
一月十八日 等待变化等待机会
长 久以来编译文件系统就是一个很麻烦的事情,之前尝试了一下其他的工具,现在看来linux from scratch有其独到之处,作为一个学习的途径肯定是好的,而且比较简单,对于自动化有需求的可以尝试一下他的alfs,我实验了一下,就是在编译内核 部分有些卡壳,有时候原来的lfs比如下载链接失效,如何修正源头而不是手动下载似乎还找不到办法.所以看到这个人的言论我有些赞同,就是宁可把所有的脚本放在一个文件里运行更好修改运行.一月十九日 等待变化等待机会
使用LinuxFromScratch的下载清单发现80个文件有一个遗失,需要找出来那一个没有下载,因为下载直接使用wget --input-file=../wget-list没有报错:一月二十日 等待变化等待机会
使 用jhalfs也就是alfs的脚本,费了很大劲编译出错当然令人沮丧,想来development版本原本就不保证没有错,我没有选择stable是我 的错,看http://svn.linuxfromscratch.org/LFS/上没有什么branch可以选啊,都是6.x我想选最新的 stable都是在tags上,那么在menu上怎么表达呢?branch需要branch-的前缀,我一样话葫芦就用tag-结果看代码才发现直接选 tag名字就好了,怎么第一步没有想到呢?设定source-archive也是很有用的,否则很多package要反复下载,遇到之前zlib旧版没有 只有手动下载了.我基本放弃自己parsing原书的xml的想法,这套工具如果稳定何必呢?一月二十日 等待变化等待机会
一月二十六日 等待变化等待机会
tcc 是一个神奇的东西,只有100多k做到了很多大型编译器的工作,我很久以前看到启动时候使用tcc编译内核然后启动的壮举为之惊叹不已.现在简单浏览发现 可以学习的很多,首先对于elf的parsing就值得研究一下, gcc里面曾看过一些小的东西,看看tcc怎么用.编译过程的库和include是怎么解决的呢?个二月四日 等待变化等待机会
这 几天在玩alfs,就是lfs的自动版.首先从lfs开始,配置看似简单采用人们熟悉的类似kernel的menuconfig的界面,一开始失败是因为 采用的book setting里的开发版,后来改成稳定版就行了,里面的小细节是版本号和branch,看脚本才明白直接使用7.0不加任何前缀.zlib的xz下载链 接已经失效了,只好手动下载gz版然后tar vxf zlib.x.x.gz | xz > zlib.x.x.xz,然后把它存到$SOURCE_ARCHIVE目录下,这个很好的设置,否则要反复download.其次就是编译内核的时候总是 抱怨openssl的一些头文件找不到,因为lfs是使用自己编译的tool来编译,我不知道要怎样配置,最后只好在kenerl config里把module_signature之类的都去掉,总算能够编译了一个lfs,后来systemd也可以了.现在尝试clfs,这个使用的 是git,通过branch -a看到所有的branch,选择3.0.0-systemd.我现在不想太多,想直接做一个toolchain就好了,还是逐步来比较好,alfs虽然 好,但是实际上没有什么增长,仿佛开了一辈子车的人也不会明白发动机的原理.还是手动学习的多.二月五日 等待变化等待机会
这真是一个大笑话,你能够在x86-64架构下chroot编译mips64吗?我为什么有这么大的误区呢?应该是以前使用qemu的binary的一个机制让我有了这么大的模糊认识.这个看上去不错.二月六日 等待变化等待机会
打算手动创建一遍,第一步创建一个空白的e2fs,使用gpart缩放一个硬盘分除了若干个分区准备实验几个不同的配置.卡在这里: 我即便重新编译mke2fs也会有个"ext_attr": ext_attr dir_index filetype sparse_super large_file读manpage说是使用默认的配置在这里:/etc/mke2fs.conf,结果我就是用参数-O来传递各个feature,不 行,再读manpage原来可以用^禁用某个feature,所以,最后命令如下:sudo ./misc/mke2fs -O ^ext_attr,resize_inode,dir_index,filetype,sparse_super,large_file /dev/sdg2 原因是第一个ext_attr默认是有的,必须明确禁用!二月十三日 等待变化等待机会
我 使用自动的clfs就是aclfs然后chroot不成功,然后拷贝qemu的static依然不成,让我感到很困惑,然后我决定手动创建一次clfs, 在检验是否chroot可以的时候迷惑而不敢轻易前行,因为照例说我没有拷贝qemu的static之前所有的mips的binary是无法执行的,可是 输出的结果又是可以的,至少libc.so.6在我tool目录下是可以正确执行的.这个很让我吃惊难道什么地方出错了?二月十八日 等待变化等待机会
我 的记忆力非常的差,以至于忘记了我做过的很多事情,比如我想不起来这么一个简单的问题,就是如何能够在同一行输出,我记得这是一个非常幼稚的问题以至于缠 绕了我很久发现答案后我是如此的生气居然耻于写下答案因为太可笑了,然而当我再次遇到同样的问题我又不知所措了,这就是愚蠢,因为只有不想学习自己的无知 才叫愚蠢.首先,在console里换行是由你自己控制的,'\n',那么你同样的'\r'实际上回到行的开头,所以,每一个学习过编程都知道的'\n\ r'是两个符号,一个教你换行,一个教你到行的开头,难道你现在还不知道怎样保持在同一行吗?当然重复写在stdout的buffer里是要有格式的否则 就是自己覆盖自己的包含之前的如果没有覆盖的话.也许我始终不理解的原因在于在eclipse的console里这个是不行的,我猜想是为了调试程序清楚 eclipse把运行的\r自己加了\n或许是为了和windows统一?总之,我一直以为这个不成立就是因为在eclipse的debug运行无效的原 因.顺便说一下这个是c++11的语法,需要在编译的时候加上std=c++11,顺便再复习一下关于时间的问题,曾经有同事在工作中需要storage array提供localtime,这个被认为是一个无理的要求,系统只需要提供你utc时间,你作为使用者自己去转化为localtime才对,否则 array部署在什么地方还需要告诉你吗?现在都有可能是cloud的东西,今天是这个,明天说不定就是另一个系统在另一个datacenter了.
#include <iostream>
#include <vector>
#include <ctime>
#include <iomanip>
#include <cstdlib>
#include <unistd.h>
using namespace std;
int main()
{
int i = 0;
while ( i ++ < 1000)
{
std::time_t result = std::time(nullptr);
struct tm * ptr = gmtime(&result);
std::cout << '\r'
<< std::setw(2) << std::setfill('0') << ptr->tm_hour << ':'
<< std::setw(2) << ptr->tm_min << ':'
<< std::setw(2) << ptr->tm_sec << std::flush;
sleep(1);
}
return 0;
}
二月二十日 等待变化等待机会
找了很久才发现从命令行启动handbrake的命令:dpkg-query -L handbrake-gtk 发现命令是ghb, 我下载了最新的代码然后重新编译结果老版的crash的问题就解决了.二月二十五日 等待变化等待机会
找 了很久才明白其实这么简单,ipmi在redhat里的service叫做ipmi,在ubuntu里还原了本名叫做openipmi,大体的结构是这样 子的,首先,这个是内核的支持,需要内核模块ipmi_devintf,ipmi_si等等,这个可以称作是ipmi的驱动,他们需要和硬件的bmc等等 通讯.那么linux里的驱动典型的都是使用ioctl来的需要建立一个/dev/ipmi0的驱动文件来通讯,而作为工具的一部分ipmitool仅仅 是直接和驱动文件交流,所以为什么需要一个service是有一点令人费解,要看代码才明白,我估计是因为通讯的缓存吧,否则大量的信息需要一个监听者 吧.此外以前接触到的dmidecode的机制,这个似乎是一个硬件的信息库工具,能够读bios信息吗?以前读取的关于hdmi的支持信息,也有关于 bmc的信息.实验了一下证实是openipmi这个service呼叫驱动创建了/dev/ipmi0的驱动文件,看来这个服务也可以称之为用户方面的 驱动的一部分,内核的支持固然是必须的,用户级的辅助也是必须的否则无法使用工具ipmitool.另一个层面就是ipmi的机制是跨越操作系统的,本身 这些东西就是有相当一部分是原始的硬件的操控,比如远程安装操作系统或者远程控制硬件这些是不依赖于任何os的机制,所以这个是一个途径,另一个是利用主 板本身的bmc的网络和web service或者serial over lan等等的机制.三月一日 等待变化等待机会
这些都是意外的意外,原本是看一些关于ipmi的东西,却发现了的确hitachi已经停用的服务器的确有安全的问题.这个是关于cypher0的问题,我按照文中所说的只要知道bmc的ip地址就一定能够登录.三月二日 等待变化等待机会
昨 天发现我的想法是错误的,实际上Ipmi的SOL渠道可以用来控制bios的设定,当然前提是bios支持redirect console to serial port的机制,这个原理和操作系统的启动设定是一样的道理,比如linux kernel要设定启动参数把console=ttyS0这样子。其次要在ipmitool里根据spec设定命令chassis bootdev bios强制进入bios设定画面,然后是启动就是chassis power reset之后进入sol状态sol activate结果看到了bios的启动画面,我一开始被蒙了以为是什么x display从bmc传回来的,后来和bmc自带的remote console比较才意识到这不过是serial console而已,作为bmc完全不费力气的直接把bios转到serial然后通过sol机制得以网络传输。因为sol是一个双向的协议所以可以进行 交互就是说用户的键盘相应可以传回bios,而这个不同于vnc/kvm机制是可以进行编程控制的,问题就在于在ipmitool里这个叫做 rawmode,就是使用termios的类似于dos窗口的图形模式,我还没有实验过,不过应该还是有区别吧应该是ascii而不是pixel,这一点 要确认。想到这里我突然意识到在rasperry/beagleboneblack之类的soc就没有一个对应的bios机制,因为没有主板的flash 存储?但是beagle是使用了一个内嵌的micro sd卡来存储,有异曲同工之效,总之,这个算是pc机的一个架构吧?三月三日 等待变化等待机会
查看ipmi spec 2.0发 现有定义很多东西但是似乎ipmitool并没有实现?比如在boot flag部分有定义要求设定console redirection control,但是在ipmitool似乎没有这个参数。此外,很多open source project的document只有manpage,看起来不方便,于是你可以使用ps2pdf来转换为pdf文件,比如man -t ipmitool.1 | ps2pdf - ipmitool.pdf三月七日 等待变化等待机会
感冒了。在ipmi spec 2.0可以找到network function的codes,但是具体command的codes呢?我肯定是误解了什么后来下载spec1.5也没有找到。找了很久最后在最后一页也就是appendix G才找到command的codes.这里有一个惠普的例子使用raw command来通讯的,可以作为参考。三月九日 等待变化等待机会
事 实上ipmi是一个很简单的通讯协议,我说简单是指的通讯协议本身,而标准覆盖各种各样的硬件以及不同的链接方式,因此是非常复杂的,有很多全都依赖于 oem厂商自己实现。我之前迷惑的在于没有找到在文件最后的附表里的command codes,appendix G,这个让我想到了Yes Prime Minister里那些官僚在提交公务员加薪报告里把最大涨幅的高官的列表也是放在报告最后的附件里而仅仅给首相审查会议预留五分钟审议还包括中间喝茶的 时间,所以这个能怪我吗?另一个重大的失误在于没有找到sub command的格式,以至于在看chassis的部分时候完全不知所以然,因为多到八九个的子命令明显的冲突,后来在使用raw模式的ipmitool 的例子里才意识到多么的简单,sub command直接加载command后面,所以是这样子的:network func+command+subcommand+data。这个是不是很简单阿!此外,在启动菜单里的这些所谓的mailbox模式都是非永久 persistent,也就是说取决于重启的时间和角色,可能完全被抹去。volatile是仅仅下一次而且必须60秒内重启才有用,但是semi volatile的存留时间我就不确定了。不过总之boot device order是不在协议的控制范围的,他们想要修改这个我觉得是不可能的,至少理论上通过sol模拟人操作修改boot bios菜单只是理论上可行,且不说解析菜单的byte来分析当前值,就算是盲打直接修改也有一大堆的特殊字符的夸平台处理,serial传输速率是否需 要等待相应?而且这个漫长的过程跟不不是一个同步api,作成异步岂不是违反了library的原则,成为service,所以,这个仅仅是理论上可行。
SDP:
v=0
o=-
0 0 IN IP4 127.0.0.1
s=No Name
c=IN IP4 127.0.0.1
t=0
0
a=tool:libavformat 57.58.101
m=video 1238 RTP/AVP
96
b=AS:900
a=rtpmap:96 H264/90000
a=fmtp:96
packetization-mode=1;
sprop-parameter-sets=Z2QAHqzZQLQ9+X/wAgABtqDAIMgAAAMACAAV+QB4sWyw,aOvhMsiw;
profile-level-id=64001E
Stream mapping:
Stream #0:0
-> #0:0 (copy)
然后才使用ffplay如下:ffplay
-i ~/.sdp -protocol_whitelist file,udp,rtp 三月十日 等待变化等待机会 三月十二日 等待变化等待机会
这个是之前我尝试使用ipmi的raw
command的时候发现的一个很好的范例网站。
其实我对照ipmi
spec也是一步一步这么做的,只不过如果不想看spec直接用就省心了,我已经花时间看了就算是验证了。昨天顺便看了cpio的简单的说明,意识到其实
跟文件系统的描述很像,所以纠正了我一直的想法,在paypal的时候我看到部署使用cpio形式一直以为这个是一种binary的格式,现在才意识到这
个是一个文件系统已经就位后的部署,所以这个时候才明白操作系统级别的部署是不能用这个的,只有使用磁盘镜像,就是img之类的。那么有没有可能把磁盘镜
像mount起来再去修改那个运行的shell呢?
