, EVP_PKEY_DSA, EVP_PKEY_OP_PARAMGEN,
EVP_PKEY_CTRL_DSA_PARAMGEN_Q_BITS, qbits, NULL)>0 &&
EVP_PKEY_CTX_ctrl(ctx, EVP_PKEY_DSA, EVP_PKEY_OP_PARAMGEN,
EVP_PKEY_CTRL_DSA_PARAMGEN_MD, 0, (char*)EVP_sha256())>0)
int main(void)
{
DSA* dsa = DSA_new();
if (dsa)
{
unsigned char seed[] = "abcdefghijklmnopqrstxyz";
int nbits = 2048;
if (DSA_generate_parameters_ex(dsa, nbits, seed, sizeof(seed), NULL, NULL, NULL)>0)
{
//if (DSA_generate_key(dsa)>0)
{
DSA_print_fp(stdout, dsa, 4);
}
}
DSA_free(dsa);
}
}二月二十六日 等待变化等待机会
最新版的openssl的配置似乎有些调整,不过也许是我自己的误判。这个是我现在的配置尝试:./Configure linux-x86_64 -lpthread threads no-shared no-zlib no-asm no-dso no-hw原因是因为发现no-shared和no-dso的意义似乎不一样,我也不明白为什么openssl的apps需要dso而当我已经明确no-dso,什么叫做no-shared?我的理解就是no-pic,难道不对吗?再次尝试:./config -d -v -lpthread threads no-shared no-zlib no-asm no-dso no-hw三月二日 等待变化等待机会
#include <cstdio> #include <cstdlib> #include <string> #include "libssh2.h" #include <sys/socket.h> #include <netinet/in.h> #include <unistd.h> #include <arpa/inet.h> #include <sys/types.h> #include <iostream> using namespace std; #define BUFSIZE 32000 const unsigned long int BufSize=2048; class MySSH2 { private: int m_sock; LIBSSH2_SESSION *m_session; LIBSSH2_CHANNEL *m_channel; char m_err[1025]; string m_strIp; string m_strUser; string m_strPasswd; bool bInitialized; public: int waitsocket(int socket_fd, LIBSSH2_SESSION *session) { struct timeval timeout; int rc; fd_set fd; fd_set *writefd = NULL; fd_set *readfd = NULL; int dir; timeout.tv_sec = 10; timeout.tv_usec = 0; FD_ZERO(&fd); FD_SET(socket_fd, &fd); /* now make sure we wait in the correct direction */ dir = libssh2_session_block_directions(session); if(dir & LIBSSH2_SESSION_BLOCK_INBOUND) readfd = &fd; if(dir & LIBSSH2_SESSION_BLOCK_OUTBOUND) writefd = &fd; rc = select(socket_fd + 1, readfd, writefd, NULL, &timeout); return rc; } bool init_library() { if (libssh2_init (0) == 0) { bInitialized = true; } } bool init_socket() { if (m_sock != -1) { return true; } unsigned long hostaddr; struct sockaddr_in sin; hostaddr = inet_addr(m_strIp.c_str()); m_sock = socket(AF_INET, SOCK_STREAM, 0); sin.sin_family = AF_INET; sin.sin_port = htons(22); sin.sin_addr.s_addr = hostaddr; if (connect(m_sock, (struct sockaddr*)(&sin), sizeof(struct sockaddr_in)) != 0) { snprintf(m_err,1024, "failed to connect!\n"); uninit_socket(); return false; } return true; } bool init_session() { if (m_session != NULL) { return true; } int rc; if (m_sock == -1) { snprintf(m_err, 1024, "Socket is not initialized \n"); return false; } m_session = libssh2_session_init(); if (!m_session) { return false; } /* tell libssh2 we want it all done non-blocking */ libssh2_session_set_blocking(m_session, 0); while ((rc = libssh2_session_handshake(m_session, m_sock)) == LIBSSH2_ERROR_EAGAIN) { waitsocket(m_sock, m_session); } if (rc) { snprintf(m_err, 1024, "Failure establishing SSH session: %d\n", rc); uninit_session(); return false; } while ((rc = libssh2_userauth_password(m_session, m_strUser.c_str(), m_strPasswd.c_str())) == LIBSSH2_ERROR_EAGAIN) { waitsocket(m_sock, m_session); } if (rc) { snprintf(m_err, 1024, "Authentication by password failed.\n"); uninit_session(); return false; } return true; } int init_channel() { if (m_channel) { return true; } if (m_sock == -1) { snprintf(m_err, 1024, "Socket is not initialized \n"); return false; } if (m_session == NULL) { snprintf(m_err, 1024, "Session is not initialized \n"); return false; } while( (m_channel = libssh2_channel_open_session(m_session)) == NULL && libssh2_session_last_error(m_session, NULL, NULL, 0) == LIBSSH2_ERROR_EAGAIN ) { waitsocket(m_sock, m_session); } if( m_channel == NULL ) { snprintf(m_err, 1024,"Error\n"); uninit_channel(); return false; } return true; } void uninit_library() { if (bInitialized) { libssh2_exit(); } } void uninit_socket() { if (m_sock!= -1) { close(m_sock); m_sock = -1; } } void uninit_session() { if (m_session) { libssh2_session_disconnect(m_session, "Normal Shutdown, Thank you for playing"); m_session = NULL; } } void uninit_channel() { if (m_channel) { if (m_sock != -1 && m_session != NULL) { while( libssh2_channel_close(m_channel) == LIBSSH2_ERROR_EAGAIN ) { waitsocket(m_sock, m_session); } } libssh2_channel_free(m_channel); m_channel = NULL; } } bool do_exec(const string& strCommand, string& strResult) { if (init_channel()) { int rc; while( (rc = libssh2_channel_exec(m_channel, strCommand.c_str())) == LIBSSH2_ERROR_EAGAIN ) { waitsocket(m_sock, m_session); } if( rc != 0 ) { snprintf(m_err, 1024, "Error\n"); uninit_channel(); return false; } char buffer[0x4000]; while ((rc = libssh2_channel_read(m_channel, buffer, sizeof(buffer))) > 0 || rc == LIBSSH2_ERROR_EAGAIN) { if( rc > 0 ) { strResult.append(buffer, rc); } if( rc == LIBSSH2_ERROR_EAGAIN ) { waitsocket(m_sock, m_session); } } if (rc == 0) { char *exitsignal=(char *)"none"; int exitcode = 127; exitcode = libssh2_channel_get_exit_status( m_channel ); libssh2_channel_get_exit_signal(m_channel, &exitsignal, NULL, NULL, NULL, NULL, NULL); if (exitsignal) { snprintf(m_err, 1024, "\nGot signal: %s\n", exitsignal); } else { snprintf(m_err, 1024, "\nEXIT: %d\n", exitcode); } uninit_channel(); return true; } snprintf(m_err, 1024, "libssh2_channel_read returned %d\n", rc); uninit_channel(); } return false; } bool init() { if (init_library()) { if (init_socket()) { if (init_session()) { return true; } } } return false; } ~MySSH2() { uninit_channel(); uninit_session(); uninit_socket(); uninit_library(); } MySSH2(const string& strIp, const string& strUser, const string& strPasswd) { m_sock = -1; m_session = NULL; m_channel = NULL; bInitialized = false; m_strIp = strIp; m_strUser = strUser; m_strPasswd = strPasswd; memset(m_err, 0, sizeof(m_err)); } }; int test1() { MySSH2 ssh("192.168.1.115", "nick", "202409"); string strResult;; string strCmd; if (ssh.init()) { strCmd = "uname -a"; strResult.clear(); if (ssh.do_exec(strCmd, strResult)) { cout << strCmd << ":" << endl << strResult << endl; } strCmd = "ls -asl"; strResult.clear(); if (ssh.do_exec(strCmd, strResult)) { cout << strCmd << ":" << endl << strResult << endl; } strCmd = "lsb_release -a"; strResult.clear(); if (ssh.do_exec(strCmd, strResult)) { cout << strCmd << ":" << endl << strResult << endl; } } return 0; } int main(int argc, char** argv) { return test1(); }
三月四日 等待变化等待机会
我的想法还是挺幼稚的,因为我压根不熟悉ssh的协议,似乎这个是耸人听闻,但凡有基本计算机使用经验的不会没有使用过ssh客户端,那么怎么会说不熟悉呢?原因是在正式的协议本身.三月五日 等待变化等待机会
debug1: userauth-request for user nick service ssh-connection method publickey [preauth]
debug1: attempt 1 failures 0 [preauth]
debug2: input_userauth_request: try method publickey [preauth]
debug1: test whether pkalg/pkblob are acceptable [preauth]
debug3: mm_key_allowed entering [preauth]
debug3: mm_request_send entering: type 22 [preauth]
debug3: mm_key_allowed: waiting for MONITOR_ANS_KEYALLOWED [preauth]
debug3: mm_request_receive_expect entering: type 23 [preauth]
debug3: mm_request_receive entering [preauth]
debug3: mm_request_receive entering
debug3: monitor_read: checking request 4
debug3: mm_answer_authserv: service=ssh-connection, style=, role=
debug2: monitor_read: 4 used once, disabling now
debug3: mm_request_receive entering
debug3: monitor_read: checking request 22
debug3: mm_answer_keyallowed entering
debug3: mm_answer_keyallowed: key_from_blob: 0x56368a53c2f0
debug1: temporarily_use_uid: 1000/1000 (e=0/0)
debug1: trying public key file /home/nick/.ssh/authorized_keys
debug1: fd 4 clearing O_NONBLOCK
debug1: matching key found: file /home/nick/.ssh/authorized_keys, line 1 RSA eb:a5:e7:59:7d:24:0e:ce:b4:c4:d4:f8:7f:87:d6:d9
debug1: restore_uid: 0/0
debug3: mm_answer_keyallowed: key 0x56368a53c2f0 is allowed
debug3: mm_request_send entering: type 23
debug2: userauth_pubkey: authenticated 0 pkalg ssh-rsa [preauth]
Postponed publickey for nick from 192.168.1.116 port 59340 ssh2 [preauth]三月六日 等待变化等待机会
#include <cstdio> #include <cstdlib> #include <string> #include <algorithm> #include <vector> #include "libssh2.h" #include <sys/socket.h> #include <netinet/in.h> #include <unistd.h> #include <arpa/inet.h> #include <sys/types.h> #include <iostream> #include <pthread.h> #include "boost/algorithm/string.hpp" using namespace std; time_t startTime, endTime; #define PROFILE_NOW(context) \ cout <<"&&&&&&&&&"<<context<<"[" << time(&endTime)-startTime<<"]&&&&&&&&&"<<endl;startTime=endTime; static bool smashInvalidChar (char c) { return !(c>=0 && c <128); } class MySSH2 { private: int m_sock; LIBSSH2_SESSION *m_session; LIBSSH2_CHANNEL *m_channel; char m_err[1025]; string m_strIp; string m_strUser; string m_strPasswd; int m_timeout; bool bInitialized; public: int waitsocket(int socket_fd, LIBSSH2_SESSION *session) { int rc; fd_set fd; fd_set *writefd = NULL; fd_set *readfd = NULL; int dir; struct timeval timeout; timeout.tv_sec = m_timeout; timeout.tv_usec = 0; FD_ZERO(&fd); FD_SET(socket_fd, &fd); /* now make sure we wait in the correct direction */ dir = libssh2_session_block_directions(session); if(dir & LIBSSH2_SESSION_BLOCK_INBOUND) readfd = &fd; if(dir & LIBSSH2_SESSION_BLOCK_OUTBOUND) writefd = &fd; rc = select(socket_fd + 1, readfd, writefd, NULL, &timeout); return rc; } bool init_library() { if (libssh2_init(0) == 0) { cout << "libssh2 version:"<< libssh2_version(1) << endl; bInitialized = true; } } bool init_socket() { if (m_sock != -1) { return true; } unsigned long hostaddr; struct sockaddr_in sin; hostaddr = inet_addr(m_strIp.c_str()); m_sock = socket(AF_INET, SOCK_STREAM, 0); sin.sin_family = AF_INET; sin.sin_port = htons(22); sin.sin_addr.s_addr = hostaddr; if (connect(m_sock, (struct sockaddr*)(&sin), sizeof(struct sockaddr_in)) != 0) { snprintf(m_err,1024, "failed to connect!\n"); uninit_socket(); return false; } return true; } bool init_session() { if (m_session != NULL) { return true; } int rc; if (m_sock == -1) { snprintf(m_err, 1024, "Socket is not initialized \n"); return false; } m_session = libssh2_session_init(); if (!m_session) { return false; } /* tell libssh2 we want it all done non-blocking */ libssh2_session_set_blocking(m_session, 0); while ((rc = libssh2_session_handshake(m_session, m_sock)) == LIBSSH2_ERROR_EAGAIN) { waitsocket(m_sock, m_session); } if (rc) { snprintf(m_err, 1024, "Failure establishing SSH session: %d\n", rc); uninit_session(); return false; } while ((rc = libssh2_userauth_password(m_session, m_strUser.c_str(), m_strPasswd.c_str())) == LIBSSH2_ERROR_EAGAIN) { waitsocket(m_sock, m_session); } if (rc) { snprintf(m_err, 1024, "Authentication by password failed.\n"); uninit_session(); return false; } return true; } bool init_channel() { if (m_channel) { return true; } if (m_sock == -1) { snprintf(m_err, 1024, "Socket is not initialized \n"); return false; } if (m_session == NULL) { snprintf(m_err, 1024, "Session is not initialized \n"); return false; } while( (m_channel = libssh2_channel_open_session(m_session)) == NULL && libssh2_session_last_error(m_session, NULL, NULL, 0) == LIBSSH2_ERROR_EAGAIN ) { waitsocket(m_sock, m_session); } if( m_channel == NULL ) { snprintf(m_err, 1024,"Error\n"); uninit_channel(); return false; } return true; } bool init_channel_tty() { if (m_channel) { return true; } if (m_sock == -1) { snprintf(m_err, 1024, "Socket is not initialized \n"); return false; } if (m_session == NULL) { snprintf(m_err, 1024, "Session is not initialized \n"); return false; } while( (m_channel = libssh2_channel_open_session(m_session)) == NULL && libssh2_session_last_error(m_session, NULL, NULL, 0) == LIBSSH2_ERROR_EAGAIN ) { if (waitsocket(m_sock, m_session) == 0) { return false; } } if( m_channel == NULL ) { snprintf(m_err, 1024,"Error\n"); return false; } while( libssh2_channel_request_pty_ex(m_channel, "vt102", (int)strlen("vt102"), NULL, 0, LIBSSH2_TERM_WIDTH, LIBSSH2_TERM_HEIGHT, LIBSSH2_TERM_WIDTH_PX, LIBSSH2_TERM_HEIGHT_PX) == LIBSSH2_ERROR_EAGAIN) { if (waitsocket(m_sock, m_session) == 0) // timeout { return false; } } while(libssh2_channel_shell(m_channel) == LIBSSH2_ERROR_EAGAIN ) { if (waitsocket(m_sock, m_session) == 0) { return false; } } return true; } void uninit_library() { if (bInitialized) { libssh2_exit(); } } void uninit_socket() { if (m_sock!