google了一个比较数字签名算法的论文,有时间去看看。
这个是基于S的代码使用curl来操作的范例。
1.
Login and generate cookie: 三月十五日 等待变化等待机会 三月十六日 等待变化等待机会 三月十七日 等待变化等待机会 三月十八日 等待变化等待机会 三月二十一日 等待变化等待机会 三月二十三日 等待变化等待机会 三月二十四日 等待变化等待机会 三月二十五日 等待变化等待机会 三月二十六日 等待变化等待机会 三月三十日 等待变化等待机会
[root@rh63-58-110 ~]# curl --insecure
-X POST https://172.17.21.13/rpc/WEBSES/create.asp -d
'WEBVAR_USERNAME=admin&WEBVAR_PASSWORD=admin'
……
//Dynamic
Data Begin
WEBVAR_JSONVAR_WEB_SESSION
=
{
WEBVAR_STRUCTNAME_WEB_SESSION :
[
{ 'SESSION_COOKIE'
: '0vJAoSDt9NnZ91GD4TCZCv1kIdp7YE6L001','BMC_IP_ADDR' :
'172.17.21.13' }, {} ],
HAPI_STATUS:0 };
//Dynamic data
end
2. Query to get
firmware info:
[root@rh63-58-110 ~]# curl --insecure -H "Cookie:
WebServer=Server: GoAhead-Webs;
SessionCookie=0vJAoSDt9NnZ91GD4TCZCv1kIdp7YE6L001;Username=admin;
PNO=4; test=1" -X GET
https://172.17.21.13/rpc/hoststatus.asp
……
//Dynamic Data
Begin
WEBVAR_JSONVAR_HL_SYSTEM_STATE
=
{
WEBVAR_STRUCTNAME_HL_SYSTEM_STATE :
[
{ 'JF_STATE' :
1 }, {} ],
HAPI_STATUS:0 };
//Dynamic data end
这个是使用vnc的步骤,但是全屏之后键盘无法使用。server:
x11vnc -display :0 --usepw --forever --shared
client:
vncview
./configure
CFLAGS="-ggdb3 -O0" CXXFLAGS="-ggdb3 -O0"
LDFLAGS="-ggdb3"
对于ipmiutil的编译来说有一个大问题就是无法定义openssl的路径,这个也只能用以上的办法来解决在CFLAGS里加上-
I/your/openssl/header/path,在LDFLAGS里加上-L/your/openssl/lib/path,注意不能使用所谓的
useflags的选项,我把这两个export成环境变量结果无法configure,其中的一个修改是必须手动来把util/Makefile里的
CFLAGS_SAM之类的改造一下把-g
-O2替换成@CFLAGS@,当然你可以在Makefile.in里作修改这样做你可以使用configure来生成正确的Makefile。我做这个
的原因是因为在使用ipmiutil的时候发现和ipmitool的区别在于activate_session没有被呼叫,然后导致oem的raw
cmd出错,我的理解是QCT的这类oem扩展大都用于一些复杂的过程,比如上传FW文件,这样涉及大量的packet不愿意每次都验证,所以需要创建一
个session,以便后面的packet减少overhead。但是奇怪的是我在家里实验在wireshark上没有看到类似的问题,难道是编译的问
题?前天遇到另一个问题就是V要集成poco在其代码中这样子在一个系统里两个dll都有poco的代码,windows据他说默认dll是
private
symbol如果static
linking的话,但是linux默认是global的symbol,在运行期dll到底连接到哪一个版本呢?K后来说找到一个简单的解决办法就是
linking
flag里可以屏蔽某些lib的symbol,我还没有来的即去看详细。前天开会QCT其实有一些不公开的bmc的ipmi扩展可以在bmc里mount
一个nfs的文件系统比如linux
iso文件这样子就可以启动安装运行Linux,还没有来的即去仔细看。一直纠缠在ipmi的上传文件上。
./configure
--enable-internal-md5 --disable-intf-lanplus --disable-intf-imb
--disable-intf-serial --disable-intf-open --disable-solaris-opt
--disable-ipmishell --prefix=/home/nick/ipmitool-install
CFLAGS="-ggdb3 -O0" CXXFLAGS="-ggdb3 -O0"
LDFLAGS="-ggdb3"
四月一日 等待变化等待机会 四月四日 等待变化等待机会
Convert
time to timestamp:
[root@C65-57-74 ~]# date -d "2017-03-28
08:07:19" "+%s"
1490713639
[root@C65-57-74 ~]#
date -d @1490713639
Tue Mar 28 08:07:19 PDT 2017
# define BSWAP_32(x) ((((x) &
0xff000000) >> 24) | (((x) & 0x00ff0000) >> 8)
|\
(((x) & 0x0000ff00) << 8) | (((x) & 0x000000ff) <<
24))
#if
WORDS_BIGENDIAN 四月五日 等待变化等待机会 四月七日 等待变化等待机会 四月九日 等待变化等待机会 四月二十日 等待变化等待机会 四月二十一日 等待变化等待机会 四月二十二日 等待变化等待机会 四月二十四日 等待变化等待机会 四月二十六日 等待变化等待机会 五月三日 等待变化等待机会 五月四日 等待变化等待机会 五月六日 等待变化等待机会 五月七日 等待变化等待机会
temp = BSWAP_32(s->in_seq);
#else
temp =
s->in_seq;
#endif
md5_append(&state,
(const md5_byte_t *)&temp,
4);
typedef
const unsigned char Array221[221];
in good.cpp:Array221*
goodArray[]={&pkg1,&pkt2...,&pkt1115}; ...in
bad.cpp:Array221* goodArray[]={&pkg1,&pkt2...,&pkt1115};
for
(int i=0; i < 1115; i ++) const unsigned char*ptrGood =
goodArray[i][0]; const unsigned char*ptrBad = badArray[i][0]; if
(memcmp(ptrGood+110, ptrBad+110, 221-110)!=0)printf("packet %d
differs\n",
i);}
其中的教训是对于固定大小的数组最好是存储起指针而不是把数组作为元素,具体原因我不是很清楚总之编译的时候编译器对于类型的指针还是数据有些模糊,以上的最简单。对于wireshark采集的capture数据看样子只有自己写小程序来搜索了。
ubuntu的server版和desktop版的启动是不同的,desktop又casper,server版有netboot.这里有一个非常好的介绍,但是有一个致命的问题就是desktop里的vmlinuz.efi而不是vmlinuz,我强行设定symlink结果启动就oopse了.
2. I create a clone directory and copy the contents to here. sudo mkisofs -o ../clone.iso -no-emul-boot -boot-load-size 4 -boot-info-table -b isolinux.bin -c boot.cat -R -J -v .
3. Does this new iso work? Yes, it works. I download qemu and test like this: qemu-system-x86_64 -cdrom ../clone.iso It works.
4. Then I dd this iso to my usb flash drive. sudo dd if=../clone.iso of=/dev/sdb bs=1M
5. Then I test it with qemu and it fails. sudo qemu-system-x86_64 -hda /dev/sdb
6. What is the difference between my iso and original mini.iso? Let's use fdisk to take a look:
nick@ubuntu-mini:~/Downloads/clone$ sudo fdisk -l ../mini.iso
Disk ../mini.iso: 57 MiB, 59768832 bytes, 116736 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x13012329
Device Boot Start End Sectors Size Id Type
../mini.iso1 * 0 104447 104448 51M 17 Hidden HPFS/NTFS
../mini.iso2 104448 116735 12288 6M 1 FAT12
nick@ubuntu-mini:~/Downloads/clone$
However, my clone.iso is nothing like this:
nick@ubuntu-mini:~/Downloads/clone$ sudo fdisk -l ../clone.iso
Disk ../clone.iso: 50.8 MiB, 53241856 bytes, 103988 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
nick@ubuntu-mini:~/Downloads/clone$
一切的一切开始于我需要制作一个mini live cd iso image.首先从官方网站我下载了mini.iso.而造成的误会源于这个iso制作巧妙可以同时作为cdrom/dvd和usb启动.而玄机是作为cdrom启动你使用mkisofs来制作是足够的,可是usb是截然不同的,我一开始没有意识到,一直怀疑我的mkisofs参数不对,其实使用qemu来检验iso是可以-cdrom启动的,问题是usb的启动需要作为harddrive来启动,需要使用分区.这就是为什么你需要使用fdisk来查看,你一看你使用mkisofs制作的压根就没有dos分区就应该明白仅仅使用mount -o loop得到的是不完整的,你漏掉了第二个分区,机关就在这里,通常我看到的gumstick/beaglebone/rasperypi这些做的image都是把dos分区放在第一个,这样子你是无法直接mount linux的第二个分区的,需要正确的offset,而这个iso的第一个是一个hidden hpfs,第二个分区才是dos,导致我可以直接mount以至于我没有意识到它有多个分区.难道是因为hidden?究竟要怎样把hidden hpfs(17)的分区做成使用第0个sector开始的呢?我使用fdisk始终没有办法,因为它或者sfdisk始终顽固的要求sector alignment,不让你使用从0开始的sector,后来我猜想也许它是直接从物理的设备上拷贝下来的而不是首先从一个img文件制作文件系统的?因为制作过程牵扯到chroot肯定是不简单还不如直接使用usb/cdrom直接制作然后再dd下来?另一个值得学习的是直接使用losetup而不是用mount -o loop,好处是我可以首先把img文件的某个片段映射到一个/dev/loopX的设备上,对于设备的读写要方便的多.一般的流程是这样子的:
1. create an image file: sudo dd if=/dev/zero of=1G.img count=1000 bs=1M
2.use fdisk to create multiple partition: sudo fdisk 1G.img
3. find out the offset so that you can mount to device in next step:
nick@nick-KGP-M-E-D16:/BigDisk$ sudo fdisk -l 1G.img
...