= -1) { close(m_sock); m_sock = -1; } } void uninit_session() { if (m_session) { while (libssh2_session_disconnect(m_session, "Normal Shutdown, Thank you for playing") == LIBSSH2_ERROR_EAGAIN) { if (waitsocket(m_sock, m_session) == 0) { break; // timeout do nothing... } } m_session = NULL; } } void uninit_channel() { if (m_channel) { if (m_sock != -1 && m_session != NULL) { while(libssh2_channel_close(m_channel) == LIBSSH2_ERROR_EAGAIN ) { if (waitsocket(m_sock, m_session) == 0) // timeout { break; } } } libssh2_channel_free(m_channel); m_channel = NULL; } } bool init() { if (init_library()) { if (init_socket()) { if (init_session()) { return true; } } } return false; } ~MySSH2() { uninit_channel(); uninit_session(); uninit_socket(); uninit_library(); } MySSH2(const string& strIp, const string& strUser, const string& strPasswd, int timeOut = 10); bool do_exec_tty(const string& strCmd, vector<string>& vResult, const string& strExitCond="***********impossibleconditions******************"); }; MySSH2::MySSH2(const string& strIp, const string& strUser, const string& strPasswd, int timeOut) { m_sock = -1; m_session = NULL; m_channel = NULL; bInitialized = false; m_strIp = strIp; m_strUser = strUser; m_strPasswd = strPasswd; m_timeout = timeOut; memset(m_err, 0, sizeof(m_err)); } bool MySSH2::do_exec_tty(const string& strCmd, vector<string>& vResult, const string& strExitCond) { bool bResult = false; if (init_channel_tty()) { char buffer[2048]; size_t writeTotal = 0, readTotal = 0; int rc = 0; int writeNum = 0, readNum = 0; bool bWritten = false; bool bRead = false; string strResult; libssh2_channel_receive_window_adjust2(m_channel, sizeof(buffer), 1, NULL);[1] do { // write first while (writeTotal < strCmd.size() && (writeNum = libssh2_channel_write(m_channel, strCmd.substr(writeTotal).c_str(), strCmd.size()- writeTotal)) > 0 ) { writeTotal += writeNum; } // check on error and break if (writeNum != LIBSSH2_ERROR_EAGAIN && writeNum <0) { //log error cout << "#######################write error#####################"<< endl; break; } // set write finished if (!bWritten && writeTotal>=strCmd.size()) { libssh2_channel_send_eof(m_channel);[2] //PROFILE_NOW("write is done"); bWritten = true; } // read all the time while (readTotal < sizeof(buffer) && (readNum = libssh2_channel_read(m_channel, buffer+readTotal, sizeof(buffer)-readTotal)) > 0 ) { //PROFILE_NOW("readNum...."); cout << "############read number###########"<<readNum<<"########################" << endl; // filter unreadable char string strSrc(buffer+readTotal, readNum); remove_copy_if(strSrc.begin(), strSrc.end(), back_inserter(strResult), smashInvalidChar); if (strResult.find(strExitCond) != string::npos) { cout << "########find exit condition#############" << endl; bRead = true; break; } readTotal += readNum; // we need to restart a new buffer for reading. if (readTotal >= sizeof(buffer)) { readTotal = 0; } } if (readNum != LIBSSH2_ERROR_EAGAIN && readNum <0) { // log it cout << "#######################read error#####################"<< endl; break; } if (((!bWritten && writeNum == LIBSSH2_ERROR_EAGAIN)// 1. still need to write || bWritten) // 2. write is done && readNum == LIBSSH2_ERROR_EAGAIN // 2. reading blocked )[4] { if ((rc = waitsocket(m_sock, m_session)) <= 0)[3] { // this means timeout or error!! not necessarilly!!! can be succeed!!! cout << "#######################timeout#####################"<< endl; bResult = true; break; } } // success condition is either meet exit condition or server send EOF to ask us to if (bRead || libssh2_channel_eof(m_channel) == 1) { bResult = true; break; } } while (true); // will unit channel always uninit_channel(); // now let's process result by filtering and splitting if (bResult) { // split lines into vectors boost::split(vResult, strResult, boost::is_any_of("\n\r"),boost::token_compress_on); } } return bResult; } static void display(const string& strCmd, const vector<string>& vResult) { cout.flush(); cout << strCmd << ":["<<vResult.size() << "]" << endl; cout << "****************************" << endl; for (size_t i = 0; i < vResult.size(); i ++) { cout <<"["<<i<<"]:"<< vResult[i] << endl; } cout << "****************************" << endl; cout.flush(); } int quanta() { // quanta smash sucks and needs bigger timeout MySSH2 ssh("172.17.11.14", "admin", "cmb9.admin", 30); vector<string> vResult;; string strCmd; if (ssh.init()) { strCmd = "help\r\n"; if (ssh.do_exec_tty(strCmd, vResult)) { display(strCmd, vResult); } else { cout << "failed" << endl; } strCmd = "version\r\n"; if (ssh.do_exec_tty(strCmd, vResult)) { display(strCmd, vResult); } else { cout << "failed" << endl; } } return 0; } int linuxSSH() { MySSH2 ssh("172.17.59.177", "root", "Hitachi1"); vector<string> vResult;; string strCmd; PROFILE_NOW("test7"); if (ssh.init()) { strCmd = "lspci\n"; if (ssh.do_exec_tty(strCmd, vResult)) { display(strCmd, vResult); } else { cout << "failed" << endl; } PROFILE_NOW("lspci"); strCmd = "find /home\n"; if (ssh.do_exec_tty(strCmd, vResult)) { display(strCmd, vResult); } else { cout << "failed" << endl; } PROFILE_NOW("find /home"); strCmd = "lslogins\n"; if (ssh.do_exec_tty(strCmd, vResult)) { display(strCmd, vResult); } else { cout << "failed" << endl; } PROFILE_NOW("lslogins"); } return 0; } int hitachiSmash() { MySSH2 ssh("172.17.59.165", "ceconsl", "cepasswd"); vector<string> vResult;; string strCmd; PROFILE_NOW("test8"); if (ssh.init()) { strCmd = "show chassis setting \r exit \r"; if (ssh.do_exec_tty(strCmd, vResult, "S0000 : Command was finished.")) { display(strCmd, vResult); } else { cout << "failed" << endl; } PROFILE_NOW("show chassis setting"); strCmd = "show sw-module mgmt-lan \r exit \r"; if (ssh.do_exec_tty(strCmd, vResult, "S0000 : Command was finished.")) { display(strCmd, vResult); } else { cout << "failed" << endl; } PROFILE_NOW("show sw-module mgmt-lan"); strCmd = "show blade hardware 2 -h\r exit \r"; if (ssh.do_exec_tty(strCmd, vResult, "S0000 : Command was finished.")) { display(strCmd, vResult); } else { cout << "failed" << endl; } PROFILE_NOW("show blade hardware 2"); strCmd = "show blade firmware 2 \r exit \r"; if (ssh.do_exec_tty(strCmd, vResult, "S0000 : Command was finished.")) { display(strCmd, vResult); } else { cout << "failed" << endl; } PROFILE_NOW("show blade firmware 2"); } return 0; } int main(int argc, char** argv) { quanta(); hitachiSmash(); linuxSSH(); return 0; }
libssh2 version:1.4.3-20120709
############read number###########8########################
############read number###########45########################
############read number###########8########################
############read number###########24########################
############read number###########2########################
############read number###########2########################
############read number###########18########################
############read number###########364########################
#######################timeout#####################
help
:[16]
****************************
[0]:help
[1]:[2J[H
[2]: >> SMASHLITE Scorpio Console <<
[3]:->help
[4]:COMMAND COMPLETED : help
[5]:Command Name: help
[6]:Used to get help on commands and targets
[7]:Usage: help [-options]
[8]:Options:
[9]: examine - used to examine the command (bypasses executer)
[10]: help - shows help on how to use help
[11]: output - formats the output string (should be used with format (text,clpcsv,keyword,clpxml)
[12]: like help -output format=keyword
[13]: version - shows the smash version
[14]:->
[15]:->
****************************
############read number###########11########################
############read number###########45########################
############read number###########2########################
############read number###########1########################
############read number###########1########################
############read number###########1########################
############read number###########1########################
############read number###########1########################
############read number###########1########################
############read number###########195########################
#######################timeout#####################
version
:[10]
****************************
[0]:version
[1]:[2J[H
[2]: >> SMASHLITE Scorpio Console <<
[3]:->version
[4]:COMMAND COMPLETED : version
[5]:*****************************************************
[6]:Smash CLP Version :SMASH 1.0.0/CLP 1.09
[7]:*****************************************************
[8]:->
[9]:->
****************************
&&&&&&&&&test8[1520389566]&&&&&&&&&
libssh2 version:1.4.3-20120709
############read number###########31########################
############read number###########189########################
############read number###########41########################
############read number###########119########################
############read number###########329########################
############read number###########55########################
############read number###########282########################
########find exit condition#############
show chassis setting
exit
:[30]
****************************
[0]:show chassis setting
[1]: exit
[2]:[H[JHitachi Compute Blade 2500 Management Module
[3]:ALL RIGHTS RESERVED, COPYRIGHT (C) 2014,2016, HITACHI, LTD.
[4]:Chassis ID : chassis59_165
[5]:Firmware Revision : A0160-B-1453
[6]:chassis59_165(1)$ show chassis setting
[7]:-- chassis setting --
[8]:Chassis ID : chassis59_165
[9]:Maintenance classification : normal
[10]:WDT time-out N+M failover : disable
[11]:-- chassis FRU setting --
[12]:Part/model number : GG-RE4A1UBX1-Y
[13]:Serial number :
[14]:Model ID : 00
[15]:Midplane ID : 00
[16]:First WWN : 0102000000000000000000
[17]:-- Weight --
[18]:Weight [kg] : 120.47
[19]:-- chassis sensor information --
[20]:-- Watt --
[21]:PresentAC Power : 433
[22]:PresentDC Power : 372
[23]:-- Temp --
[24]:Present Ambient : 22
[25]:-- Flow --
[26]:PresentAir Flow : 10.21
[27]:S0002 : Command succeeded.
[28]:S0000 : Command was finished.
[29]:
****************************
&&&&&&&&&show chassis setting[4]&&&&&&&&&
############read number###########34########################
############read number###########189########################
############read number###########44########################
############read number###########383########################
########find exit condition#############
show sw-module mgmt-lan
exit
:[20]
****************************
[0]:show sw-module mgmt-lan
[1]: exit
[2]:[H[JHitachi Compute Blade 2500 Management Module
[3]:ALL RIGHTS RESERVED, COPYRIGHT (C) 2014,2016, HITACHI, LTD.
[4]:Chassis ID : chassis59_165
[5]:Firmware Revision : A0160-B-1453
[6]:chassis59_165(1)$ show sw-module mgmt-lan
[7]:-- Switch module management LAN setting --
[8]:Slot : 1
[9]:IP address : 172.17.59.163
[10]:Subnetmask : 255.255.255.0
[11]:Default gateway : 172.17.59.1
[12]:-- Switch module management LAN setting --
[13]:Slot : 2
[14]:IP address : 172.17.59.164
[15]:Subnetmask : 255.255.255.0
[16]:Default gateway : 172.17.59.1
[17]:S0002 : Command succeeded.