Device Boot Start End Blocks Id System
1G.img1 * 2048 2047000 1022476+ 83 Linux
1G.img2 2047001 2047999 499+ 7 HPFS/NTFS/exFAT
4.mount partition to a device: sudo losetup -o 1048576 /dev/loop1 1G.img
5.create filesystem by the device: mke2fs /dev/loop1
五月九日 等待变化等待机会
五月十三日 等待变化等待机会
实际的配置远远深刻,我非常的不熟悉systemd的运行与配置,在我的ubuntu14.04就不行,好像只有16.04才行,不过发现journalctl是一个很好的东西,其中记录了大量的信息,发现了很多启动的问题.编译ipmitool的时候,sol是需要lanplus的,于是你就不能再使用internalmd5了,因为configure会检查看有没有其他的hash function之类的,会失败然后拒绝编译lanplus.
In order to build ipmitool for debugging with both lan and lanplus:
./configure --prefix=/home --enable-intf-lan --enable-intf-lanplus --disable-intf-serial --disable-intf-open --disable-intf-imb --disable-intf-bmc --disable-intf-usb --disable-intf-free --disable-ipmishell --enable-static --disable-shared --with-pic CFLAGS="-ggdb3 -O0" CXXFLAGS="-ggdb3 -O0" LDFLAGS="-ggdb3"
我遇到了一个奇怪的问题就是我的openssh-server似乎没有正常以至于我无法使用ssh从远程登录,排除了ip conflict和firewall的因素,似乎sshd没有再监听22端口.无奈之下就采用apt-get purge然后重新安装.总之,一般的debug办法是在server端改变/etc/ssh/sshd_config里的loglevel到最高级的debug3,然后tail -f /var/log/auth.log.在client端可以加-vvv来看client端的输出.不过这些都没有什么帮助,因为压根就没有到握手的阶段,所以,还是iptables之类的问题吧?
五月十六日 等待变化等待机会
首先使用dd创建一个空文件,dd if=/dev/zero of=image.img bs=1M count=800然后使用mkfs.vfat创建文件系统,然后使用fdisk来创建分区,我把msdos/fat16之类的放在了后面,而前面的分区是ntfs,然后使用sudo syslinux -s image.img来安装bootloader,需要把isolinux改名为syslinux,同样的isolinux.cfg改为syslinux.cfg,然后就拷贝安装光盘iso的文件.但是问题是ntfs不支持symlink,而改为linux文件系统syslinux又不肯安装.似乎并不正确啊...
还有一个问题就是我制作的mini-iso在boot后一直等待网卡起来运行,这个不行的,因为它根本没有ip分配,是纯粹利用bmc的ip通过sol来访问的,它自己不需要连接网络,于是需要禁止systemd等待,在/lib/systemd/system下有一个netwoking.service使用systemctl disable它.在chroot的情况下这个是唯一可以做的.
五月二十五日 等待变化等待机会
./configure CFLAGS="-I/root/devPath/HiStorAPI/external/openssl/oelx86_64/7.3/include" CXXFLAGS="-I/root/devPath/HiStorAPI/external/openssl/oelx86_64/7.3/include" LDFLAGS="-L/root/devPath/HiStorAPI/external/openssl/oelx86_64/7.3/lib" --prefix=/home --enable-intf-lan --enable-intf-lanplus --disable-intf-serial --disable-intf-open --disable-intf-imb --disable-intf-bmc --disable-intf-usb --disable-intf-free --disable-ipmishell --enable-static --disable-shared –with-pic
类似的需要编译debug版本通常是:CFLAGS="-ggdb3 -O0" CXXFLAGS="-ggdb3 -O0" LDFLAGS="-ggdb3"
五月二十六日 等待变化等待机会
六月四日 等待变化等待机会
六月五日 等待变化等待机会
六月六日 等待变化等待机会
首先,debug sudo的程序要这样子,sudo gdb –args usbipd -d,基本上你不用到某些被系统禁用的如setuid之类的,这个就可以。其次,usbip要编译为debug版本,当然是在configure里设定CFLAGS/LDFLAGS来了,-g -O0就可以了,但是我看不懂libsysfs的函数在干什么就想也跟踪一些,就把sysfs的configure设定为—enable-shared=false,当然同样要设定CFLAGS,然后回国同来在usbip的configure里在LDFLAGS里面加上-L/PATH/TO/LIBSYSFS/STATICLIB -Bstatic -lsysfs -Bdynamic这样就使用我编译的版本可以直接debug了。当然这个改动太大把动态库改为静态库来debug,正确的是使用LD_LIBRARY_PATH来在gdb之前加上我的libsysfs.so的路径。总之,基本功有长进,但是驱动的原理依然模糊,连使用驱动都是一个问题,可以称之为在userland的lib的都不会使用。
六月九日 等待变化等待机会
find redirector-master/ -name "*.class" -exec sh -c 'cd $(dirname "$0") && jad $(basename "$0") ' {} \;
我下载了一个很不错的工程其中一部分是自动启用kvm,其中有很多的java的class我想反编译看源代码,所以使用jad,但是它的命令输出不熟悉想要输出在.class文件相同的目录下,所以就成了这个样子。相似的,我想验证一下结果:
find redirector-master/ -name "*.jad" -exec sh -c 'cd $(dirname "$0") && ls -asl $(basename "$0") ' {} \;
同时我想了一天开始怀疑我的方向,因为usbip肯定不是一个万能的方法,首先,它的确很好,但是需要内核的支持,客户端和服务端都需要内核支持,其次,我后来才想明白tcp/ip部分还是在user space做的一个daemon所以效率也不见得很高吧?但是最主要的是它依赖于内核的驱动实现的usb的驱动来实现的。我需要的也许使用一个libusb就能实现,因为我需要的仅仅是生成usb的一个个URB,当然我需要一部分protocol的握手部分,所以。。。这个正是我下载java源代码来分析的原因,也许实际不复杂的,看了一下其实kvm依赖于三个针对linux/windows/mac的dso,我看了一下symbol,除了给java做借口的部分就是一个所谓的mediareader的类,应该是cdrom设备的读的实现,因为iso image根本不需要实现,然后就是一个100$的问题,怎样使用dl来呼叫一个c++的类的成员函数?首先创建类对象就是个问题,你没有header定义类的大小,你能够怎样生成对象?这里的问题有好几层:1.objdump -T -C看到的是所谓的demangle的函数签名是不行的,你只能用没有-C的原始symbol名字来dynamic load。2。constructor或者member function其实都是带一个类指针作为第一个参数的c函数,至少很多编译器是这么实现的,那么constructor是不返回类指针的你怎么得到类对象?你是传入指针的,比如class Foo; typedef void (*FooCtrFunc)(); 我google了一下想了一小会儿就明白你要冒个险,用一个超大buffer来模拟,比如char*buf[1024];/*让我们祈祷dso的类作者没有在类里存储超大数据,否则我们就内存overwrite了*/
class Foo* foo = (Foo*) buffer;
FooCtrFunc ctr = dlsym(handle, “稀奇古怪的函数名字从objdump看到的“);
ctr(foo);
看懂了吗?你把类的指针做参数传递给constructor来获得对象实例,然后就可以呼叫member function了,不要忘记成员函数同样需要dlsym获得原始symbol name,呼叫的时候第一个参数是foo。但是这个做法太过危险了,我不明白的是objdump显示不出来函数的返回值,这个实在是头疼啊,因为函数返回值从来就不是函数签名的一部分,而我压根无法猜测怎么使用返回值,就是说你以后设计函数的时候如果心存恶念不想让如我这样的卑鄙小人依靠binary来猜测使用就尽管使用函数返回值来操作,那么真的很损阴德的。
所以,看到这里你才会真正明白一个道理,就是为什么需要factory模式,我写了三年的库真正体会到factory pattern的用途其实是在dynamic loading的时候体会到的,对于c++的dso来说,如果你不提供factory简直就没法用了。很多的道理教科书上说的其实远没有实际体会来的深刻,我想至少factory模式的意义目的不经历实际使用是难以体会的。其次,c++的dll对外声明成虚类使得类成为方法表导致函数的调用全部都是指针偏移,你完全不能依赖于symbol table,因为objdump看不到symbol,这样子最阴损,让你没有头文件就彻底死心了,这是最没有道德的做法。
六月十二日 等待变化等待机会
六月十九日 等待变化等待机会
六月二十日 等待变化等待机会
六月二十二日 等待变化等待机会
六月二十六日 等待变化等待机会
六月二十八日 等待变化等待机会
_ZN19CCDROMImgFileReaderD2Ev 和 _ZN19CCDROMImgFileReaderD1Ev 在objdump眼里是一样的,所以,我想去找源头,应该是linker产生的,但实际上gcc/gdb等等一切的一切大家统一依赖于libbfd来处理object file,否则不一致就会产生无穷的问题,这是一个非常正确的选择。他们的源头就是libbfd,从文档阅读开始。
六月三十日 等待变化等待机会
七月七日 等待变化等待机会
七月八日 等待变化等待机会
使用aptitude install要比apt-get install聪明多了,后者非常的糟糕,前者很智能的给出降级冲突包的方案,你只需要选择就好了。相比之下比synaptic要容易多了,因为图形界面似乎不真的支持gnome,而是kde的环境。
七月十日 等待变化等待机会
How to construct a .gch file from one of these base header files.
First, find the include directory for the compiler. One way to do this is:
g++ -v hello.cc
#include <...> search starts here:
/mnt/share/bld/H-x86-gcc.20071201/include/c++/4.3.0
...
End of search list.
Then, create a precompiled header file with the same flags that will be used to compile other projects.
g++ -Winvalid-pch -x c++-header -g -O2 -o ./stdc++.h.gch /mnt/share/bld/H-x86-gcc.20071201/include/c++/4.3.0/x86_64-unknown-linux-gnu/bits/stdc++.h
The resulting file will be quite large: the current size is around thirty megabytes.
How to use the resulting file.
g++ -I. -include stdc++.h -H -g -O2 hello.cc
Verification that the PCH file is being used is easy:
g++ -Winvalid-pch -I. -include stdc++.h -H -g -O2 hello.cc -o test.exe
! ./stdc++.h.gch
. /mnt/share/bld/H-x86-gcc.20071201/include/c++/4.3.0/iostream
. /mnt/share/bld/H-x86-gcc.20071201include/c++/4.3.0/string
The exclamation point to the left of the stdc++.h.gch listing means that the generated PCH file was used。这里是关于gcc的precompiled header的文档,不像windows都为你做好了,linux下程序员要付出更多的努力去实现。
七月十八日 等待变化等待机会
七月二十四日 等待变化等待机会
七月二十五日 等待变化等待机会
八月一日 等待变化等待机会
jviewer启动不正常的问题实际上很简单,是因为新版本的javaws试图去更新,与其更改javaws的代码,不如直接设立一个alias
javaws='javaws -noupdate'
我试图理解为什么QCT提供的ami的vmcli不能支持旧版的问题,看它的初始化数据objump -s -j .rodata vmcli,的确看到定义的常量里的wget的参数是有加引号的,可是不知道为什么他会失败?我的实验是system()的确就像是shell command一样的,你必须使用引号屏蔽特殊字符。难道运行成daemon这个会有所不同吗?或者QCT不使用system()而是使用popen,我怀疑,因为从简单来看他们似乎就是一个速成的产品,很多都是把shell脚本直接搬过来。
八月二日 等待变化等待机会
其次我自己实验了一下system()的调用,虽然99%肯定,但是毕竟原因不明,因为在daemon情况下用ps看到的命令行参数就没有加引号了,这个也许是linux显示的问题?
八月十日 等待变化等待机会
八月十八日 等待变化等待机会
实验中遇到很多关于启动的疑惑,比如ESXi server boot是怎么发生的?注意到Mallenox的IB好像有个一个什么flexboot的东西直接就启动了,好像类似与Intel的NIC也有一个什么boot agent可以直接启动吧?还有就是在UEFI模式下启动有什么不同?同样是floppy的removable device,似乎bootloader不同?疑惑太多了。
八月二十日 等待变化等待机会
八月二十三日 等待变化等待机会
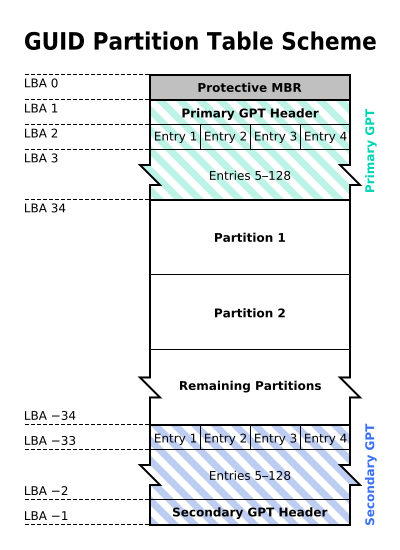
UEFI是一个非常大的topic,单单从启动部分就有很多的复杂的问题,首先这个是我阅读wiki得到的基本的常识,就是MBR就是一个512byte的在disk开头的sector,但是bootloader很难在几百个byte里写成,一定有一个second
loader,所以,这里就牵出了另一个大的topic,partition
scheme,究竟是传统的bios的还是较新的GPT,前者是总共就是1k*1k=1M的部分给你存放所有的partition
table和bootloader的代码,而后者就不是这样子的。我昨天看的是这个wiki,结果看完了就更糊涂了,这些问题非常的复杂,而且一开始就提到sector
size 512和4K的异同让我更加的糊涂了。boot结构肯定是和磁盘结构紧密项链的。这真是废话,如果你什么也没有看懂就不要废话了。
LBA34是磁盘的第一个可用的地址,这个对于GPT来说就是34*512=17k必须分配给GPT的header/partition table entry等等,这里还包含了第一个所谓的protective MBR一个sector0所以才说总共就是16384=16k是分区的信息保存的大小:LBA0=MBR, LBA1=GPT header, LBA2-LBA33是entry。所以16k=17k-sector0-sector1看图识字。我很感谢wiki于是今天就donate了$3给wiki。目前我一共捐过$8给wiki。
八月二十四日 等待变化等待机会
还有一个值得记录的是长久以来我一直认为boot option是一个一次性的设置,这个根据ipmi的协议的确是所谓的semivolatile,会被清除,但是是有条件的,而且我一直认为boot mode是不可通过ipmi来改变的,证明我是错的。这个是可以改变的不过ipmi的文档确实是有一些晦涩难懂,我读了好久才有些明白,还参照了一些例子,因为我的记忆力太差了,之前度过的有忘记了:
Boot with UEFI, persistent, 0xE0 (legacy: 0xC0)
Hdd 0x08
User password bypass+ console redirection 0x0A
Netfunc 0x00 cmd 0x08 subcmd 0x05
[root@rh63-58-110 Debug]# ipmitool -H 172.17.59.189 -U admin -P admin raw 0x00 0x08 0x05 0xE0 0x08 0x0A 0x00 0x00
查询使用这个:
[root@rh63-58-110 HiStorAPI-05_15_0]# ipmitool -H 172.17.59.189 -U admin -P admin chassis bootparam get 5
5指的是第五个函数,这个在ipmi文档里有交代,我曾经为此迷惑了许久,这个结果和以上的设定是不相关的,仅仅参考而已。注意同样的device在uefi和legacy模式下也许解释不同。
Boot parameter version: 1
Boot parameter 5 is valid/unlocked
Boot parameter data: c03c0a0000
Boot Flags :
- Boot Flag Valid
- Options apply to all future boots
- BIOS PC Compatible (legacy) boot
- Boot Device Selector : Force Boot from Floppy/primary removable media
- Console Redirection control : System Default
- User password bypass
- Lock Out Sleep Button
- BIOS verbosity : Request console redirection be enabled
- BIOS Mux Control Override : BIOS uses recommended setting of the mux at the end of POST
九月八日 等待变化等待机会
cmake -DENABLE_TOOLS=ON ..
boost 1.54版本似乎有些毛病,就是libboost_filesystem是depend on libboost_system的。结果就是很误导 我明明看到在编译的libwesnoth-core.a里的symbol出现在libboost_filesystem的DSO里,可是linker总是说找不到symbol的错误?后来只好手动修改cmakelists.txt添加了libboost_system
if(ENABLE_BOOST_FILESYSTEM AND NOT ENABLE_PANDORA)
set(common-external-libs
${common-external-libs}
${Boost_FILESYSTEM_LIBRARY}
${Boost_LOCALE_LIBRARY}
${Boost_SYSTEM_LIBRARY}
)
九月十日 等待变化等待机会
其实我之所以遇到这个问题是查找以下的疑惑才无意中翻到的,以下是wesnoth代码的翻录,我不明所以然: 注释是照抄的,我放在一个小试验里来看结果,但是conversion为什么会调用呢?
#include
using namespace std;
struct MyStruct
{
static MyStruct invalid;
struct safe_bool_impl { void nonnull() {} };
/**
* Used as the return type of the conversion operator for boolean contexts.
* Needed, since the compiler would otherwise consider the following
* conversion (C legacy): cfg["abc"] -> "abc"[bool(cfg)] -> 'b'
*/
typedef void (safe_bool_impl::*safe_bool)();
operator safe_bool() const
{
return this != &invalid ? &safe_bool_impl::nonnull : NULL;
}
};
MyStruct MyStruct::invalid;
int main()
{
MyStruct my = MyStruct::invalid;
if (!my) //why??
{
cout << "not true" << endl;
}
return 0;
}
试图在BS的巨作《The C++ Programming Languange》里寻找答案,可是每看一页就感觉脊梁冒冷汗,战战兢兢,只得掩卷长息为自己的无知与懒惰而气愤。
气愤之余也想明白了一些,因为!不一定是所谓的bool operator的调用,也可以是在把MyStruct转为指针时候,所以,虽然safe_bool是一个成员函数的函数指针,但是毕竟就是一个指针,所以理所当然的就被调用了。然后也是只有这个时候才明白wesnoth定义这个东西的用意,其实很简单,就是防止c程序员的习惯,比如经常我们会简单的说只要指针不是非法就可以调用: if (!ptr) ptr->do();可是现实生活中Invalid的结构比比皆是,c++11里面对于!的定义应该是比较严格的,所以,wesnoth严格定义了一个explicit operator bool() const这样子防止被滥用,当然这里不是指针了,而是if(!cfg)cfg是一个对象了。对于c++98wesnoth这么定义的原因是因为什么呢?为什么不能重载operator bool()const呢?
如果要编译wesnoth为debug版本: cmake -DCMAKE_BUILD_TYPE=Debug ../
九月十四日 等待变化等待机会
九月十八日 等待变化等待机会
HOMM3的Linux
版本vmcl还是有些复杂的,主要是qt5widget的支持问题,而且为何要从这个复杂的入手呢?所以,我决定从最简单的wesnoth开始,至少这个代码容易懂一些。可是开始一看还是觉得复杂,因为他的ai也进化了好多了,于是我就从jit里翻出了它的1.0版本,这个很令人吃惊的运行的非常的好,我不禁从心底里佩服当初的开发者,在第一版就打下了如此坚实的基础。于是我就从改动启动参数学习看怎么能够先弄出一个运行的框架来吧。
编辑pdf使用的是xournal,然后使用pdftk来合并多个扫描的pdf。
九月二十二日 等待变化等待机会
I think this boost/ssl issue of “short read” error (https://svn.boost.org/trac10/ticket/12528) will be a headache in many cases, especially during F/W, BIOS upgrading when procedure takes much long to finish and both network and Quanta server can cause this issue.
Currently it can be resolved by upgrading to boost1.58. (but upgrading will not only affect HiStor, but Puma also.)
In the change log of 1.58, search for “Fixed an ssl::stream<> bug that may result in spurious 'short read' errors.”
http://www.boost.org/users/history/version_1_58_0.html
Or alternately, we can issue a small patch to our boost code base by following as comparing 1.57/1.58 shows this is the fix. And comparing 1.57 with our current, the change are neglect able.
Comparing 1.57 with 1.58
[root@rh63-58-110 Downloads]# diff boost_1_57_0/boost/asio/ssl/detail/io.hpp boost_1_58_0/boost/asio/ssl/detail/io.hpp
5c5
< // Copyright (c) 2003-2014 Christopher M. Kohlhoff (chris at kohlhoff dot com)
---
> // Copyright (c) 2003-2015 Christopher M. Kohlhoff (chris at kohlhoff dot com)
228c228,230
< if (bytes_transferred != ~std::size_t(0) && !ec_)
---
> if (bytes_transferred == ~std::size_t(0))
> bytes_transferred = 0; // Timer cancellation, no data transferred.
> else if (!ec_)
[root@rh63-58-110 Downloads]#
学习boost是我的另一个挑战,首先从bind开始,以前的stl的bind1等等是类似的,可是boost做的很玄妙,c++的作者Struoustrup的书里面提到了很多类似的template的技巧吧?
quanta又埋了一个坑给我,我原本以为使用ipmi修改boot option可以解决boot order不能修改的难题,可是新安装的satadom作为一个新的启动分区确实不受bootoption控制的,这个是所谓的BBS就是bios boot specification的新标准,这个真的是头疼啊。最近还是做了不少的工作的,比如能够想的起来的就是ipmitool bootparam get 5这个不支持很多后来添加的比如remotely connected cd/rom,我是说它输出的时候说flag不正确,我按照ipmi标准修改代码添加了这些新的设备。再比如,对于os启动或者安装是否成功要怎么知道呢?一直以来有人主张使用bios POST code来查询,可是我从这个code是bios公司的code,不属于ipmi能够控制的,而且作为bios一旦启动INT19把启动权交给os的bootloader他就休息了,他怎么知道os的结果呢?我从server的界面上看到的POST CODE都是相关的硬件的checkpoint code,最后一个就是INT19启动os的。后来使用ipmi 的sdr查询到了有一个所谓的event only的sensor是os,他能够记录os启动的event的。sdr是一个存储的方式,真正查询event的方法是sel命令,按照SK的说法,sdr存储的是threshold的sensor,比如温度,风扇,对于discrete的需要的是assertive的event所以存储在sel,还可以被过滤使用pet,但是我在sel里只看到了rhel的启动事件,对于ubuntu就没有,看来这个是os需要主动回报给ipmi之类的硬件的吧?总之,每天的信息两太多了,大都忘记了。
九月二十六日 等待变化等待机会
如果对于server端的vnc运行的instance有疑虑可以vncserver -kill :#其中的”#”是display number.或者netstat -pant
对于ipmitool的安装需要ipmi_si和ipmi_devintf,前者如果没有bmc是不能成功安装的。但是如果指定port似乎也能modprobe,但是/dev/ipmi0是无法创建的。
十月三日 等待变化等待机会
libssh2的使用有一个问题就是在libssh2_init(flag)有一个选项可以让你选择不初始化libcrypto的。这个是必要的因为
OpenSSL_add_all_algorithms不是一个线程安全的函数,而且也不应当被反复调用,这个是初始化被一次性的调用就可以的了。以下的程序说明它会crash.