[18]:S0000 : Command was finished.
[19]:
****************************
&&&&&&&&&show sw-module mgmt-lan[3]&&&&&&&&&
############read number###########34########################
############read number###########189########################
############read number###########44########################
############read number###########1229########################
############read number###########251########################
############read number###########241########################
############read number###########60########################
############read number###########10########################
############read number###########59########################
########find exit condition#############
show blade hardware 2 -h
exit
:[48]
****************************
[0]:show blade hardware 2 -h
[1]: exit
[2]:[H[JHitachi Compute Blade 2500 Management Module
[3]:ALL RIGHTS RESERVED, COPYRIGHT (C) 2014,2016, HITACHI, LTD.
[4]:Chassis ID : chassis59_165
[5]:Firmware Revision : A0160-B-1453
[6]:chassis59_165(1)$ show blade hardware 2 -h
[7]:-- Server blade hardware information --
[8]:Slot : 2
[9]:-- Server blade --
[10]:Product name : Compute Blade 520HB4
[11]:Model name : GG-RV3XGC0B4X1-Y
[12]:Serial number : 323GG-RV3XGC0B4X1-Y00000087
[13]:-- CPU --
[14]:Name : Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
[15]:Installed : 2
[16]:Slots : 2
[17]:-- Memory --
[18]:Memory [MB] : 131072
[19]:-- I/O card --
[20]:Mezzanine 1 : -----
[21]:Mezzanine 2 : PCI Express Adapter Connection Mezzanine Card
[22]:PCI 0 : -----
[23]:PCI 1 : -----
[24]:Daughter card 0 : -----
[25]:-- OnBoard LAN 1 --
[26]:Type : 10Gb Onboard LAN
[27]:LOM#1 MAC for Port#0 : f8:48:97:aa:19:f0
[28]:LOM#1 MAC for Port#1 : f8:48:97:aa:19:f4
[29]:LOM#1 MAC for Port#2 : f8:48:97:aa:19:f8
[30]:LOM#1 MAC for Port#3 : f8:48:97:aa:19:fc
[31]:-- LP license --
[32]:LP model : Essential
[33]:Upper bound of version : -----
[34]:-- Power --
[35]:Nameplate power [W] : 429
[36]:-- Weight --
[37]:Weight [kg] : 7.100
[38]:-- UUID --
[39]:UUID : 3d040dd2-e2ce-11e5-93b1-9521be8ac651
[40]:-- BMC MAC address --
[41]:BMC MAC address 0 : f8:48:97:ca:58:00
[42]:BMC MAC address 1 : f8:48:97:ca:58:01
[43]:-- LOM type --
[44]:LOM : enable
[45]:S0002 : Command succeeded.
[46]:S0000 : Command was finished.
[47]:
****************************
&&&&&&&&&show blade hardware 2[4]&&&&&&&&&
############read number###########32########################
############read number###########189########################
############read number###########42########################
############read number###########568########################
########find exit condition#############
show blade firmware 2
exit
:[26]
****************************
[0]:show blade firmware 2
[1]: exit
[2]:[H[JHitachi Compute Blade 2500 Management Module
[3]:ALL RIGHTS RESERVED, COPYRIGHT (C) 2014,2016, HITACHI, LTD.
[4]:Chassis ID : chassis59_165
[5]:Firmware Revision : A0160-B-1453
[6]:chassis59_165(1)$ show blade firmware 2
[7]:-- Server blade firmware version --
[8]:Slot : 2
[9]:-- Total version --
[10]:Current version : 10-02(03)
[11]:Next version : -----
[12]:-- BMC version --
[13]:Current version : 10-02(00)
[14]:Next version : -----
[15]:-- EFI version --
[16]:Current version : 10-02(03)
[17]:Next version : -----
[18]:-- HVM firmware --
[19]:Current version : -----
[20]:Current bank : -----
[21]:Next version : -----
[22]:Next bank : -----
[23]:S0002 : Command succeeded.
[24]:S0000 : Command was finished.
[25]:
****************************
&&&&&&&&&show blade firmware 2[3]&&&&&&&&&
&&&&&&&&&test7[0]&&&&&&&&&
libssh2 version:1.4.3-20120709
############read number###########58########################
############read number###########7########################
############read number###########30########################
############read number###########1953########################
############read number###########728########################
#######################timeout#####################
lspci
:[46]
****************************
[0]:Last login: Tue Mar 6 19:05:47 2018 from 172.17.58.110
[1]:lspci
[2]:[root@OEL72-59-177 ~]# lspci
[3]:00:00.0 Host bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX Host bridge (rev 01)
[4]:00:01.0 PCI bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX AGP bridge (rev 01)
[5]:00:07.0 ISA bridge: Intel Corporation 82371AB/EB/MB PIIX4 ISA (rev 08)
[6]:00:07.1 IDE interface: Intel Corporation 82371AB/EB/MB PIIX4 IDE (rev 01)
[7]:00:07.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 08)
[8]:00:07.7 System peripheral: VMware Virtual Machine Communication Interface (rev 10)
[9]:00:0f.0 VGA compatible controller: VMware SVGA II Adapter
[10]:00:10.0 SCSI storage controller: LSI Logic / Symbios Logic 53c1030 PCI-X Fusion-MPT Dual Ultra320 SCSI (rev 01)
[11]:00:11.0 PCI bridge: VMware PCI bridge (rev 02)
[12]:00:15.0 PCI bridge: VMware PCI Express Root Port (rev 01)
[13]:00:15.1 PCI bridge: VMware PCI Express Root Port (rev 01)
[14]:00:15.2 PCI bridge: VMware PCI Express Root Port (rev 01)
[15]:00:15.3 PCI bridge: VMware PCI Express Root Port (rev 01)
[16]:00:15.4 PCI bridge: VMware PCI Express Root Port (rev 01)
[17]:00:15.5 PCI bridge: VMware PCI Express Root Port (rev 01)
[18]:00:15.6 PCI bridge: VMware PCI Express Root Port (rev 01)
[19]:00:15.7 PCI bridge: VMware PCI Express Root Port (rev 01)
[20]:00:16.0 PCI bridge: VMware PCI Express Root Port (rev 01)
[21]:00:16.1 PCI bridge: VMware PCI Express Root Port (rev 01)
[22]:00:16.2 PCI bridge: VMware PCI Express Root Port (rev 01)
[23]:00:16.3 PCI bridge: VMware PCI Express Root Port (rev 01)
[24]:00:16.4 PCI bridge: VMware PCI Express Root Port (rev 01)
[25]:00:16.5 PCI bridge: VMware PCI Express Root Port (rev 01)
[26]:00:16.6 PCI bridge: VMware PCI Express Root Port (rev 01)
[27]:00:16.7 PCI bridge: VMware PCI Express Root Port (rev 01)
[28]:00:17.0 PCI bridge: VMware PCI Express Root Port (rev 01)
[29]:00:17.1 PCI bridge: VMware PCI Express Root Port (rev 01)
[30]:00:17.2 PCI bridge: VMware PCI Express Root Port (rev 01)
[31]:00:17.3 PCI bridge: VMware PCI Express Root Port (rev 01)
[32]:00:17.4 PCI bridge: VMware PCI Express Root Port (rev 01)
[33]:00:17.5 PCI bridge: VMware PCI Express Root Port (rev 01)
[34]:00:17.6 PCI bridge: VMware PCI Express Root Port (rev 01)
[35]:00:17.7 PCI bridge: VMware PCI Express Root Port (rev 01)
[36]:00:18.0 PCI bridge: VMware PCI Express Root Port (rev 01)
[37]:00:18.1 PCI bridge: VMware PCI Express Root Port (rev 01)
[38]:00:18.2 PCI bridge: VMware PCI Express Root Port (rev 01)
[39]:00:18.3 PCI bridge: VMware PCI Express Root Port (rev 01)
[40]:00:18.4 PCI bridge: VMware PCI Express Root Port (rev 01)
[41]:00:18.5 PCI bridge: VMware PCI Express Root Port (rev 01)
[42]:00:18.6 PCI bridge: VMware PCI Express Root Port (rev 01)
[43]:00:18.7 PCI bridge: VMware PCI Express Root Port (rev 01)
[44]:03:00.0 Ethernet controller: VMware VMXNET3 Ethernet Controller (rev 01)
[45]:[root@OEL72-59-177 ~]#
****************************
&&&&&&&&&lspci[12]&&&&&&&&&
############read number###########58########################
############read number###########12########################
############read number###########35########################
############read number###########260########################
#######################timeout#####################
find /home
:[14]
****************************
[0]:Last login: Tue Mar 6 19:11:59 2018 from 172.17.58.110
[1]:find /home
[2]:[root@OEL72-59-177 ~]# find /home
[3]:/home
[4]:/home/nick-obj-rep-59-228-exp
[5]:/home/razor
[6]:/home/razor/.bash_logout
[7]:/home/razor/.bash_profile
[8]:/home/razor/.bashrc
[9]:/home/razor/.mozilla
[10]:/home/razor/.mozilla/extensions
[11]:/home/razor/.mozilla/plugins
[12]:/home/razor/.bash_history
[13]:[root@OEL72-59-177 ~]#
****************************
&&&&&&&&&find /home[10]&&&&&&&&&
############read number###########58########################
############read number###########10########################
############read number###########33########################
############read number###########1947########################
############read number###########930########################
#######################timeout#####################
lslogins
:[53]
****************************
[0]:Last login: Tue Mar 6 19:12:09 2018 from 172.17.58.110
[1]:lslogins
[2]:[root@OEL72-59-177 ~]# lslogins
[3]: UID USER PROC PWD-LOCK PWD-DENY LAST-LOGIN GECOS
[4]: 0 root 158 0 0 19:12:20 root
[5]: 1 bin 0 0 1 bin
[6]: 2 daemon 0 0 1 daemon
[7]: 3 adm 0 0 1 adm
[8]: 4 lp 0 0 1 lp
[9]: 5 sync 0 0 1 sync
[10]: 6 shutdown 0 0 1 2017-Mar15 shutdown
[11]: 7 halt 0 0 1 halt
[12]: 8 mail 0 0 1 mail
[13]: 11 operator 0 0 1 operator
[14]: 12 games 0 0 1 games
[15]: 14 ftp 0 0 1 FTP User
[16]: 26 postgres 7 0 1 PostgreSQL Server
[17]: 29 rpcuser 0 0 1 RPC Service User
[18]: 32 rpc 0 0 1 Rpcbind Daemon
[19]: 38 ntp 0 0 1
[20]: 42 gdm 0 0 1
[21]: 59 tss 0 0 1 Account used by the trousers p
[22]: 70 avahi 0 0 1 Avahi mDNS/DNS-SD Stack
[23]: 74 sshd 0 0 1 Privilege-separated SSH
[24]: 75 radvd 0 0 1 radvd user
[25]: 81 dbus 0 0 1 System message bus
[26]: 89 postfix 1 0 1
[27]: 99 nobody 0 0 1 Nobody
[28]: 107 qemu 0 0 1 qemu user
[29]: 113 usbmuxd 0 0 1 usbmuxd user