#include
#include
#include
#include
void* thread_proc(void* param)
{
int counter = 100000;
while (counter > 0)
{
OpenSSL_add_all_algorithms();
counter --;
}
return NULL;
}
int main(void)
{
pthread_t pid[10];
const size_t thread_size = sizeof(pid)/sizeof(pthread_t);
for (size_t i = 0; i < thread_size; i ++)
{
pthread_create(&pid[i], NULL, thread_proc, NULL);
}
for (size_t i = 0; i < thread_size; i ++)
{
void* ptr = NULL;
pthread_join(pid[i], &ptr);
}
return 0;
}
编译运行会crash:
[root@rh63-58-110 src]# gcc -g -O0 -std=c99 -lcrypto -lpthread ./openssl-test.c -o openssl-test.exe
[root@rh63-58-110 src]# ./openssl-test.exe
*** glibc detected *** ./openssl-test.exe: realloc(): invalid next size: 0x00007ff8f0000980 ***
*** glibc detected *** ./openssl-test.exe: realloc(): invalid next size: 0x00007ff8f0000980 ***
*** glibc detected *** ./openssl-test.exe: realloc(): invalid next size: 0x00007ff8f0000980 ***
*** glibc detected *** ./openssl-test.exe: realloc(): invalid next size: 0x00007ff8f0000980 ***
*** glibc detected *** ./openssl-test.exe: realloc(): invalid next size: 0x00007ff8f0000980 ***
Segmentation fault (core dumped)
但是这个问题是早就明白的( https://github.com/libssh2/libssh2/issues/61 ),对于libssh2的初始化如果使用libssh2_init(LIBSSH2_INIT_NO_CRYPTO);就可以避免这个问题了。
十月四日 等待变化等待机会
但是我看到的和system设定却不同。
[root@OEL72-59-177 ~]# sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6
所以我也不明白在那一层设定的,至少 boost这一层我没有看到。
十月八日 等待变化等待机会
十月十一日 等待变化等待机会
安装centos后想要进入gui,发现在/etc/inittab里说明要设定default的target,就是systemctl set-default graphical.target
然后安装vncviewer实际上是安装tigervnc.x86_64
十月十二日 等待变化等待机会
使用x11vnc确实的非常的棒,但是当我的client重启后发现server并没有自动退出,于是只能kill这个server.
十月十八日 等待变化等待机会
编译grub-legacy的时候遇到gcc
-V的错误那个是因为老版本的gcc支持-V返回版本,新的用—version,(也许这都是因为multilib引起的)但是遇到linker的-lgcc_s找不到的问题我其实应该能够猜到是64/32bit的library的问题,我本来想要设置grub平台不是i386,但是不成功我自己的ubuntu是64位,所以,sudo
aptitude install
gcc-multilib而我已经学乖了会使用aptitude而不是apt-get因为要降级很多package,这个是我唯一值得记忆的进步。关于objcopy的configure错误也许是这个可以解决的,我还没有时间实验。(实验了的确行)
if { ac_try='${OBJCOPY-objcopy} --only-section=.text -O binary conftest.exec conftest'
十月二十一日 等待变化等待机会
十月二十三日 等待变化等待机会
使用strace来看看究竟有没有syscall,这个程序输出时间,但是为什么没有关于时间的syscall呢?这里就是关键,为什么需要这种virtual DSO呢?原因是很多的critical的syscall比如时间需要非常的有效率,而syscall需要int80进行context switch非常的昂贵,所以系统决定把这类syscall变成一个访问内存的快速实现。
strace /tmp/vdso_test
execve("/tmp/vdso_test", ["/tmp/vdso_test"], [/* 59 vars */]) = 0
write(1, "The time is 1508829416"..., 40The time is 1508829416.703105
) = 40
exit(0) = ?
+++ exited with 0 +++
[nick@localhost doc]$
十月二十七日 等待变化等待机会
BOOST_FOREACH(boost::property_tree::ptree::value_type &v,res.cJsonbody.get_child("LocalDrives."))
这里有一个关于如何防止的帖子: https://svn.boost.org/trac10/ticket/8465
但是还是比较别扭,最可靠的还是用find,因为我并不需要使用foreach的:
boost::property_tree::ptree::assoc_iterator ait = res.cJsonbody.find("LocalDrives");
if (ait != res.cJsonbody.not_found())
对于snmp我使用nmap来探寻,但是snmp默认使用UDP,所以要使用:
[root@rh63-58-110 ~]# nmap -sU 172.17.59.165
Starting Nmap 5.51 ( http://nmap.org ) at 2017-10-27 16:57 PDT
Nmap scan report for 59-165.sie.hds.com (172.17.59.165)
Host is up (0.00025s latency).
Not shown: 994 closed ports
PORT STATE SERVICE
69/udp open|filtered tftp
111/udp open rpcbind
123/udp open ntp
161/udp open snmp
514/udp open|filtered syslog
2049/udp open nfs
十月三十一日 等待变化等待机会
menuentry "Ubuntu Desktop amd64 10.04 ISO" {
insmod ext2
insmod loopback
set isofile="/media/ubuntu-10.04.4-desktop-amd64.iso"
search --no-floppy --fs-uuid --set aba502d4-8460-48fb-b9d3-201256d5c410
loopback loop (hd0,5)$isofile
linux (loop)/casper/vmlinuz boot=casper iso-scan/filename=$isofile noprompt noeject
initrd (loop)/casper/initrd.lz
}
menuentry "ubuntu 12.04 desktop amd64 ISO" {
insmod ext2
insmod loopback
set isofile="/media/ubuntu-12.04.5-desktop-amd64.iso"
search --no-floppy --fs-uuid --set aba502d4-8460-48fb-b9d3-201256d5c410
loopback loop (hd0,5)$isofile
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=$isofile noprompt noeject
initrd (loop)/casper/initrd.lz
}
menuentry "ubuntu 16.04 desktop amd64 ISO" {
insmod ext2
insmod loopback
set isofile="/media/ubuntu-16.04.2-desktop-amd64.iso"
search --no-floppy --fs-uuid --set aba502d4-8460-48fb-b9d3-201256d5c410
loopback loop (hd0,5)$isofile
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=$isofile noprompt noeject
initrd (loop)/casper/initrd.lz
}
menuentry "linuxmint 17.01 cinnamon amd64 ISO" {
insmod ext2
insmod loopback
set isofile="/media/linuxmint-17.1-cinnamon-oem-64bit.iso"
search --no-floppy --fs-uuid --set aba502d4-8460-48fb-b9d3-201256d5c410
loopback loop (hd0,5)$isofile
linux (loop)/casper/vmlinuz boot=casper iso-scan/filename=$isofile noprompt noeject
initrd (loop)/casper/initrd.lz
}
menuentry "lfs liveCD amd64 ISO" {
insmod ext2
insmod loopback
insmod gzio
set isofile="/media/lfslivecd-x86-6.3-r2145.iso"
search --no-floppy --fs-uuid --set aba502d4-8460-48fb-b9d3-201256d5c410
loopback loop (hd0,5)$isofile
linux (loop)/boot/isolinux/linux boot=linux iso-scan/filename=$isofile noprompt noeject
initrd (loop)/boot/isolinux/initramfs_data.cpio.gz
}
十一月二日 等待变化等待机会
首先在/etc/default/grub里设定GRUB_BACKGROUND="/background.jpg",然后运行update-grub就会自动生成grub.cfg,或者自己要手动添加的话,需要注意这么些:
terminal_output gfxterm
insmod part_msdos
insmod ext2
set root='hd0,msdos3'
search --no-floppy --fs-uuid --set=root 3e00216e-8aa8-4080-a622-3f98ae5921d0
insmod jpeg
background_image -m stretch /background.jpg
对于property tree的使用我伤了很多脑筋,最后这个做法是比较好的,比如,if (pt.get_child_option(path)) strValue=pt.get<string>(path);
参考了一点点代码做了一个简单的xml的示范如下:
#include
#include
#include
using namespace std;
using namespace boost::property_tree;
void indent(int level)
{
for (int i = 0; i < level; i ++)
{
cout << " ";
}
}
void iterate_ptree(const ptree& pt, int level)
{
for (ptree::const_iterator it = pt.begin(); it != pt.end(); it ++)
{
if (it->second.empty())
{
indent(level);
cout << "<" <first << ">"<< it->second.get_value()<<"first << ">"<< endl;
}
else
{
indent(level);
cout << "<" << it->first << ">"<< endl;
iterate_ptree(it->second, level+1);
indent(level);
cout << "first << ">"<< endl;
}
}
}
int main()
{
ptree pt;
xml_parser::read_xml("/usr/share/X11/xkb/rules/evdev.xml", pt);
iterate_ptree(pt, 0);
return 0;
}
}
十一月三日 等待变化等待机会
grub的代码比较的晦涩难懂,我stuck在那里一动不动。然后出现了一个新的曙光,模糊的我觉得一切的一切应该从qemu入手,这个是不可或缺的工具。这里有一个专题是关于内核的。至于这个简化版我遇到32/64位不兼容的问题,应该是linker编译脚本如何设定为32位的问题。
十一月五日 等待变化等待机会
我非常急切的使用vnc链接到我的主机来加上这个链接在日记里,因为他看上去对我太有用了,我需要记录下来: http://www.osdever.net/tutorials/
十一月七日 等待变化等待机会
1.使用dd创建一个raw image,这个应该和qemu-img -f raw是一样的吧? dd if=/dev/null of=linux.img bs=512 count=2048
2。使用fdisk创建分区,这是简单的不能再简单的,可是我的记忆太差了,写下来吧:
a) fdisk linux.img
b) 先创建一个分区,默认是linux,随后在使用t命令修改。n===>p
c)也许应该再创建一个分区,因为bios只认MBR,grub是安装在所谓的boot-sect,就是第一个sector,注意sector0是所谓的MBR,我后来遇到的错误都是抱怨grub-install不能embedding。
3. 需要创建文件系统,这个可以直接使用mkfs.ext2 linux.img,但是因为我没有有多个分区,所以,首先我们需要使用devmapper来做(我个人认为直接使用mount -o loop,offset=也可以达到同样的效果,但是计算offset太麻烦了)
4.先用kpartx来创建devmapper,这个部分是我今天完全陌生的部分,但是现在总算明白了一些,就是kpartx -l linux.img是告诉你它打算怎样mapping,大体就是/dev/mapper/loop0p1 /dev/mapper/loop0p2分别mount 我们linux.img里的两个分区。使用-d来删除这样的mount,使用-a 添加。
5. 那么如果你只想把一个分区mount成一个设备而不是directory,应当使用losetup /dev/loop0,不使用任何flag是显示当前的状态,使用-d是detach,所以,当我们把分区mount到了/dev/mapper/loop0p1之后就可以使用grub-install来安装了,不过我在这里失败了。如果我只有一个分区会报错grub不能embedding,如果我有多个分区,我必须先把/dev/loop0 mount 到一个目录,grub-install –root-directory=./mnt/boot –no-floppy /dev/loop0
十一月八日 等待变化等待机会
先使用qemu-img create -f qcow2 linux.img 1G
然后直接用一个linux的iso来安装: qemu-system-i386 -m 1024 -hda linux.img -cdrom ubuntu-1404_amd64.iso -boot d
内存256M似乎不行,我安装server版直接挂掉了。
下载了一本电子书,看目录相当的不错,不过心里很愧疚没有买正版的,不过有点贵,才两百多页而且大部分是所谓的代码页,所以,还是先看看再说:Learning_Linux_Binary_Analysis.