[30]: 170 avahi-autoipd
[31]: 0 0 1 Avahi IPv4LL Stack
[32]: 171 pulse 0 0 1 PulseAudio System Daemon
[33]: 172 rtkit 0 0 1 RealtimeKit
[34]: 173 abrt 0 0 1
[35]: 177 dhcpd 0 0 1 DHCP server
[36]: 990 gnome-initial-setup
[37]: 0 0 1
[38]: 991 unbound 0 0 1 Unbound DNS resolver
[39]: 992 colord 0 0 1 User for colord
[40]: 993 setroubleshoot
[41]: 0 0 1
[42]: 994 saslauth 0 0 1 Saslauthd user
[43]: 995 chrony 0 0 1
[44]: 996 geoclue 0 0 1 User for geoclue
[45]: 997 polkitd 0 0 1 User for polkitd
[46]: 998 systemd-network
[47]: 0 0 1 systemd Network Management
[48]: 999 systemd-bus-proxy
[49]: 0 0 1 systemd Bus Proxy
[50]: 1000 razor 0 0 0
[51]:65534 nfsnobody 0 0 1 Anonymous NFS User
[52]:[root@OEL72-59-177 ~]#
****************************
&&&&&&&&&lslogins[10]&&&&&&&&&三月八日 等待变化等待机会
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <openssl/evp.h> #include <openssl/rsa.h> #include <openssl/err.h> #include <openssl/bio.h> #define HANDLE_ERR(func)\ printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error())); goto clear; #define HANDLE_FAIL(func)\ printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error()));continue; int main() { ERR_load_crypto_strings(); EVP_PKEY_CTX *ctx = NULL; BIO* bio = NULL; EVP_PKEY *pkey = NULL; int result = -1; bio = BIO_new_fp(stdout, BIO_NOCLOSE); if (bio == NULL) { HANDLE_ERR(bio); } pkey = EVP_PKEY_new(); if (pkey == NULL) { HANDLE_ERR(EVP_PKEY_new); } int algoArray[] = {EVP_PKEY_RSA, EVP_PKEY_RSA2, EVP_PKEY_DSA, EVP_PKEY_DSA1, EVP_PKEY_DSA2, EVP_PKEY_DSA3, EVP_PKEY_DSA4, EVP_PKEY_DH, EVP_PKEY_EC}; for (int algo = 0; algo < sizeof(algoArray)/sizeof(algoArray[0]); algo++) { if (ctx) { EVP_PKEY_CTX_free(ctx); ctx = NULL; } ctx = EVP_PKEY_CTX_new_id(algoArray[algo], NULL); if (!ctx) { HANDLE_FAIL(EVP_PKEY_CTX_new); } if (EVP_PKEY_keygen_init(ctx) <= 0) { HANDLE_FAIL(EVP_PKEY_keygen_init); } const EVP_MD * mdArray[] = {EVP_sha(), EVP_sha1(),EVP_sha224(), EVP_sha256(), EVP_sha384(), EVP_sha512()}; for (int md = 0; md < sizeof(mdArray)/sizeof(mdArray[0]); md ++) { if (EVP_PKEY_CTX_ctrl(ctx, algoArray[algo],EVP_PKEY_OP_KEYGEN, EVP_PKEY_CTRL_MD, 0, (void*)mdArray[md])<=0) { HANDLE_FAIL(EVP_PKEY_CTX_ctrl); } int bitsArray[] = {256, 1024, 2048, 4096}; for (int bits = 0; bits < sizeof(bitsArray)/sizeof(bitsArray[0]); bits ++) { if (EVP_PKEY_CTX_ctrl(ctx, algoArray[algo],EVP_PKEY_OP_KEYGEN,EVP_PKEY_CTRL_RSA_KEYGEN_BITS, bitsArray[bits], NULL)<=0) { HANDLE_FAIL(EVP_PKEY_CTX_ctrl); } int padArray[]={RSA_PKCS1_PADDING, RSA_SSLV23_PADDING, RSA_PKCS1_OAEP_PADDING, RSA_X931_PADDING, RSA_PKCS1_PSS_PADDING}; for (int pad = 0; pad<= sizeof(padArray)/sizeof(padArray[0]); pad++) { if (EVP_PKEY_CTX_ctrl(ctx, algoArray[algo],EVP_PKEY_OP_KEYGEN,EVP_PKEY_CTRL_RSA_PADDING, padArray[pad], NULL)<=0) { HANDLE_FAIL(EVP_PKEY_CTX_ctrl); } if (EVP_PKEY_keygen(ctx, &pkey)<=0) { HANDLE_FAIL(EVP_PKEY_keygen); } BIO_printf(bio, "success: algoArray[%d]mdArray[%d]bitsArray[%d]padArraypadArray[%d]\n", algo, md, bits, pad);; } } } } clear: if (bio) { BIO_free(bio); } if (pkey) { EVP_PKEY_free(pkey); } if (ctx) { EVP_PKEY_CTX_free(ctx); } return 0; }
三月十日 等待变化等待机会
使用libssh2读取我的shell的时候出现了一些不可读的字符,我一开始以为是什么数据的corrupt的问题,查找了一下其实是shell的颜色的字符,这个也算是一个小小的常识吧,可惜我知道的太少了。三月十一日 等待变化等待机会
我购买了我最喜欢的电视剧<Guild>的DVD,准备抓下来保存: for var in `ls /media/nick/THEGUILDS1/VIDEO_TS/VTS_0*_[1,2].VOB`; do index=`echo ${var}|grep -Eo '([0-9_]{5})'`; ffmpeg -y -i ${var} -vcodec h264 -acodec aac -filter_complex "[0:v][0:s]overlay" video${index}.mp4; done
#!/bin/bash
season=2
for var in `find /media/nick -type f -name "VTS_*.VOB" -size +1M`
do
index=`echo ${var}|grep -Eo '([0-9_]{5})'`
hasSub=`ffmpeg -i ${var} -c copy -map 0:s -f null - -v 0 -hide_banner && echo $? || echo $?`
if [ ${hasSub} == 0 ];
then `ffmpeg -y -i ${var} -vcodec h264 -acodec aac -max_muxing_queue_size 999 -filter_complex "[0:v][0:s]overlay" /home/nick/volume1/video/guild/season${season}/video${index}.mp4`
else `ffmpeg -y -i ${var} -vcodec h264 -acodec aac -max_muxing_queue_size 999 /home/nick/volume1/video/guild/season${season}/video${index}.mp4`
fi
donefiles=$(find . -name "VTS_*.VOB" -printf '"%h/%f" ');for f in "$files"; do echo "${f}"; doneThe empty string for the delimiter means 'use the zero byte, ASCII NUL, as the delimiter' and is appropriate for parsing 'find ... -print0' output.现在我发现这个while read -d ''对于目录名有空格似乎不起作用,难道只是对于文件名有空格才有效?
find . -name "VTS_*.VOB" -type f| while read -d '' file;
do echo "<<$file>>"; done三月十二日 等待变化等待机会
我的扫描仪怎么工作呢?我始终无法正确设置wifi,于是只能使用usb连线然后在命令行下扫描:hp-scan -dhpaio:/usb/Deskjet_2540_series?serial=CN48K475BT0604 -mcolor --dest=pdf -o./wire2.pdf三月十四日 等待变化等待机会
我的确是陷入了迷茫,因为很简单的下载/更新了以前就下载的libcss。我简单的尝试了test程序检验是否是加密的,看起来不是,不过也许这个简单的测试过于乐观?总之,我看到了handbrake是使用了dvdread/dvdnav,而ffmpeg没有,我也看到有人希望集成这个但是没有相应。查看handbrake的代码似乎怎么使用很不明显,或者说代码写的是很艺术的,我没有找到直接检验dvd格式调用读的方法的代码。
for title in {2..25};
do
./HandBrakeCLI -e x264 -E av_aac -i /dev/sr0 -o ~/volume1/video/guild/season3/video_title_${title}.mp4 -Z "High Profile" -s 1 --subtitle-burned 1 --subtitle-default 1 -t ${title};
done三月十五日 等待变化等待机会
在普通人眼里dvd加密似乎是很平常的事情,从计算机的角度来看对于任何的发明都不是那么凭直觉就能想到的。这里的关于css的解说让人大开眼界,从数学算法来解释,以及代码的实践,这个是我在看libdvdcss之前的热身。我记得很久以前跟踪libdvdread的时候总是爆出一些错误,也许这个是很多年前的问题了。三月十七日 等待变化等待机会
我厚颜无耻的把这个网站的相关dvd css网页抓下来据为己有,只是个人收藏,绝无侵权剽窃的企图。我一时还找不到更好的办法就参考这里的代码wget --spider --force-html -r -l2 $url 2>&1 \
| grep '^--' | awk '{ print $3 }' \
| grep -v '\.\(css\|js\|png\|gif\|jpg\)$' \
> urls.m3uwget -nd -p --clobber --convert-links -i .urls.m3u其中--clobber我是最疑惑的,我对于--no-clobber的理解似乎正好相反,总之-nd禁止产生目录,-p是什么?我居然没有找到!
三月二十一日 等待变化等待机会
我应该温故而知新,重新读自己的笔记再次理解,其实以我现在的记忆力再读一次和第一次几乎一样。三月二十三日 等待变化等待机会
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <openssl/evp.h> #include <openssl/rsa.h> #include <openssl/err.h> #include <openssl/bio.h> #define HANDLE_ERR(func)\ printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error())); goto clear; #define HANDLE_FAIL(func)\ printf("%s[%d]: %s\n", #func, __LINE__, ERR_reason_error_string(ERR_get_error()));continue; void keyTest(const unsigned char* msg, unsigned int nsize, unsigned char* retBuf, unsigned int* retsize) { ERR_load_crypto_strings(); int nmethod = NID_md5_sha1; BIO* bio = NULL; BIGNUM *bn = NULL; RSA* rsa = NULL; int nbits = 1024; bio = BIO_new_fp(stdout, BIO_NOCLOSE); if (bio==NULL) { HANDLE_ERR(BIO_new); } rsa = RSA_new_method(NULL); if (rsa == NULL) { HANDLE_ERR(RSA_new); } bn = BN_new(); if (bn == NULL) { HANDLE_ERR(BN_new); } if (BN_set_word(bn, RSA_F4)<=0)[1] { HANDLE_ERR(BN_set_word); } if (RSA_generate_key_ex(rsa, nbits, bn, NULL)<=0)[2] { HANDLE_ERR(RSA_generate_key_ex); } if (RSA_check_key(rsa)<=0) { HANDLE_ERR(RSA_check_key); } if (RSA_print(bio, rsa, 4)<=0) { HANDLE_ERR(RSA_print); } if (RSA_sign(nmethod, msg, nsize, retBuf, retsize, rsa) <= 0) { HANDLE_ERR(RSA_sign); } if (RSA_verify(nmethod, msg, nsize, retBuf, *retsize, rsa) <= 0) { HANDLE_ERR(RSA_verify); } clear: if (bio) { BIO_free(bio); } if (bn) { BN_free(bn); } if (rsa) { RSA_free(rsa); } } int main() { unsigned char msg[36];[3] unsigned char buf[256]; int size = sizeof(buf); for (size_t i = 0; i < sizeof(msg); i++) { msg[i] = i; } keyTest(msg, sizeof(msg), buf, &size); printf("size: %u\n", size); for (size_t i = 0; i < size; i ++) { printf("%02X", buf[i]); } return 0; }
三月二十八日 等待变化等待机会
使用dnsmasq作为dhcp服务器有一个最低要求,我使用这个命令行参数配合dhcping来测试功能:sudo dnsmasq -d --dhcp-range=192.168.1.116,192.168.1.116,24h --dhcp-authoritative --port=0 --bind-interface --interface=eth0 其中--port=0是必要的因为我不想要dns服务,--dhcp-range也是必要的,我还不知道有什么替代的方法。三月二十九日 等待变化等待机会
今天遇到了uefi模式下ipxe不能正常启动的问题,我怀疑是ipxe的问题,决定重新编译,首先,git的proxy的设置需要这样做:四月二日 等待变化等待机会
今天研究了一下razor里面编译microkernel的过程,这个也只有旧版的帮助写的清楚,最新版的我又看不懂了。大体上是依靠标准的livecd-tool来先制作一个livecd然后有另一个工具叫做livecd-iso-to-pxeboot把iso转换成为pxe的启动文件,其实就是文件系统和initrd,不过其中在很多包的配置中加入了一个razor的client,这个是一个不太透明的东西我还没有搞明白,不过应该就是使用factor或者lspci/lshw之类的吧?我实践了一小步就是使用qemu直接启动iso,因为模拟pxe启动还需要再学习。这个第一步居然就让我头疼了好一会儿,因为我连qemu的部分模拟和全模拟都不清楚。这个地方我读了两三次都没有意识到自己的问题: qemu-system-x86_64 -boot d -cdrom ./microkernel.iso 然后就是很弱智的问题,鼠标被锁在模拟器里怎么取出来?我以前应该使用的都是sdl的环境只记得是ctrl+shft,遇到ftk这个是ctl+shft+G。这么基本的问题都不清楚说明你还嫩的很。就像这几天我对于synology的nfs的权限设置都搞不清楚,以后都不敢和别人提我曾经给nas输出管理api了。实在是无地自容,因为我还是不明白我的android手机在mount nfs的时候使用的用户到底是什么呢?能够看到文件名但是不能读取文件播放视频文件?四月七日 等待变化等待机会
#include <iostream>
#include <fstream>
#include <sstream>
#include <cstring>
#include <cstdlib>
#include <vector>
#include <htmlcxx/html/ParserDom.h>
#include <sys/dir.h>
using namespace std;
using namespace htmlcxx::HTML;
bool getString(const string& strFile, string& strContent)
{
ifstream ifs(strFile.c_str(), ifstream::in);
if (ifs.good())
{
stringstream ss;
ss << ifs.rdbuf();
strContent = ss.str();
return true;
}
return false;
}
bool setString(const string& strFile, const string& strContent)
{
ofstream ofs(strFile.c_str(), ifstream::out|ifstream::trunc);
if (ofs.good())
{
ofs<< strContent;
return true;
}
return false;
}
bool addAds(const string& strFile, const string& strAds)
{
string strContent;
if (getString(strFile, strContent))
{
ParserDom dom;
const tree<Node>& tr = dom.parseTree(strContent);
for (tree<Node>::pre_order_iterator it = tr.begin(); it != tr.end(); it++)
{
if (it->isTag() && it->tagName().compare("head") == 0)
{
size_t pos = strContent.find_first_of('>', it->offset());
if (pos != string::npos)
{
if (strContent.substr(pos+1, strAds.size()).compare(strAds) != 0)
{
strContent.insert(pos+1, strAds);
return setString(strFile, strContent);
}
}
}
}
}
return false;
}
bool removeAds(const string& strFile, const string& strAds)
{
string strContent;
if (getString(strFile, strContent))
{
ParserDom dom;
const tree<Node>& tr = dom.parseTree(strContent);
for (tree<Node>::pre_order_iterator it = tr.begin(); it != tr.end(); it++)
{
if (it->isTag() && it->tagName().compare("head") == 0)
{
size_t pos = strContent.find_first_of('>', it->offset());
if (pos != string::npos)
{
if (strContent.substr(pos+1, strAds.size()).compare(strAds) == 0)
{
strContent.erase(pos+1, strAds.size());
return setString(strFile, strContent);
}
}
}
}
}
return false;
}
bool isHtml(const string& strName)
{
size_t pos = strName.find_last_of('.');
if (pos != string::npos)
{
const string& strExt = strName.substr(pos+1);
if (strcasecmp(strExt.c_str(), "html") == 0 || strcasecmp(strExt.c_str(), "htm") == 0)
{
return true;
}
}
return false;
}
bool isForbidden(const string& strDir)
{
if (strDir.compare("personal") == 0 || strDir.compare("generatedTrees") == 0)
{
return true;
}
return false;
}
bool doGetAllFiles(const string& strPath, vector<string>& vect)
{
DIR *dir;
if ((dir = opendir(strPath.c_str())) != NULL)
{
struct dirent *ent;
while ((ent = readdir(dir)) != NULL)
{
switch (ent->d_type)
{
case DT_DIR:
if (strcmp(ent->d_name, ".") != 0 && strcmp(ent->d_name, "..") != 0)
{
if (!isForbidden(ent->d_name))
{
if (!doGetAllFiles(strPath+"/"+ ent->d_name, vect))
{
return false;
}
}
}
break;
case DT_REG:
if (isHtml(ent->d_name))
{
vect.push_back(strPath+"/"+ent->d_name);
}
break;
default:
break;
}
}
closedir(dir);
}
else
{
perror (strPath.c_str());
return false;
}
return true;
}
bool getAllFiles(const string& strPath, vector<string>& vect)
{
char path[PATH_MAX+1];
if (realpath(strPath.c_str(), path))
{
return doGetAllFiles(path, vect);
}
return false;
}
bool doSearchAds(const string& strFile)
{
string strContent;
if (getString(strFile, strContent))
{
ParserDom dom;
const tree<Node>& tr = dom.parseTree(strContent);
for (tree<Node>::pre_order_iterator it = tr.begin(); it != tr.end(); it++)
{
if (it->isTag() && it->tagName().compare("script") == 0)
{
if (it->text().find("google")!= string::npos)
{
cout << "filename:"<< strFile << " text:" << it->text() << endl;
}
}
}
}
return false;
}
bool doSearchAllFiles(const string& strPath)
{
DIR *dir;
if ((dir = opendir(strPath.c_str())) != NULL)
{
struct dirent *ent;
while ((ent = readdir(dir)) != NULL)
{
string strNewPath = strPath+"/" + ent->d_name;
switch (ent->d_type)
{
case DT_DIR:
if (strcmp(ent->d_name, ".") != 0 && strcmp(ent->d_name, "..") != 0)
{
if (!isForbidden(ent->d_name))
{
if (!doSearchAllFiles(strNewPath))
{
return false;
}
}
}
break;
case DT_REG:
if (isHtml(ent->d_name))
{
doSearchAds(strNewPath);
}
break;
default:
break;
}
}
closedir(dir);
}
else
{
perror (strPath.c_str());
return false;
}
return true;
}
bool searchAds(const string& strPath)
{
char path[PATH_MAX+1];
if (realpath(strPath.c_str(), path))
{
return doSearchAllFiles(path);
}
return false;
}
bool test2(const string& strPath)
{
vector<string> vect;
if (getAllFiles(strPath, vect))
{
for (size_t i =0; i < vect.size(); i ++)
{
cout << vect[i] << endl;
}
cout << "total file number: " << vect.size() << endl;
return true;
}
return false;
}
bool test1(const string& strFileName)
{
const string strAdsFile="/home/nick/googleads.txt";
string strAds;
string strOldContent, strNewContent;
if (getString(strAdsFile, strAds))
{
if (getString(strFileName, strOldContent))
{
if (addAds(strFileName, strAds))
{
if (removeAds(strFileName, strAds))
{
if (getString(strFileName, strNewContent))
{
if (strOldContent.compare(strNewContent) == 0)
{
cout << "content remain unchanged" << endl;
return true;
}
}
}
}
}
}
return false;
}
bool test3(const string& strFileName)
{
const string strAdsFile="/home/nick/googleads.txt";
string strAds;
string strOldContent, strNewContent;
if (getString(strAdsFile, strAds))
{
if (getString(strFileName, strOldContent))
{
if (addAds(strFileName, strAds))
{
if (removeAds(strFileName, strAds))
{
if (getString(strFileName, strNewContent))
{
if (strOldContent.compare(strNewContent) == 0)
{
cout << "content remain unchanged" << endl;
return true;
}
}
}
}
}
}
return false;
}
int myAddAds(const string& strPath, const string& strAdsFile)
{
int result = 0;
string strAds;
if (getString(strAdsFile, strAds))
{
vector<string> vect;
if (getAllFiles(strPath, vect))
{
for (size_t i =0; i < vect.size(); i ++)
{
if (addAds(vect[i], strAds))
{
cout << vect[i] << endl;
result ++;
}
}
}
}
return result;
}
int main(int argc, char** argv)
{
if (argc != 3)
{
cout << "usage: " << argv[0] << " <diabloPath> <googleads>" << endl;
return -1;
}
cout << myAddAds(argv[1], argv[2]) << endl;
return 0;
}/volume1/photo *(rw,async,no_wdelay,insecure,no_root_squash,insecure_locks,sec=sys,anonuid=1000,anongid=1000) /volume1/music *(rw,async,no_wdelay,insecure,no_root_squash,insecure_locks,sec=sys,anonuid=1000,anongid=1000) /volume1/DiskStation *(rw,async,no_wdelay,crossmnt,insecure,no_root_squash,insecure_locks,sec=sys,anonuid=1000,anongid=1000) /volume1/video *(rw,async,no_wdelay,crossmnt,insecure,no_root_squash,insecure_locks,sec=sys:krb5:krb5i:krb5p,anonuid=1000,anongid=1000)因为synology创建的用户id从1026开始和我的ubuntu的1000不同,所以,我只好修改/etc/passwd的我的id,当然需要修改文件。我依然不知道这个做法是否正确。
四月八日 等待变化等待机会
我搞不太明白googleads的做法,难道是因为aws/s3/static website不支持script的原因吗?我的小修小改的小程序。这个是我的私心我想尽可能的增加html文件的数目以便增加广告位置。四月十日 等待变化等待机会
无耻的剽窃linux的manpage,大概是想赚点钱希望googleads能够支撑这个网站的aws的费用。wget -k -p -r --no-parent --no-clobber http://man7.org/linux/man-pages/四月十一日 等待变化等待机会
我的nfs的文件系统有这个问题就是readdir返回的dirent的st_mode值为DT_UNKNOWN的问题,我一开始以为是nfs的实现的问题,后来再读这个部分才意识到这个是一个典型的问题。这一段话我也在manpage里读了,却似乎是清风拂面完全没有意识这个充分说明了我没有文件系统实现的概念所以才没有立刻意识到这个问题的实质:Currently, only some filesystems (among them: Btrfs, ext2, ext3, and ext4) have full support for returning the file type in d_type. All applications must properly handle a return of DT_UNKNOWN.这里所做的进一步的解说是可以帮助你理解的。后来我修改我的代码大概的样子和这里是类似的,当然明白了其中的道理
Some filesystems, like EXT4 I think, and very recent XFS (with the new metadata version), keep type info in the directory, so it can be returned without having to load the inode from disk. This is a huge speedup for find -name: it doesn't have to stat anything to recurse through subdirs. But for filesystems that don't do this, d_type will always be DT_UNKNOWN, because filling it in would require reading all the inodes (which might not even be loaded from disk).
The lowest-level portable way (portable to POSIX systems), is to use the libc functions to open a directory and read the entries. POSIX doesn't specify the exact system call interface, unlike for non-directory files.
bool doGetAllFiles(const string& strPath, vector<string>& vect)
{
DIR *dir;
if ((dir = opendir(strPath.c_str())) != NULL)
{
struct dirent *ent;
while ((ent = readdir(dir)) != NULL)
{
string str = strPath+"/" +ent->d_name;
bool bFile = false;
bool bDirectory = false;
struct stat st;
if (strcmp(ent->d_name, ".") == 0 || strcmp(ent->d_name, "..") == 0)
{
continue;
}
switch (ent->d_type)
{
case DT_DIR:
bDirectory = true;
break;
case DT_REG:
bFile = true;
break;
case DT_UNKNOWN:
if (stat(str.c_str(), &st) < 0)
{
return false;
}
if (S_ISREG(st.st_mode))
{
bFile = true;
}
else
{
if (S_ISDIR(st.st_mode))
{
bDirectory = true;
}
}
break;
default:
break;
}
if (bFile && isHtml(ent->d_name))
{
vect.push_back(str);
}
if (bDirectory && !isForbidden(ent->d_name))
{
if (!doGetAllFiles(str, vect))
{
return false;
}
}
}
closedir(dir);
}
else
{
perror (strPath.c_str());
return false;
}
return true;
}四月十七日 等待变化等待机会
我试图编译最新版的vlc但是卡在它的configure上抱怨我的编译器不支持c++11,c++0x这个让我丈二和尚摸不着头脑,首先我的编译器是gcc4.8不存在不支持的问题,因为使用-std=c++0x是可以支持的。那么只有检查configure的代码,这个确实是有难度,有人抱怨--verbose不起作用,我也一头雾水不知怎么才能debug configure,后来才看到有config.log来检查,发现出错是这个。看来这个是gcc4.8的问题,无法逃避只好把有关max_align_t的测试部分注释掉。四月十九日 等待变化等待机会
这里是我对于wget-1.15的一个微不足道的改动,因为我要保持临时文件的后缀名。
diff --git a/src/utils.c b/src/utils.c
index 4354668..4e48592 100644
--- a/src/utils.c
+++ b/src/utils.c
@@ -623,20 +623,42 @@ file_size (const char *filename)
/* stat file names named PREFIX.1, PREFIX.2, etc., until one that
doesn't exist is found. Return a freshly allocated copy of the
unused file name. */
-
+#define MAX_EXTENSION_LENGTH 8
static char *
unique_name_1 (const char *prefix)
{
int count = 1;
int plen = strlen (prefix);
char *template = (char *)alloca (plen + 1 + 24);
+ char extention_name[MAX_EXTENSION_LENGTH] = {0};
char *template_tail = template + plen;
memcpy (template, prefix, plen);
- *template_tail++ = UNIQ_SEP;
+
+ while (template_tail != template && *template_tail != UNIQ_SEP)
+ {
+ template_tail--;
+ }
+ int size = template + plen - template_tail;
+ if (*template_tail == UNIQ_SEP && size < MAX_EXTENSION_LENGTH)
+ {
+ memcpy(extention_name, template_tail, size);
+ }
+ else
+ {
+ template_tail = template + plen;
+ }
+
+ if (*template_tail != UNIQ_SEP)
+ {
+ *template_tail++ = UNIQ_SEP;
+ }
do
- number_to_string (template_tail, count++);
+ {
+ number_to_string (template_tail, count++);