十一月九日 等待变化等待机会
我有时候觉得我很无理,我为什么要费那么大麻烦要用x11vnc链接到服务器去打开writer来编辑这个日记,而我可以很简单的nfs mount文件到本地来编辑?这个难道我之前没有想到吗?一个小技巧是关于选取第一列who am i|tr -s ' ' | cut -d' ' -f1
安装qemu的磁盘的确非常的慢。我找到了这篇文章似乎是比较可信的,因为和我目前收集的流程相似,不过使用parted比fdisk来说脚本更容易一些。
parted --script mink.img mklabel msdos mkpart p ext2 1 20 set 1 boot on
这个很容易从manpage里找到,不确定的是size 1-20是lba吗?就是第一个sector到第二十个sector?
记住了dd是不能从/dev/null读的,这个只能写,需要从/dev/zero来读!
当我远程登陆后有时候执行命令会遇到类似这样子的: fdisk 是在/sbin而你的路径没有包含等等,而我本地启动的shell则没有这个问题,很明显的是non-login的shell的环境不对,查看$PATH果然不全。原因在这里, 怎么解决呢?不是很清楚,我查看了etc/environment发现路径则这里定义了,但是/etc/bash.profile因为查看是否为login-shell---
# If not running interactively, don't do anything
[ -z "$PS1" ] && return
所以,我就在这之前加上了source /etc/environment,我觉得这个改动比较安全,因为environment里仅仅定义了一个PATH没有太大的风险。
十一月十一日 等待变化等待机会
sudo dmsetup ls 找到比如lurks_process_xxx(252:1) 然后使用lsof | grep 252,1
现在完整的流程是这样创建一个qemu可以启动的linux镜像文件。最简单的是只可以linux启动的单partition既没有msdos在第一个分区,这个是最简单的,如果需要windows也能启动的只不过是创建第一个msdos分区。
1.创建磁盘文件。可以使用qemu-img create也可以直接使用dd if=/dev/zero of=output.img bs=1M count=1K
2.创建分区。可以使用parted也可以使用传统的fdisk。比如parted --script mklabel ubuntu mkpart p ext4 1 100 set 1 boot on
使用fdisk可以直接创建一个默认的0x83linux分区:n,p,1,return,t,0x83,w
3.mount分区并创建设备文件为安装bootloader作准备。可以使用kpartx,也可以直接使用losetup -o,offset=,但是使用kpartx是很方便的不需要自己计算偏移。kpartx -av img,结果是为每一个分区创建了类似/dev/mapper/loop0p1的设备。
4.创建文件系统。使用mkfs.ext4等等工具对于Mount的设备就可以了。mkfs.ext2 /dev/mapper/loop0p1
5.安装grub。这里有两重工作,一方面grub-install需要访问磁盘设备安装自己的bootsector,另一方面需要访问磁盘启动分区的文件系统拷贝内核文件及其启动配置文件等等。所以,一方面你要有Mounted设备/dev/loop0(注意不是分区设备,是磁盘设备,比如/dev/mapper/loop1p2实际上代表了磁盘/dev/loop1的第二个分区,所以作为grub-install需要的参数是/dev/loop1),同时要mount相应的分区来拷贝。因此,创建mount point: mkdir mnt && mount /dev/mapper/loop1p2 mnt
我不确定grub-install是否会自己创建目录,所以我索性自己创建(注意root-directory的路径必须是绝对路径,相对路径会被加上/就大错特错了):
mkdir -p mnt/boot/grub/i386-pc
然后安装grub-install -v –no-floppy –root-directory=$PWD/mnt /dev/loop1
注意grub-install很不友善报错不及时,所以-v很有用。
6.你需要一个linux的distribution,通常我们使用debootstrap,在ubuntu下下载stage1就可以了。
debootstrap trusty build
至于stage2我觉得我只需要chroot去修改密码就行了,配置网卡等等我还没有实验过。
7.需要kernel,我投机取巧直接debootstrap了我当前的ubuntu的版本所以使用我自己本地的kernel就可以了。比如cp /boot/vmlinuz_xxx mnt/boot && cp /boot/initrd_xx mnt/boot
8.获得partition的uuid。blkid可以获得,目的是免除device.map的繁琐,因为设备加载的scsi设备顺序不是保证的,在下一步中有用。
9.创建grub.cfg。这个是我的一个简化到几乎最简单的模板:(其实还可以简化,也许我根本不需要msdos模块,为了加载一幅范冰冰的照片作为启动背景我们加载了jpeg,所以,要拷贝jpg文件到mnt/是最简单的做法。不过现在背景不工作还要修改)
insmod part_msdos
insmod ext2
insmod jpeg
background_image -m stretch /background.jpg
menuentry 'Ubuntu' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-50e4cd30-c12d-4308-b51b-7333f6c7e1d5' {
insmod gzio
insmod part_msdos
insmod ext2
#set root='hd0,msdos2'
#search --no-floppy --fs-uuid --set=root 50e4cd30-c12d-4308-b51b-7333f6c7e1d5
linux /boot/vmlinuz root=UUID=50e4cd30-c12d-4308-b51b-7333f6c7e1d5 ro
initrd /boot/initrd
boot
}
现在实验结果已经出来了,这个几乎是最精简的了:
首先使用blkid找出qemu的image的partition的uuid,其次拷贝你想要的background.jpg文件到mnt/boot下。然后以下就是我的grub.cfg:
search --no-floppy --fs-uuid --set=root 50e4cd30-c12d-4308-b51b-7333f6c7e1d5
insmod ext2
insmod jpeg
insmod video_cirrus
insmod gfxterm
terminal_output gfxterm
background_image -m stretch /boot/background.jpg
menuentry 'Ubuntu' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-50e4cd30-c12d-4308-b51b-7333f6c7e1d5' {
insmod gzio
linux /boot/vmlinuz root=UUID=50e4cd30-c12d-4308-b51b-7333f6c7e1d5 ro
initrd /boot/initrd
}
我现在唯一不确定的是video_cirrus是否因为我的笔记本的显卡相关,还是jpeg相关?
然后接下来的就是chroot到你的image在mount的目录下去设定root的passwd。
目前我还没有明白怎样设定网卡。
十一月十二日 等待变化等待机会
1.使用fdisk创建多个partition,我创建了msdos和两个linux partition,但是设定linux的为启动盘符。
2.同样使用kpartx来创建多个盘符,这里我犯了一个错误,因为usb工厂设置是一个msdos的分区,所以,在linux上被自动加载为/dev/sdb1,但是作为整个设备需要使用的是/dev/sdb,所以kpartx -av /dev/sdb而不应该添加1在末尾,可是kpartx很聪明照样正确的map了/dev/mapper/sdb1,2,3
3.同样使用mkfs.xxx来创建各个文件系统mkfs.ext4 /dev/sdb2
4.同样的要把分区mount以便拷贝grub启动文件,同样的grub-install来安装。
5.同样的拷贝linux的文件系统。设置正确的grub.cfg。
所以,这个就是以前我看到别人怎么制作的linux。
十一月十三日 等待变化等待机会
sudo qemu-system-x86_64 -m 2048 -device e1000,netdev=eth,mac="52:54:00:00:00:01" -netdev user,id=eth,net=192.168.1.0/24,dhcpstart=192.168.1.9 -hda /dev/sdb
启动后,我在dmesg里看到了e1000的设备创建,然后我在/etc/network/interfaces里设定如下:
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
iface eth0 inet dhcp
address 192.168.1.9
netmask 255.255.255.0
network 192.168.1.0
broadcast 192.168.1.255
gateway 192.168.1.1
这里的解释说明了为什么host不能访问guest qemu. 实际上qemu有一个内置的dhcpserver,所以这就是为什么我的网络并无法看到qemu内的os。使用nmap -Pn 192.168.1.9可以看到系统是up,但是所有的packet都被丢弃了。
十一月十五日 等待变化等待机会
十一月十六日 等待变化等待机会
在#include <inttypes.h>
关于使用ipxe远程启动需要设定dhcp,/etc/dhcp/dhcpd.conf
allow booting;
allow bootp;
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.226 192.168.1.226;
option broadcast-address 192.168.1.255;
option routers 192.168.1.1;
option domain-name-servers 192.168.1.1;
}
INTERFACES="eth0"; ## 这个防止错误没有interface设定
next-server 192.168.1.115; ## 这个是tftp server的ip
if exists user-class and option user-class = "iPXE" {
filename "nfsboot.sh";
} else {
filename "ipxe.pxe"; ### 编译的时候在general.h设定nfs。
}
option space ipxe;
option ipxe-encap-opts code 175 = encapsulate ipxe;
option ipxe.priority code 1 = signed integer 8;
option ipxe.keep-san code 8 = unsigned integer 8;
option ipxe.skip-san-boot code 9 = unsigned integer 8;
option ipxe.syslogs code 85 = string;
option ipxe.cert code 91 = string;
option ipxe.privkey code 92 = string;
option ipxe.crosscert code 93 = string;
option ipxe.no-pxedhcp code 176 = unsigned integer 8;
option ipxe.bus-id code 177 = string;
option ipxe.san-filename code 188 = string;
option ipxe.bios-drive code 189 = unsigned integer 8;
option ipxe.username code 190 = string;
option ipxe.password code 191 = string;
option ipxe.reverse-username code 192 = string;
option ipxe.reverse-password code 193 = string;
option ipxe.version code 235 = string;
option iscsi-initiator-iqn code 203 = string;
# Feature indicators
option ipxe.pxeext code 16 = unsigned integer 8;
option ipxe.iscsi code 17 = unsigned integer 8;
option ipxe.aoe code 18 = unsigned integer 8;
option ipxe.http code 19 = unsigned integer 8;
option ipxe.https code 20 = unsigned integer 8;
option ipxe.tftp code 21 = unsigned integer 8;
option ipxe.ftp code 22 = unsigned integer 8;
option ipxe.dns code 23 = unsigned integer 8;
option ipxe.bzimage code 24 = unsigned integer 8;
option ipxe.multiboot code 25 = unsigned integer 8;
option ipxe.slam code 26 = unsigned integer 8;
option ipxe.srp code 27 = unsigned integer 8;
option ipxe.nbi code 32 = unsigned integer 8;
option ipxe.pxe code 33 = unsigned integer 8;
option ipxe.elf code 34 = unsigned integer 8;
option ipxe.comboot code 35 = unsigned integer 8;
option ipxe.efi code 36 = unsigned integer 8;
option ipxe.fcoe code 37 = unsigned integer 8;
option ipxe.vlan code 38 = unsigned integer 8;
option ipxe.menu code 39 = unsigned integer 8;
option ipxe.sdi code 40 = unsigned integer 8;
option ipxe.nfs code 41 = unsigned integer 8;
option ipxe.no-pxedhcp 1;
我在tftp serverde 路径设定了我的启动脚本:/var/lib/tftpboot/nfsboot.sh
这种菜单是我发现最可靠简单的。
#!ipxe
set boot-url http://192.168.1.115
set iso-file current.iso
set ubuntu-nfs /BigDisk/ubuntu-14.04
:menu
echo 1 kernel_http ubuntu (Memdisk) [1]
echo 2 kernel_tftp ubuntu (Memdisk) [2]
echo 3 initrd_chain ubuntu (Memdisk) [3]
echo 4 sanboot_one_line ubuntu (SANBOOT) [4]
echo 5 imgargs_memdisk ubuntu (Memdisk) [5]
echo 6 kernel_nfs ubuntu (nfs) [6]
read choice
goto menu_${choice} || goto menu
:menu_1
kernel memdisk
initrd ${boot-url}/${iso-file}
imgargs memdisk iso raw
boot || shell
:menu_2
kernel ${boot-url}/memdisk iso raw
initrd ${boot-url}/${iso-file}
boot || shell
:menu_3
kernel memdisk iso raw
initrd ${boot-url}/${iso-file}
boot || shell
:menu_4
initrd ${boot-url}/${iso-file}
chain memdisk iso raw || shell
:menu_5
sanboot --no-describe ${boot-url}/${iso-file} || shell
boot || shell
:menu_6
kernel nfs://192.168.1.115${ubuntu-nfs}/casper/vmlinuz.efi || shell
initrd nfs://192.168.1.115${ubuntu-nfs}/casper/initrd.lz || shell
imgargs vmlinuz.efi initrd=initrd.lz root=/dev/nfs boot=casper netboot=nfs nfsroot=192.168.1.115:${ubuntu-nfs} ip=dhcp splash -- || shell
boot || goto menu
sanboot可以直接boot iso,但是livecd看样子需要更多的支持,所以,你要把pxelinux的memdisk拷贝到tftp,或者你设定一个http server,放在那里,http比tftp快的多。
关于initramfs 和initrd的解说真好,看来关于linux的解析最适合我的是lfs,因为从实做开始,有代码有真相!主要是看代码最准确。
十一月十八日 等待变化等待机会
关于chroot,switch_root,pivot_root的异同比较难以理解,而且这个东西也有相当大的危险性需要明白清楚才行。目前的说法是initrd使用pivot_root,而initramfs使用switch_root因为前者是真正的文件系统,后者不是。我听说前者是有确定的blocksize,不能再扩展,后者则更灵活。
十一月十九日 等待变化等待机会
1.从编译内核的过程的讨论,这个是纯粹实际操作者的探索与观察。从Kernel config的角度看,两者要么都被enable,要么都不行。他们的形态在早期是纯粹的文件系统的映像,但现在都是cpio的格式,这个实际上也说明需要依赖于某个基本的文件系统的支持,通常ext2。另一个有趣的观察是initramfs实际上可以成为内核的一部分,就是直接编译进内核,而不需要单独的initrd,这个也解释了有些distribution可以不携带initrd,因为他们直接就编译在一个内核文件了,作者展示了默认的initramfs的代码,就是创建一个/dev/console的设备和一个/root目录,这个是最最简单的文件系统?这里也侧面说明了initramfs是一个和initrd不太一样的地方,因为前者是内核的一部分。
2。那么从功能的角度来解释为什么有了initrd又创造了initramfs,这个帖子的问题首先说明了历史的原因,就是initrd的实现是依赖于ramddisk,(而近期我在实验ipxe的boot的时候反复听到有人提到memdisk比较的耗费内存,这个也得到了解释)而这个设备是模拟block,但是在linux里的cache机制导致复制了一份内容,所以,浪费内存的由来在这里。帖子的问题提出引述了当年Linus的一个天才设计,把cache mount成为一个文件系统,这个就是initramfs的后面的tmpfs的由来。所以这个设计是非常的精巧的,在没有触动原来cache系统代码的情况下把cache自己作为一个文件系统,省去了复制的部分。而且回答者还指出这个机制也是实现共享内存的方式。这里的第一篇回答着重从文件系统组成来解释:VFS作为所有文件系统的抽象层始终都是最高一层,下面是具体的文件系统的实现层,最下面是实现文件系统的具体设备驱动层。VFS主要就是三个接口,inode是文件和目录的数据结构,dentry是目录里包含文件子目录的结构,file是真正的文件的打开读写关闭的接口。这里面有三种不同的object的cache,inode/dentry/page,最后一个是文件内容的cache,作者着重介绍了page cache,那么tmpfs是怎么实现的呢?我还没有看懂,否则这个天才的设计也不会是在linux一开始就有的,还是需要再学习的。总之它是文件系统应该做的最最简单的东西。
3.另一个回答者着重从linux kernel boot的过程来回答两者的异同,initrd是文件系统的镜像因此需要文件系统的驱动模块才行,而initramfs的驱动是kernel必须自带的,是tmpfs,是内核的一部分,所以两者的mount的方式是不同的。前者仿佛是创建了一个ramdisk的设备,然后使用dd直接写到设备,这个无疑就是任何block device的做法,可以明白为什么既慢又有缓存的重复。而后者不然,是类似于这样mount -t tmpfs nodev /root然后可以直接的解压缩cpio的archive,所以这里不需要明显的设备文件。
几个作者从不同的角度阐述initrd和initramfs的异同揭示了很多内核和操作系统的深层次的机制,并且给人对于早期启动过程一些深层次的演示让人有耳目一新的感受。(我是不是写的像小学生的中心思想和读书心得?)
我现在学习的方式基本上就是看文档,因为内核代码对我来说还是有些超前,阅读内核文档有一个高层面的认识还是没那么困难的。
十一月二十一日 等待变化等待机会
十一月二十二日 等待变化等待机会
十一月二十四日 等待变化等待机会
我很多时候感觉就是在一个无边无际的荒野上游荡,因为linux的世界是一个如此浩大的天地,任何一个小小的领域都是一片海洋,我偶尔拾起沙滩上的贝壳就欣喜不已了。
十一月二十六日 等待变化等待机会
十二月三日 等待变化等待机会
重新编译fltk发现它依赖libxi-dev这个是x11的extension。
十二月四日 等待变化等待机会
那么历史上是谁吵吵着引入initrd这个怪兽的?为什么需要这个庞然大物呢?这是因为早期的硬件驱动的困难之处,很多时候内核吃不准硬件是什么,只能探索着往一些寄存器写东西看看有啥反应,但是很多时候也许就把硬件搞乱了,而也许有时候确实需要把硬件reset再 启动来看更可靠,这些在硬件驱动领域的困难历程让人们很多时候编译大量的不同的内核每个也许只有很少量的驱动,因为很多时候不同的设备驱动彼此冲突,而一 个明显的解决方案是所谓的内核模块,这个道理很简单,你不能因为突然发现某个设备不能正常加载驱动就去重新编译整个内核,这个很多时候既危险也很困难,因 为编译内核的环境相当的复杂,而且相当的慢,最致命的是一旦失败有可能系统crash,而单独的可加载模块就算失败也不至于让整个内核失效。可是如何携带这么多的动态可加载的模块呢?这个当然就是Initrd的由来原因。它本身就是一快连续内存数据,memdisk能够把它创建为一个block设备在内核看起来是一个在内存中存在的磁盘设备,因此内核就可以运行在这样一个临时小OS里作更复杂的事情了,甚至于这个临时的系统也可以成为正式的系统如果你想要通通运行在内存中,这个是不是livecd的做法呢?当然了在作者写作的年代2000时候还没有initramfs出现,这个是后话。当然更直接的原因还是作者说的好,这个是一个鸡蛋和鸡的悖论,因为使用模块是需要文件系统的,因为很明显的每个模块都是一个文件,他们如何被调入内存如何运行是文件系统的责任,可是创建initrd的一个重要原因就是在文件系统建立之前帮助创建它,那么谁走先呢?细节就是创建一个/dev/initrd的磁盘设备把那一片连续内存当作一个磁盘文件系统的镜像。
引入initrd就引入了另一个高难度的杂技,作者形象的比喻为怎样站在地毯上来换地毯,注意这个不是飞毯啊。为什么呢?因为initrd的 使命就是在完成了各种复杂任务后建立真正的文件系统并且从当前的临时文件系统无缝的转移到新的文件系统,这个难道不是更换地毯的比喻吗?为什么这么难呢? 首先,每个可执行程序包括它依赖的库都是从当前文件系统的文件映射到内存的,如果更换当前文件系统,皮之不存毛之焉附?其次,基本输入输出和错误是不可或 缺的三大文件,被console广泛使用的这三个stdout/in/error怎么办?还有mount point和被service or daemon使用到的current directory怎 么办?这些问题看来都不是普通程序员所需要考虑的。不容易的工作啊。关于换地毯有两种方式一个是跳在空中然后把旧地毯抽走再同时把新地毯塞在脚下,褶皱的 部分随后再磨平。另一个相对难度小的做法是大多数家庭妇女都采用的就是把新地毯和旧地毯并排卷起来,一个收一个放,收多少放多少,还能回滚,还可以反复 来,这个方法好吧?事实上change_root和pivot_root就是这两个的活写真。前者粗暴的把旧的文件系统umount然后mount新的,但是如果遇到旧的正忙失败很有可能就让整个系统失败了。而后者可以逐步转移,同时新旧系统都还在还可以回滚或者多次反复调用。
十二月五日 等待变化等待机会
也许有人说这些陈芝麻烂谷子有什么意义呢?看看这里关于android的启动文件就知道了。这对于你理解不是很有帮助吗?
十二月七日 等待变化等待机会
十二月八日 等待变化等待机会
以前改古老的c的代码文件时候经常被编译器抱怨说文件结尾没有换行符,虽然是warning可是总是觉得有些莫名,这里解释的很清楚了,这个部分的文档活脱脱就是汇编器实现部分的语法定义:文件头是可以作为statement的分割,但是文件尾是不行的,必须要有换行:newline。
其实我花了一早上看汇编仅仅就是为了理解mbr的这个小小的汇编码,也就是mbr的定义而已,但是也是他的一个核心内容。
1.table.S86这个x86的汇编描述了一个512byte的mbr结构吧.