+ strcat(template_tail, extention_name);
+ }
while (file_exists_p (template));
return xstrdup (template);#define MAX_EXTENSION_LENGTH 8 static char * unique_name_1 (const char *prefix) { int count = 1; int plen = strlen (prefix); char *template = (char *)alloca (plen + 1 + 24); char extention_name[MAX_EXTENSION_LENGTH] = {0}; char *template_tail = template + plen; memcpy (template, prefix, plen); while (template_tail != template && *template_tail != UNIQ_SEP) { template_tail--; } int size = template + plen - template_tail; if (*template_tail == UNIQ_SEP && size < MAX_EXTENSION_LENGTH) { memcpy(extention_name, template_tail, size); } else { template_tail = template + plen; } if (*template_tail != UNIQ_SEP) { *template_tail++ = UNIQ_SEP; } do { number_to_string (template_tail, count++); strcat(template_tail, extention_name); } while (file_exists_p (template)); return xstrdup (template); }
wget -nd -k -p -r --no-parent --no-clobber http://www.cplusplus.com/referencewww.staroceans.org/cplusplus/index.html
四月二十六日 等待变化等待机会
我发现我经常误会我的apt-get source失败,因为dpkg-source -x会长时间挂起,我一开始以为有什么错误,后来才意识到我是在我的nfs mount的目录下操作,文件读写非常的慢。我的测试是这样子的: time dd if=/dev/zero of=/BigDisk/nfstest.zero bs=16k count=16384发现需要大概5秒多,而在本地硬盘上时间是不到十分之一。于是我开始寻找优化nfs的方法:我尝试了如下方法/home/nick/laptop from 192.168.1.116:/home/nick/workspace
Flags: rw,relatime,vers=4.0,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,port=0,timeo=600,retrans=2,sec=sys,clientaddr=192.168.1.115,local_lock=none,addr=192.168.1.116
CXXFLAGS = -O0 -g -Wall -fmessage-length=0 -I/usr/include/webkitgtk-1.0 -I/usr/include/glib-2.0 -I/usr/lib/x86_64-linux-gnu/glib-2.0/include
LIBS = -lwebkitgtk-1.0四月二十九日 等待变化等待机会
我煞费苦心的要改代码为wget添加适当的文件扩展名发现代码里居然已经有这个选项-E,这个真是有画蛇添足的嫌疑。另一个问题是当我修改了我的mtu的时候我无法再使用ssh。所以,只能修改回sudo ip link set mtu 1500 dev eth0五月三日 等待变化等待机会
此事说来话长,我一直想使用libv8或者使用webkit来parsing/run,其中js是一个难点,对于怎么使用我是一头雾水不知如何入手。因此想尝试一下google的开发流程。下载的过程就是相当的复杂,因为要全套使用google的开发工具包和从前的做法很不一样。我在我的nfs的文件目录下始终都出现权限问题,我是在sudo下居然还有权限问题不能chdir这个真实莫名其妙后来只好把目录拷贝的本地的磁盘上才行。然后需要安装需要的开发工具:./install-build-deps.sh --no-arm --no-chromeos-fonts --no-nacl因为默认的安装很多32位操作系统下的软件包很麻烦。五月十日 等待变化等待机会
我经常会遇到在bootstrap/configure后发生"definition of this LT_INIT comes from libtool 2.4.2"的错误,这个时候需要的是autoreconf -fi。实际上我最后并没有彻底解决问题,我怀疑是我的libtool被降级之后的问题,折腾了许久我只好下载最新版的libtool源代码编译安装,当然首先是卸载了我自己的。五月十一日 等待变化等待机会
一个看似简单的问题,让我感到惭愧,就是怎样直接呼叫convertion operator,不是constructor,比如你的定义是这样子的:class Foo{public:operator std::string ()const {return "It is my name, idiot!";}};怎样呼叫你的名字呢?Foo fool; cout << fool.operator std::string()<<endl;五月十六日 等待变化等待机会
本来我对于改造ipmitool充满了期待,然而深入探索sensor的代码才意识到它的global variable大多是埋藏在函数内的static变量,这个仿佛是隐藏的全局变量,它的直接结果是函数的不可重入,我一开始的想法是把这些变量放在intf这样一个不透明的所谓context结构里,仿佛opengl的经典设计,但是传出参数如果不是用户自己的内存同样解决不了函数的reentrable的问题。因此这种改造是伤筋动骨的大动作,不是我所愿意或者当前有能力的,不是说不可能,而是我没有这个时间精力去实施。五月二十二日 等待变化等待机会
对于ffmpeg不支持mp3的问题似乎是老生长谈,我不知道这么简单的问题我似乎也在不断重复,因为我也记不清楚是否已经不止一次遇到。究其原因是版权的问题,因为mp3是有专利的,如同开源社区对于所有这类问题一样ffmpeg是不会正式的把libmp3lame编译进去的,所以,所谓的安装额外的包是不可能解决这个问题的,只有源代码从头编译,至于说具体的配置,也许是一个小细节,我一开始居然忘了:既然知道这个是版权的问题,肯定你要支持gpl和non-free,否则又何必重新编译,添加enable-libmp3lame并不是问题,问题是如果不是动态库又何谈什么gpl,我也是很惭愧对于gpl之类的法律相关的协议始终记不清楚,可是忘记动态库实在是不应当:./configure --enable-gpl --enable-version3 --enable-nonfree \
--enable-postproc --enable-libmp3lame \
--enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libtheora \
--enable-libvorbis --enable-libx264 --enable-libxvid --enable-shared --disable-static \
--enable-libass --enable-libbluray --enable-libopenjpeg --enable-libfreetype \
--enable-libfontconfig --enable-gmp --enable-librsvg --enable-libtesseractffmpeg -i ~/volume1/video/YesMinister/OpenGovernment.m4v -c:a:0 libmp3lame -b 48000 -vn -sn /tmp/output.mp3
for var in `ls *.m4v`; do name=`echo ${var}|grep -Eoi "^.*[^.]{5}"`; ffmpeg -i ./${var} -c:a:0 libmp3lame -b 48000 -vn -sn ${name}.mp3 ; done五月三十日 等待变化等待机会
/*
============================================================================
Name : ipmiToolTest.c
Author : nick
Version :
Copyright : Your copyright notice
Description : Hello World in C, Ansi-style
============================================================================
*/
#include <stdio.h>
#include <stdlib.h>
#include "ipmitool/ipmi_intf.h"
#include "ipmitool/log.h"
int verbose = 0;
int csv_output = 0;
int main(void)
{
static struct ipmi_intf * ipmi_main_intf = NULL;
int privlvl = IPMI_SESSION_PRIV_ADMIN;
int retry = 1;
uint32_t timeout = 15;
int authtype = IPMI_SESSION_AUTHTYPE_MD5;
char * hostname = "192.168.1.135";
char * username = "admin";
char * password = "admin";
char * intfname = "lan";
char * progname = NULL;
char * oemtype = NULL;
int cipher_suite_id = 4; /* See table 22-19 of the IPMIv2 spec */
/* load interface */
ipmi_main_intf = ipmi_intf_load(intfname);
if (ipmi_main_intf == NULL) {
lprintf(LOG_ERR, "Error loading interface %s", intfname);
goto out_free;
}
/* setup log */
log_init(progname, 0, verbose);
/* run OEM setup if found */
if (oemtype != NULL &&
ipmi_oem_setup(ipmi_main_intf, oemtype) < 0) {
lprintf(LOG_ERR, "OEM setup for \"%s\" failed", oemtype);
goto out_free;
}
/* set session variables */
if (hostname != NULL)
ipmi_intf_session_set_hostname(ipmi_main_intf, hostname);
if (username != NULL)
ipmi_intf_session_set_username(ipmi_main_intf, username);
if (password != NULL)
ipmi_intf_session_set_password(ipmi_main_intf, password);
if (authtype >= 0)
ipmi_intf_session_set_authtype(ipmi_main_intf, (uint8_t)authtype);
if (privlvl > 0)
ipmi_intf_session_set_privlvl(ipmi_main_intf, (uint8_t)privlvl);
else
ipmi_intf_session_set_privlvl(ipmi_main_intf,
IPMI_SESSION_PRIV_ADMIN); /* default */
/* Adding retry and timeout for interface that support it */
if (retry > 0)
ipmi_intf_session_set_retry(ipmi_main_intf, retry);
if (timeout > 0)
ipmi_intf_session_set_timeout(ipmi_main_intf, timeout);
ipmi_intf_session_set_cipher_suite_id(ipmi_main_intf, cipher_suite_id);
struct ipmi_rs * rsp;
struct ipmi_rq req;
uint8_t data[256];
memset(data, 0, sizeof(data));
memset(&req, 0, sizeof(req));
req.msg.netfn = IPMI_NETFN_APP;
req.msg.lun = 0;
req.msg.cmd = 0x01;
req.msg.data = data;
rsp = ipmi_main_intf->sendrecv(ipmi_main_intf, &req);
if (rsp == NULL) {
lprintf(LOG_ERR, "Unable to send RAW command "
"(channel=0x%x netfn=0x%x lun=0x%x cmd=0x%x)",
ipmi_main_intf->target_channel & 0x0f, req.msg.netfn, req.msg.lun, req.msg.cmd);
goto out_free;
}
if (rsp->ccode > 0) {
lprintf(LOG_ERR, "Unable to send RAW command "
"(channel=0x%x netfn=0x%x lun=0x%x cmd=0x%x rsp=0x%x): %s",
ipmi_main_intf->target_channel & 0x0f, req.msg.netfn, req.msg.lun, req.msg.cmd, rsp->ccode,
val2str(rsp->ccode, completion_code_vals));
goto out_free;
}
lprintf(LOG_INFO, "RAW RSP (%d bytes)", rsp->data_len);
/* print the raw response buffer */
int i = 0;
for (i=0; i<rsp->data_len; i++) {
if (((i%16) == 0) && (i != 0))
printf("\n");
printf(" %2.2x", rsp->data[i]);
}
printf("\n");
out_free:
/* clean repository caches */
ipmi_cleanup(ipmi_main_intf);
/* call interface close function if available */
if (ipmi_main_intf->opened > 0 && ipmi_main_intf->close != NULL)
ipmi_main_intf->close(ipmi_main_intf);
log_halt();
return 0;
}六月四日 等待变化等待机会
心血来潮希望编译openbmc的项目,始终遇到一个编译错误:In file included from Dev/Go/code/src/github.com/veandco/go-sdl2/sdl/sdl_syswm.go:4:0: /usr/include/SDL2/SDL_syswm.h:97:44: fatal error: mir_toolkit/mir_client_library.h: No such file or directory #include <mir_toolkit/mir_client_library.h>一开始我不知其所以然,因为我始终以为这个是交叉编译的项目所有的编译都是在其自己的环境,因为链编译工具编译环境应该都是封闭的和我的Host无关,后来才意识到这个是我的模拟器qemu的运行的img的编译,因此是我自己的qemu的运行环境,这里解释了这个库的头文件的问题我最后只好把/usr/include/mirclient和mircommon下的东西都移到/usr/include下。
六月六日 等待变化等待机会
这个真的是难以置信的事情!我花了好几天才明白了一个如此简单的道理,难道没有人犯同样的错误吗?似乎我的理解和大多数人都不一样吗?关于dvd里的subtitle,似乎没有什么人不知道,当我使用ffmpeg试图从DVD里的vob文件抓取subtitle的时候总是不成功,后来才明白一个简单的道理,就是ffmpeg里的所有的subtitle的encoder/decoder都是针对subtitle stream的,当你的vob里面只有video/audio的stream而没有subtitle的stream的时候自然是报错说没有包含任何的stream,试看这个输入的文件情况:
Input #0, mpeg, from 'VTS_01_1.VOB':
Duration: 00:24:35.58, start: 0.045500, bitrate: 5821 kb/s
Stream #0:0[0x1bf]: Data: dvd_nav_packet
Stream #0:1[0x1e0]: Video: mpeg2video (Main), yuv420p(tv, top first), 720x480 [SAR 8:9 DAR 4:3], Closed Captions, 29.97 fps, 29.97 tbr, 90k tbn, 59.94 tbc
Stream #0:2[0x80]: Audio: ac3, 48000 Hz, stereo, fltp, 192 kb/sffmpeg -f lavfi -i "movie=VTS_01_1.VOB[out+subcc]" -map 0:1 -y /tmp/output.srt六月八日 等待变化等待机会
很久很久没有写什么关于政治的话题,虽然我一直在观察思考但是不想污染这个日记的风格。今天忍不住记下来因为也许将来有一天这些可能会被验证,对于这种虚荣的追求迫使我想留下来一个痕迹:阎学通的报告很有一些独到见解,他提到了一个很有意思的现象,在多极争霸的格局下先出头的被灭,而在两强争霸的格局下后出头的被灭。这个是一个多么有意思的战略抉择啊,在三国时期曹操之所以挟天子以令诸侯是为了不成为众强的攻击目标,但是在两强争霸的时候先形成优势的会产生磁吸效应形成正反馈加速形成优势。他提到的另一个例子是在短道滑冰比赛时候最容易摔跤的地方是在弯道,原因是超越发生在弯道,在直道阶段大家大部分是匀速前进超越很难发生,而在弯道大家都会减速避免摔倒,而想要超越就要冒险不减速或者少减速,于是超越也许就发生了,但是被超越者绝对不甘心被超越,于是激烈的碰撞就在两强接近的时候发生。我以前一直认为美国最好的策略是越早和中国决战越有利,但是现在看来这种决策本身都不是理性的,因此出于情感性的因素决战发生在被超越的一刹那因为非理性的心理因素,因此最危险的时刻在14到17年后,也就是习近平提到的2035年前后。六月十日 等待变化等待机会
关于ffmpeg的filter的cc我跟踪了gdb有了一个初步的认识,首先,这个是一个所谓的filter,都是第一个参数,至少我是这么认为的,它实际上是创造出一个format,当然是依靠在打开文件的时候利用文件名后缀[output+subcc]也就是output的format。其次就是说它是创造出了虚拟的stream,因为srt是只能接受subtitle的stream才能工作的,而closed caption不像其他stream是一个subtitle,而是和video混在一起的,这样就让这个虚拟的subtitle stream让srt来工作了。不过细节还没有很明白。(this->*callback)(*this, userData);那么带入参数时候直接对于成员函数取地址是不行的,因为成员函数都是偏移量不是真正的指针,需要加上类的前缀或者好像namespace的样子吧?
// Author : nick
// Version :
// Copyright : Your copyright notice
// Description : Hello World in C++, Ansi-style
//============================================================================
#include <iostream>
#include <string>
#include <vector>
#include <cstdlib>
#include <cstdio>
using namespace std;
class Human;
typedef void (Human::*CollectCallbackType)(const Human& man, void* userData);
class Human
{
public:
Human():MaxNameLength(6)
{
}
void generate()
{
m_nAge = rand()%30 + 20;
char buffer[32];
for (size_t i = 0; i < MaxNameLength; i ++)
{
buffer[i] = rand()%26 +'a';
}
buffer[MaxNameLength] = '\0';
m_strName = buffer;
}
operator int() const
{
return m_nAge;
}
operator string() const
{
return m_strName;
}
void collectAgeCallback(const Human& man, void* userData)
{
vector<int>* pVect = (vector<int>*) userData;
pVect->push_back((int)man);
}
void collectNameCallback(const Human& man, void* userData)
{
vector<string>* pVect = (vector<string>*)userData;
pVect->push_back((string)man);
}
void collectHelper(CollectCallbackType callback, void* userData)
{
generate();
(this->*callback)(*this, userData);
}
void collectAge(vector<int>& vectAge)
{
collectHelper(&Human::collectAgeCallback, &vectAge);
}
void collectName(vector<string>& vectName)
{
collectHelper(&Human::collectNameCallback, &vectName);
}
protected:
const size_t MaxNameLength;
int m_nAge;
string m_strName;
};
int main()
{
Human man;
vector<int> ageVect;
vector<string> nameVect;
for (int i = 0; i < 15; i ++)
{
man.collectAge(ageVect);
man.collectName(nameVect);
}
for (size_t i = 0; i < ageVect.size() && i < nameVect.size(); i ++)
{
cout << "name:" << nameVect[i]
<< "age:" << ageVect[i] << endl;
}
return 0;
}
七月十八日 等待变化等待机会
整个使用linux的过程就是在寻找解决问题的过程,这不是很好吗?一个小小的问题浮现了,我要用以下midnightcommander这个是我的最爱之一,可是在我目前喜爱的centos7上一直hang着,google才明白是因为我的Hostname的设定,因为这个有好几个层面的问题,我想起来我们工作中安装操作系统的时候hostname是installer设定的一个参数,其次这个是在/etc/hostname的一个设定,但是作为命令行hostname的设定似乎并不是修改这里,我在/etc/resolv.conf里设定是不对的因为它是自动产生的,核心的问题是我无法正确的ping `hostname`,这个是mc一直要等到timeout的原因。究竟要怎样修改呢?一方面hostname看起来仅仅是一个面子问题,我的terminal的prompt显示和设定不一致,但更要紧的是某些程序比如mc依赖它来获得ip地址,我修改/etc/sysconfig/network也是无意义的,这个正是我之前说的installer或者说anaconda设定的,实际上/etc/sysconfig/network-scripts/ifcfg-xxx里的东西才更重要。这里也有设定hostname,似乎这里才能让我的ping找到hostname的正确ip。唉,这个问题实在是不简单,也许对于有些过来人这个是不值一提,可是我至今还是在黑暗中,总之,当我的ping `hostname`能够正确返回的时候我的mc也能够立刻运行。BTW,mc是一个alias,他运行了一些环境设定,不过目前这个是无关的。值得学习的技巧是怎样用regex获得用户名:MC_USER=`id | sed 's/[^(]*(//;s/).*//'`七月三十一日 等待变化等待机会
有两件事让我触动很大,一个是关于MegaRAC API的问题,我惊奇的发现S居然老早就已经写进代码里了,我却还是从W哪里闻到他的诀窍,使用cookie和CSRFtoken的http header来验证。CSRF(Cross-Site Request Forgery)。说老实话我并不是很理解这个问题,但是S居然不知道怎样明白使用特殊的http header来做的,等他回来要问他一下。另一个问题是对于BMC的firmware的形式的问题,我自己辖打瞎撞发现原来它是mtd之类的flash的image,于是有一个途径来mount它,就是首先使用mtdram/mtdblock两个内核模块然后dd这个image到/dev/mtdblock0这个设备,然后使用jffs2的类型mount,我看到了十分之一的image文件大小的文件系统,dd总是报错说设备out of space,我看了dmesg里面抱怨一些错误但是还是没有找到原因,只能尝试比较新一些的内核,或者使用什么mtd-util/tool之类的来实验,有人似乎说是这个内核模块的问题,有人说是内存分配不足。八月二日 等待变化等待机会
centos还是要比ubuntu好多了,这个指的是作为专业开发者而言,对于普通用户ubuntu是很友好的,但是相对来说有很多的不稳定因素。比如我编译mtd-utils的时候因为我不断需要降级很多的依赖的包导致总是出现version mismatch的错误,这里有大仙指点但是也不奏效,不过这个步骤还是对的,只不过我的问题更复杂罢了:aclocal; libtoolize --force; autoheader; autoreconf --force --install八月三日 等待变化等待机会
这两天的一点点心得是这样的,我之前一直看到我dd myflashimage /dev/mtdblock0出错说out of space并不是什么内核版本的问题,至少不是在dd,这个是mtdram的问题,是这个设备的默认的total_size大小的问题,这个可以轻松的由module的参数来解决,比如我要写入的Image大小为30M,那么modprobe mtdram total_size=40000就差不多了因为单位的k,而真正的困难时第二步的mount出错了,不论我使用新版内核并不能解决jffs2的文件系统不匹配的问题,我google到的答案似乎是说这个错误可能是很多的原因,或者是flash的特性比如没有先erase的缘故,我使用mtd-utils来eraseall然后得到的错误是mtdblock0不是block device,这个时候我才想起mtdram是一个模拟的东西,所以另一个说法似乎更加有道理,他说dd不是正确的做法对于nand来说,要使用nandwrite,似乎有道理,可是同样的mtdblock0被我作为一个内存模拟的mtd设备并不是真正的mtd block设备,还有第三个可能就是说也许qct的bmc f/w也许不是真正的mtd image,或者另一个可能性是使用很古老的内核驱动?因为我实验的都是较新的内核比如3.10/4.x,我倾向于bmc是比较古老的内核版本。同时我对于这个mtdram的内核模块的功能有了进一步的怀疑,总之我的探索仅仅解决了dd out of space的谜团,而作为寻找答案的过程的收获是编译内核模块的体会。首先是内核版本的localversion的问题,我发现kernelversion是代码定义的和kernelrelease是两个概念,这个我以前记得现在又全忘了,之所以计较这个问题是因为我编译的模块在modprobe的时候总是抱怨exec format error,我一直怀疑是模块的版本不一致,因为Modules.sysver文件需要完全编译才会产生而似乎这个和原本的不一致,我不知道是否应该把我现在的内核版本拷贝过来,我即便把localversion按照我当前内核版本做成一模一样依然有modprobe的错误,后来我只好尝试-f来压制错误,也许这个是jffs2的mount的错误的来源?还有一条路线是使用mtd-utils的内核来编译模块,但是这个是所谓的external的编译我需要学习更多,也有很大的风险搞坏系统,也许不安装来实验是安全额做法。总之内核无小事,任何的细节都可能是关键的。八月六日 等待变化等待机会
我依然想用2.6的内核来验证一下究竟发生jffs2读的错误是否是因为内核版本不同的原因,我已经知道4.x的最新内核不工作,那么到哪里去找2.6版的老内核呢?第一个想到的是使用那些用usb启动的linux,可是一时找不到合适的,后来发现还是我最心爱的ubuntu10.04的iso最容易启动。于是乎我对于这个好东西甚是欣赏想把它的wifi不工作的问题解决了,那么第一步是remaster iso,我记得以前用过工具,忘了就只好一步一步跟着这里。八月八日 等待变化等待机会
这个是由一个教训,我升级我的centos,然后突然之间很多内核模块部工作现象就是内核版本不同的表现,我很清楚的没有自己编译内核,在centos是确定的,也许吧,我的记忆力太差了,可是使用yum history rollback并不起作用而且undo/rollback都有错误,这让我感到困惑,然后我试图降级/升级内核版本不起作用才意识到我的grub是装在ubuntu的而在启动菜单上内核文件是写死的,难怪怎么改变都不起作用。八月十四日 等待变化等待机会
关于centos的中文输入法的配置实在是很混乱,总之我折腾了很久但是并不知道绝对正确的设置方法。GTK_IM_MODULE=fcitx XMODIFIERS=@im=fcitx我加上了这些环境变量但是不知道是否有用,期间最后似乎起作用的是im-choose选定了fcitx因为默认的似乎是ibus。总之目前似乎是开始工作了,但是中英文切换并不是完全工作。也许fcitx.conf八月十五日 等待变化等待机会
在阅读ipmi spec的过程中我有了一个误解,关于SEL的reserve的问题上我对于get的操作是否需要reserve有一个模糊认识,想当然认为应该也需要,实际上ipmitool的实现是遵循spec的,对于没有partial get的操作是不需要reserve的。那么是否真的不需要呢?我后来想还是加上为好,好处是可以不至于在有其他人修改记录的时候来读减少一些错误的机会,但是前提是不要把reserve的id作为参数传入get,这样子的效果是你可以打断正在进行中的修改操作逼迫他们再来一次。八月二十三日 等待变化等待机会
我想能有一个可靠的centos7的iso来启动livecd以便实验rescue等等,那么官方的livecd是否可以工作呢?我搜索了很久才找到这个似乎是比较可信的,当然也是因为stackoverflow是比较靠谱的,这是我这几年的经验之谈,其他的所谓的linux的论坛都是业余入门级玩家的瞎扯谈,只有stackoverflow是真的专业人士,有一度我想把我的搜索只限制在哪里,当然只是一个想法。究竟行不行我这就实验一下,顺便唠叨一下我的白痴想法,我模仿ubuntu的grub配置自然是不行的因为init不同嘛,比如Ubuntu用casper,而其他人不是啊,参数传递的确是复杂,虽然最终都是给linux kernel传递最关键的root=参数,可是各有巧妙不同。使用cdlabel看来是最容易的?不过我要重启了才知道。用blkid发现iso的cdlabel。八月二十五日 等待变化等待机会
menuentry "CentOS 7.5 Live GNome ISO" {
insmod ext2
insmod squash4
insmod iso9660
insmod multiboot2
insmod gzio
insmod xzio
insmod loopback
set isofile="/media/CentOS-7-x86_64-LiveGNOME-1804.iso"
set isolabel="CentOS-7-x86_64-LiveGNOME-1804"
search --no-floppy --fs-uuid --set aba502d4-8460-48fb-b9d3-201256d5c410
loopback loop (hd0,5)${isofile}
linux (loop)/isolinux/vmlinuz0 root=live:CDLABEL=${isolabel} rootfstype=auto ro rd.live.image quiet rhgb rd.luks=0 rd.md=0 rd.dm=0 iso-scan/filename=${isofile}
initrd (loop)/isolinux/initrd0.img
}
menuentry "Debian 9.5 live gnome ISO" {
insmod ext2
insmod iso9660
insmod loopback
set isofile="/media/debian-live-9.5.0-amd64-gnome.iso"
set isolabel="d-live 9.5.0 gn amd64"
search --no-floppy --fs-uuid --set 3e00216e-8aa8-4080-a622-3f98ae5921d0
loopback loop (hd0,5)$isofile
linux (loop)/live/vmlinuz-4.9.0-7-amd64 boot=live components "findiso=${isofile}"
initrd (loop)/live/initrd.img-4.9.0-7-amd64
}
八月二十七日 等待变化等待机会
menuentry "Archlinux 2018 LiveCD ISO" {
set isofile="/media/archlinux-2018.08.01-x86_64.iso"
search --no-floppy --fs-uuid --set aba502d4-8460-48fb-b9d3-201256d5c410
set imgdevpath="/dev/disk/by-uuid/aba502d4-8460-48fb-b9d3-201256d5c410"
loopback loop (hd0,5)$isofile
linux (loop)/arch/boot/x86_64/vmlinuz img_dev=$imgdevpath img_loop=$isofile
initrd (loop)/arch/boot/x86_64/archiso.img
}
八月二十八日 等待变化等待机会
终于我似乎找到了我的前行者,早就有人在做我想做的,就是制作一系列的救援或者说实验性质的liveCD iso启动系统以便我可以使用grub菜单启动到各种livecd。九月三日 等待变化等待机会
redhat的livecd的机制应该是目前我所遇到的最复杂的,至今我也没有找到一个有效的解决办法,问题就是它使用的bootloader是syslinux的情况下,我要使用我的grub怎样做呢?对于isolinux.cfg的参数我现在看到了一点点的方向,首先,initrd.img在isolinux目录下是一个使用dracut制作的initrd,dracut根据其manpage就是专门用来制作initrd的工具,当然它本身就是其中的一部分它甚至可以直接制定live boot的Url,但是我觉得似乎不是这样直接的,因为kernel的命令行参数inst.stage2=是给ananconda的参数,这个是我今天唯一的一点点进展,这个是在liveCD目录下的squashfs里的ext3.img或者名字为rootfs.img的里面的anaconda的脚本里解析这个kernel的参数。为什么?它读取/proc/cmd_line的字串然后split。但是中间的initrd里的dracut是怎样被调用的呢?或者说这个initrd的Init是systemd而对于systemd我很不熟悉不明白它是怎样设定任务来通过dracut的设置来找到并传递root的。九月九日 等待变化等待机会
对于initrd的理解还是太不够了,这里有一个简单的介绍。其实关于initrd的作用可以总结成一句话就是帮助找到正确的root,可以称之为“寻根之旅”。我找到了一个在线阅读的可是完全读不进一个字。九月十一日 等待变化等待机会
对于initrd的结构你了解多少呢?我被cpio形式迷惑了好久,才找到这个明白了原来是有一个gzip的cpio接在第一个cpio之后。所以最好的命令是这样子的: (cpio -id; zcat | cpio -id) < /path/to/initrd.img九月十四日 等待变化等待机会
对于redhat/centos的boot的过程的确是有一点点的复杂,因为我首先要明白它依然遵守kernel/initrd的主旋律,只不过这里的initrd都是所有复杂过程的开端,比如在initrd里init可以是systemd,而它是取代传统udev之类的新型启动机制,我正开始读了一个开头,这个就是我的只言片语:init要初始化如此众多而复杂的设备以及无数的服务包括mount各种各样的文件系统,每一个都有可能失败有各种各样的依赖性,而怎样能够加快这个复杂的过程而不是傻傻的等待呢?这就是多线程的大有作为的天地,因为这个本来就是为了加快众多速度缓慢等待的设备通讯而设计的。因此每个线程或者进程都使用socket来通讯,当然这里是否是Unix socket我还没看到,反正这个是最理想的剥离通讯者之间紧密联系的方法,我以前就想到只有这个才能防止通讯者之间crash而互相影响。这个再慢慢看吧。这里遇到的问题是redhat里的initrd里的init实际上是一个installer应该是anaconda或者dracut之类,那么你要通过SOL(serial over lan)来远程观察于是我在kernel的boot parameter加上了console=tty0 console=ttyS1,19200,n这样子kernel的boot message就可以透过SOL看到了,那么kernel结束之后你就看不到了因为init开始了,所以,在kickstart脚本里也添加同样的参数让anaconda也这样,但是这里说init刚开始运行的时候是没有tty0的只有ttyS1。这的确是一个复杂的过程。后来在使用razor的ipxe以及自带的microkernel安装redhat的时候遇到一个Ip分配的问题,就是我在dhcp上只分派一个ip,因为pxe/ipxe/microkernel/redhat都是要使用同一个ip在一串过程,结果发现ipxe的ip没有被释放结果microkernel就分配不到ip了,而microkernel里的systemd只会在启动的时候尝试一次就放弃再次dhcp了。我想这个是正常的。九月二十一日 等待变化等待机会
#include <string>
#include <iostream>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, char** argv)
{
if (argc != 2)
{
cout << "usage: " << argv[0] << " <filename>" << endl;
return -1;
}
FILE* stream = fopen(argv[1], "r");
if (stream != NULL)
{
string strFormat;
string strPreviousPartialMatch;
boost::regex e("<[^>]*>");
while (!feof(stream))
{
#define BUFFER_SIZE 255
char buffer[BUFFER_SIZE+1];
size_t size = fread(buffer, 1, BUFFER_SIZE, stream);
if (size > 0)
{
buffer[size] = '\0';
boost::match_results<std::string::const_iterator> what;
string str = strPreviousPartialMatch + buffer;
strPreviousPartialMatch.clear();
string::const_iterator start = str.begin();
string::const_iterator end = str.end();
while (boost::regex_search(start, end, what, e, boost::match_default | boost::match_partial))
{
strFormat += string(start, what[0].first);
start = what[0].second;
if (what[0].second == end)
{
strPreviousPartialMatch = string(what[0].first, end);
}
}
if (start != end)
{
strFormat += string(start, end);
}
}
}
fclose(stream);
cout << strFormat;
}
return 0;
}
十月九日 等待变化等待机会
我在旅行中观看抖音下载的令人着迷的短视频,那一句经典的结尾音不断重复:抖音,记录美好生活。的确在当前波诡云谲的中美局势下有很多人很悲观,而我则对于美帝终将被征服充满信心,因为了解中国的现状也许通过这些app更准确。于是我有一个疑惑:我要怎样创建类似于视频文件浏览的那些thumnail呢?第一步还好,第二步是怎样使用这些缩微图呢?十月十四日 等待变化等待机会
我实际上至今不明白为什么我的html的video播放有什么错误。实际上html5的播放是依赖于系统的播放吧?我收集了一些yy.com的视频,现在又有点迷恋tiktok的短视频。十月十八日 等待变化等待机会
工作中我需要依靠pci的vendorid和deviceid来标识设备的生产商名称和设备名称于是就写了这么个小程序生成c++的pci-vendorid-deviceid的表。这个是pciid的原始的表。十一月五日 等待变化等待机会
boost的确是博大精深,至少我是这样感觉的,单单一个property_tree就让我折腾了这么久,这个文档是很好的入门的学习,实际上我的使用是有一些问题的。我花了很长时间才明白get<string>("path.with.dot")是一个shortcut的这个形式get_child(ptree::path_type("path.with.dot"),'.').get_value<string>()。这个里面的path_type是可以使用不同的demilmiter,默认是'.'。十一月六日 等待变化等待机会
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/xml_parser.hpp>
#include <boost/property_tree/json_parser.hpp>
#include <boost/foreach.hpp>
#include <boost/filesystem/path.hpp>
#include <boost/filesystem.hpp>
#include <boost/lexical_cast.hpp>
#include <boost/date_time.hpp>
#include <boost/date_time/posix_time/posix_time.hpp>
#include <string>
#include <set>
#include <exception>
#include <iterator>
#include <iostream>
#include <vector>
using namespace std;
using namespace boost;
using namespace boost::property_tree;
using namespace boost::filesystem;
using namespace boost::posix_time;
void getFile(const string& strFileName, ptree& pt)
{
filesystem::path p(strFileName);
if (!filesystem::exists(p))
{
return;
}
if (!filesystem::is_directory(p))
{
return;
}
ptree subTree;
filesystem::directory_iterator dir = filesystem::directory_iterator(p);
for (filesystem::directory_iterator it = dir; it != filesystem::directory_iterator(); it ++)
{
if (filesystem::is_directory(it->status()))
{
getFile(it->path().string(), pt);
}
else
{
ptree filenode;
if (filesystem::is_regular_file(it->status()))
{
//make_pair(it->path().filename().string()
filenode.push_back(make_pair("file_size", lexical_cast<std::string>(filesystem::file_size(it->path()))));
filenode.push_back(make_pair("hard_link_count", lexical_cast<std::string>(filesystem::hard_link_count(it->path()))));
ptime now = from_time_t(filesystem::last_write_time(it->path()));
//cout << now << endl;
filenode.push_back(make_pair("last_write_time", lexical_cast<std::string>(now)));
subTree.put_child(ptree::path_type(it->path().filename().string(), '/'), filenode);
}
else
{
if (filesystem::is_symlink(it->status()))
{
filenode.push_back(make_pair("read_symlink", filesystem::read_symlink(it->path()).string()));
subTree.put_child(ptree::path_type(it->path().filename().string(), '/'), filenode);
}
else
{
if (filesystem::is_other(it->status()))
{
// ???
}
}
}
}
}
property_tree::path treePath(p.string(), '/');
pt.add_child(treePath, subTree);
}
void traverseTree(const ptree& pt, int indent = 0);
void traverseTree(const ptree& pt, int indent)
{
if (pt.empty())
{
cout << "\"" << pt.get_value<string>() << "\"" << endl;
}
else
{
cout << "{" << endl;
for (ptree::const_iterator it = pt.begin(); it != pt.end(); it ++)
{
const ptree& sub = it->second;
cout << string(indent+4, ' ');
cout << "\"" << it->first << "\":";
traverseTree(sub, indent+4);
}
cout << string(indent, ' ');
cout << "}" << endl;
}
}
十一月十三日 等待变化等待机会
就如同读论文一样的道理,很多时候一篇好的论文更多的是通过她的引用带你进入更多的相关文献,我对于smbios至今也之停留在缩写的理解上,这个东西其实很基础很重要,回答了不少的基本问题。我现在更像一个计算机考古学的学生学习的大都是上个世纪就存在并成熟的文献资料。关于这个bis我看了一眼就不愿意再看了,因为这个太高级了如同tpm之类的不是我辈所能有条件玩的,安全是在轻松驾驭之后的课题。其实一切都归因于我对于不工作的bmc的拯救努力,这个是asus关于asmb4的文档,很多年前我甚至不明白它的用途就买回来。其实至今我对于他的工作原理依然不清楚需要读一下这个手册。(大致看了一下明白这个东西基本无用被骗了,当年完全不了解bmc的功能,这个就是一个kvm只不过让你可以远程使用的而已的ikvm,如果你有了bmc你是不需要这个的了。)因为我看到dmidecode --type 38的输出结果显示我有ipmi device,但是内核初始化失败,这个内容是smbios的信息,可是准确吗?Handle 0x0062, DMI type 38, 18 bytes
IPMI Device Information
Interface Type: KCS (Keyboard Control Style)
Specification Version: 2.0
I2C Slave Address: 0x00
NV Storage Device: Not Present
Base Address: 0x0000000000000CA2 (Memory-mapped)
Register Spacing: Successive Byte Boundaries十一月十四日 等待变化等待机会
对于这个ipmb地址分配表我感到很茫然,这个地址是内存映射的地址吗?十一月十九日 等待变化等待机会
我使用一款老式的toolchain大约是gcc4.2版本的吧,在编译使用boost ptree的时候爆出warning of limited type,google之后也没有办法解决,猜想是编译器太老了这个warning的surpress的参数也不存在,不愿意去修改代码削足适履,后来终于找到使用-isystem来指明boost的directory是系统这样就压制了第三方的代码的warning。这个是一个非常有用的参数。十一月二十八日 等待变化等待机会
我对于这个项目总是充满了好奇与期待,但是这个应该是非常复杂的一个领域。不过世界上的事情就是这样子的,当你在窗外翘望的时候总有很多不切实际的渴望,走进橱窗发现店里卖的东西确实另一个东西。不过它把我引导了coreboot这个才是真正的宝贝,于是我又开始了我的搬砖工作。我为了检查网页需要本地运行一个之简单的webserver,就选用lighttpd,但是这么简单的配置还让我头疼:server.document-root = "BigDisk/diabloforum/public_html/"
server.port = 80
index-file.names = ("index.htm")
mimetype.assign = (
".html" => "text/html",
".txt" => "text/plain",
".jpg" => "image/jpeg",
".png" => "image/png",
".htm" => "text/html"
)十一月三十日 等待变化等待机会
为了编译coreboot我只好重新安装ubuntu16.04因为14.04很多库不支持了。总之,Linux就是折腾。那么所有的设置都要重新配置,其中观察到有firmware的Missing,这个其实也不难理解,无非是Ubuntu发行版遗漏了,当然我看到kernel.org官方也没有,所以不是ubuntu的错,那么参考supermicro客服给的ast的ast_dp501_fw.bin的下载链接拷贝到/lib/firmware下面就是了。安装输入法发现fcix能够支持googlepinyin的确好多了,所以升级还是有益处了。另外就是eclipse我决定使用neon最新版,当然需要安装默认的default-jre,在launcher上的图标没有那么我就要自己在~/.local/share/applications/eclipse.desktop里设定一个icon的路径。flashrom也是coreboot用到的一个工具,这个也是很值得学习的,不过我差的太远了,心有余而立不足矣。不过能够体验一下coreboot在qemu的-bios下模拟一下coreinfo作为payload我觉得今天的收获已经很大了。有了qemu这样的神器几乎就是如虎添翼的差别。十二月六日 等待变化等待机会
关于怎样建立一个local的repo是这样子的:
# mount -o loop RHEL7.1.iso /mnt
If you use DVD media , you can mount like below.
# mount /dev/sr0 /mnt
# cp /mnt/media.repo /etc/yum.repos.d/rhel7dvd.repo
# chmod 644 /etc/yum.repos.d/rhel7dvd.repo
enabled=1
baseurl=file:///mnt/
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
In the end, the new repo file could look like the following (though the mediaid will be different depending on the version of RHEL):
[InstallMedia]
name=DVD for Red Hat Enterprise Linux 7.1 Server
mediaid=1359576196.686790
metadata_expire=-1
gpgcheck=1
cost=500
enabled=1
baseurl=file:///mnt/
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
# yum clean all
# subscription-manager clean
# yum --noplugins list
# yum --noplugins update十二月十一日 等待变化等待机会
对于ftp的机制一直鲜有了解,直到因为扫描仪必须使用ftp上传图片需要配置才意识到实际上很多时候为了安全性ftp用户是chroot的一个jail。十二月二十三日 等待变化等待机会
我终于解决了我对于windows的几乎是最后一个需求,就是HOMM3的难以舍弃,终于在升级到ubuntu19.04后发现winehq相当的稳定。不过这个所谓的“稳定”的结论是通过一个反例证明的,因为一开始我经常遇到屏幕死机的问题,并不是长时间待机造成的,而是运行一段时间出现显卡的错误:radeon VCE resume error. 我google后意识到这个不是wine本身的问题,而是显卡的问题,我的笔记本是radeon R7 M265,但是使用amd显卡下载界面只有Ubuntu14.04的支持,使用所谓opensource的ubuntu18.04的默认显卡驱动并不能解决这个问题,终于又google才找到这个,这里我保存一个拷贝吧。然后wine运行一直没有出现错误,接下去我可以测试一下wine在linux下运行和原生的window联网的成果。不过这个都不重要了。因为wine现在已经很成熟了,我衷心的感谢这些developer,kudos。在游戏战略里你常常观察到电脑玩家不停地派出小股部队来骚扰或者是抢占资源,每当你想要挥重兵直捣黄龙时都不得不回师救援,,这个其实就是战略的一部分,如果敌人不是如此不断的骚扰,我军已经可以直接消灭敌人巢穴了。与时间赛跑,现在就是中美的最后决战的前夜。
![]()