2. .org 0这个说的是起始须从0
3. dw 0 这个我一直感到有些不踏实,虽然一眼就明白是pad 0,但是找定义没有找到。原因是倒过来的,因为下面一句.space实际上可以填0,当然这样做保险。
4. .space 0x1be-2这个就是著名的partition table的起始位置。
注释里给出了partition table的结构
! 00 byte Boot indicator
! 01 byte start head
! 02 byte start sector
! 03 byte start cylinder
! 04 byte type
! 05 byte end head
! 06 byte end sector
! 07 byte end cylinder
! 08 dw sectors before partition
! 0c dw sectors in partition
看上去很简单,但是以下是我在mc里实际看到的来对比一下:
000001B0 00 02 90 C7 │ 12 00 80 00 │ 00 00 00 00 │ A8 01 80 21
000001C0 03 00 83 6B │ EE FD 00 08 │ 00 00 00 D8 │ 77 00 00 00
000001D0 00 00 00 00 │ 00 00 00 00 │ 00 00 00 00 │ 00 00 00 00
000001E0 00 00 00 00 │ 00 00 00 00 │ 00 00 00 00 │ 00 00 00 00
000001F0 00 00 00 00 │ 00 00 00 00 │ 00 00 00 00 │ 00 00 55 AA
这里还有一个小技巧,在ubuntu下使用midnight commander(mc)如何copy呢?我首先把terminal最大化,然后在菜单里的edit/select all之后copy再粘帖到gedit里面很棒的,可惜我再次copy到html编辑器就走样了。
注意以上地址是1be-2也就是高亮部分01就是说boot enabled,这个就是你使用fdisk设定的?(我怎么觉得这个partition table和mbr是毫无关系的?我肯定是胡说吧,需要作实验才知道。)然后是head(80)sector(21)cylinder(03),
我的fdisk的输出如下:
Device Boot Start End Blocks Id System
/dev/sdb1 * 2048 7856127 3927040 83 Linux
所以我需要知道chs的计算方法,究竟2048byte是怎么转换成chs的?这个是一个非常简单的问题,可是我忘了。
我无法解释观察到的问题,究竟这个partition table的偏移是怎么算出来的呢?而且我开始怀疑1be-2的位置,因为type83对应的是linux这个似乎多了一个byte的偏移?2048=32*64说明head应该是32=0x21但是sector应该为0而不是0x03所以怎么也对不上。也许我需要一个正确安装了的mbr来实验。
事实证明我是瞎折腾,我把我的usb的512byte清零,然后重新install-mbr结果partition完全是空的。
事实上看install-mbr的代码它也根本没有能力去读取partition table,你倒是可以提供一个参数文件知名partition table的情况。那么是谁写了partition table呢?当然是fdisk了,我使用fdisk之后结果就是以上。所以,我需要看fdisk的代码,顺便说以下,这个包是util-linux
十二月九日 等待变化等待机会
struct partition {
unsigned char boot_ind; /* 0x80 - active */
unsigned char head; /* starting head */
unsigned char sector; /* starting sector */
unsigned char cyl; /* starting cylinder */
unsigned char sys_ind; /* What partition type */
unsigned char end_head; /* end head */
unsigned char end_sector; /* end sector */
unsigned char end_cyl; /* end cylinder */
unsigned char start4[4]; /* starting sector counting from 0 */
unsigned char size4[4]; /* nr of sectors in partition */
} PACKED;
所以,这个partition的起始head=0x21,sector=0x03,cylinder=0x00,结尾head=0x6b,sector=0xee,cylinder=0xfd,starting logical sector=0x0800,size of sector=0x77d800 类型当然是linux=0x83
让我现在来验算一下:0x0800=2048这个是和fdisk输出一致的,但是head=0x21=33按照63sector/head来算已经是33*63=2079了唯一能对的上的是32*64=2048,但是sector=0x03怎么解释呢?难道说所谓的起始sector之前还有所谓的sector?那么size对吗?
Starting sector=0x0800+number of sectors=0x77d800 = end sector number=0x77e000=7856128这个和fdisk报告的7856127似乎是符合的(从0开始减一??)但是所谓的ending cylinder=0xfd,ending head=0x6b,ending sector=0xee要怎么算呢? cylinder=0Xfd=253, head=0x6b=107,sector=0xee=238,按照255heads/cylinder,63sector/head计算253*255*63+107*63+238根本不沾边?所以只能再去看fdisk的代码,还是老祖师的那句话:RTFC!!!
十二月十日 等待变化等待机会
当前只有等待等待编译util-linux在debug模式然后跟踪,当然之前也读代码好几遍,只是确认一下,其实是读代码有时候会跟丢了,fdisk的代码不难懂,可是毕竟全部都是使用全局变量比较的让人不乐见。list模式没有问题,当然是从之前的mbr读出来的,size是结合了blkdev得到的partition的size,否则如果未定义使用blkdev就使用最原始的探索,反复用lseek/read来看device是否可读,使用的算法是binary search之类,每次加倍,最后失败在使用binary search找到成功的大小,使用blkdev其实也很简单,就是/proc/partition读出的数据,这个是blocksize,我这里有些迷惑的是,ext2的blocksize默认是1k吗?似乎是,不过我记得很多大磁盘使用的是4k,总之转换为sector默认512就加倍了,这个是需要注意的。接下来才是真正的问题,就是怎么addnewpartition的计算chs的。十二月十一日 等待变化等待机会
当前只有等待等待说起来就是一肚子气,如此简单的问题我却折腾了一天多,可能脑子就是不开窍,所谓的传统就是如此,我不知道从什么时候被灌输了LBA的概念以为所有的磁盘系统都是使用标准的chs的计算方式,肯定是我误解了。也就是说你需要先知道你的head/sector才能知道具体的starting head/starting sector,可是这个是古老的年代当磁盘没有控制芯片你需要告诉机械臂我要把磁盘转到哪个扇区需要这些参数,所谓的LBA就是说这个工作磁盘控制器帮你做了,你只要说出sector,控制器自己去控制转到对应的head,我却还以为大家统一了head=63,sector=255才做到LBA,这个就是理解的误区,并不是制造商统一了磁盘参数而是控制器做到了自动,让你不用关心这个参数。想想看古老年代为什么要有很多的alignment的限制,肯定就是OS直接发令给机械磁盘转动到某个位置有可能效率不高啊,比如你不能同时读取所有sector,所以让你有限制地创建partition的开始。所以,回到问题的开始,之所以我看到的starting sector/head很奇怪实际上是因为我的磁盘的head=62,sector=62,cylinder=1021,所以,现在看起来一点不奇怪,fdisk按照古老的起始2048个sector的老办法,那么起始的head就是32因为每个head有62个sector,所以,最后余下3个sector,33*62+3=2049,至于说2048和2049我懒的追究了,fdisk里面充斥了类似的偏移这里加一那里减一的,或者就是我从零数数都不懂,总之,你需要知道的是这个{heads = 124 '|', sectors = 62 '>', cylinders = 1021, start = 0}的来源是linux kernel,调用这个函数ioctl(fd, HDIO_GETGEO, &geometry)其中define HDIO_GETGEO 0x0301struct hd_geometry {
unsigned char heads;
unsigned char sectors;
unsigned short cylinders; /* truncated */
unsigned long start;
};
我对于fdisk诉说cylinder被truncated而弃置不用有些将信将疑,如果查看/proc/partitions得到的block总数是3928064,换算为sector是加倍7856128,那么从kernel的HD geometry函数得到的1021*124*62=7849448我的理解是这个cylinder是准确的,因为结尾的确还有ending head/ending sector没有加上,很可能fdisk说的是老版本的kenerl了。所以,我觉得fdisk完全不需要费力的去计算cylinder直接采用kernel的值1021就行了。至此关于starting sector/head/cylinder的谜团揭开了,那么ending head/sector/cylinder就应该是从总的sector数反推的,我懒的再看代码了,有这个时间还不如看看gnu disk的实现,fdisk我觉得很多人都有诟病吧毕竟太老了。(这个年头真的有人关心磁盘分区的问题吗?)
总结一下就是mbr的磁盘分区内容就是1be偏移开始的地方,mbr的启动小汇编代码倒是可以看看怎样在两三百个byte里去load这个磁盘分区地址指示的boot sector的。这个才是核心,应该有一个地方指示了第几个分区是启动区,并且在512-2,512-1有mbr的magic number:0x55aa。当然每个partition有标注自己的类型,比如dox/linux等等,以及是否为activated:0x80或者是extended,同时在偏移0x1B8=440处写的dos label,通常就是id的hex形式。顺便说一下,在fdisk的高级模式下查看partition table,让我验算一下:
ending head=107,sector=46,cylinder=1021,start sector=2048,total sector=7854080: 7854080+2048=7856128这个是/proc/partitions得到的。1021*124*62+107*62+46=7856128所以,这个证实了ending sector/head/cylinder是用总数倒推出来的,代码也是如此,我也懒得找了,fdisk里面很多宏没有什么解释移位来来去去很难理解。
Disk /dev/sdb: 124 heads, 62 sectors, 1021 cylinders
Nr AF Hd Sec Cyl Hd Sec Cyl Start Size ID
1 80 33 3 0 107 46 1021 2048 7854080 83
你回过头来再看fdisk有些显示真实把你气死非常的误导:
nick@ubuntu-14:~/travel/util-linux-2.20.1/fdisk$ sudo fdisk -l /dev/sdb
Disk /dev/sdb: 4022 MB, 4022337536 bytes
108 heads, 46 sectors/track, 1581 cylinders, total 7856128 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x84300bd9
Device Boot Start End Blocks Id System
/dev/sdb1 * 2048 7856127 3927040 83 Linux
这里108heads,46sectors,1581cylinder在讲天书啊?说的是结尾的位置,哪里蹦出来一个1581cylinder?
十二月十二日 等待变化等待机会
gcc -E -xc mbr.S86 -o mbr.s86.tmp && mv mbr.s86.tmp mbr.s86
as86 -0 -b mbr.b.tmp -s mbr.sym -l mbr.lst mbr.s86 && mv mbr.b.tmp mbr.b
ld -r -b binary -o mbr.o mbr.b
gcc -DY2KBUG -E -xc mbr.S86 -o y2k.s86.tmp && mv y2k.s86.tmp y2k.s86
as86 -0 -b y2k.b.tmp -s y2k.sym -l y2k.lst y2k.s86 && mv y2k.b.tmp y2k.b
ld -r -b binary -o y2k.o y2k.b
gcc -Wall -Wstrict-prototypes -Wmissing-prototypes -g -O0 -g -O0 -o install-mbr install-mbr.o mbr.o y2k.o
gcc -DTESTDISK -E -xc mbr.S86 -o testdisk.s86.tmp && mv testdisk.s86.tmp testdisk.s86
as86 -0 -b testdisk.b.tmp -s testdisk.sym -l testdisk.lst testdisk.s86 && mv testdisk.b.tmp testdisk.b
rm mbr.s86
因为install-mbr是c代码没有多少干货就是传参数拷贝,因为核心部分是那个真正的loader就是mbr.S86,这个是因为bios是初始化使用i286运行的16位,当然我可以使用as86来汇编,所以要安装bin86包,它带有as86汇编器。至于说你要使用objdump查看汇编因为我是x86_64系统objdump理所当然的有很多汇编指令不认识,bing看到这个参数:objdump -D -mi386 -Maddr16,data16 mbr
它不但要求使用i386汇编器指令还需要16位的内存寻址才行。这样子的结果和mbr.S86的汇编源代码是一致的,当然这个是毫无意义的,难道你怀疑汇编器有问题吗?只不过是验证而已。mbr.S86有不少的注释,首先,bios是把mbr这个boot sector加载到内存0x7c00处,可是我们的这个所谓的loader的目的是要把真正的bootloader加载到这个地址,所以,它把自己拷贝到0x600的地址。(这一点要再确认)(需要吗?不需要。以下是汇编码证明。)
b: be 00 7c mov $0x7c00,%si
e: bf 00 06 mov $0x600,%di
11: b9 00 01 mov $0x100,%cx
14: f3 a5 rep movsw %ds:(%si),%es:(%di)
首先设置起始地址也就是我们目前被bios加载的地址0x7c00到si寄存器,然后设定目标地址0x600到di寄存器,然后拷贝0x100个word长度也就是512bytes,所以整个mbr被挪到了0x600位置。
十二月二十日 等待变化等待机会
十二月二十一日 等待变化等待机会
十二月二十二日 等待变化等待机会
In shell command, if you have special character like “&”, you need to quote it. Clearly it is
[root@rh63-58-110 Linux_x86_64]# objdump -s -j .rodata ./VMCLIEXE | less
41ae80: 6d 62 65 72 0a 00 00 00 20 2d 2d 64 69 72 65 63 mber.... --direc
41ae90: 74 6f 72 79 2d 70 72 65 66 69 78 3d 25 73 20 20 tory-prefix=%s
41aea0: 2d 2d 70 72 65 66 65 72 2d 66 61 6d 69 6c 79 3d --prefer-family=
41aeb0: 49 50 76 36 20 20 2d 2d 63 6f 6e 6e 65 63 74 2d IPv6 --connect-
41aec0: 74 69 6d 65 6f 75 74 3d 31 20 2d 2d 72 65 61 64 timeout=1 --read
41aed0: 2d 74 69 6d 65 6f 75 74 3d 31 32 30 20 20 2d 2d -timeout=120 --
41aee0: 74 72 69 65 73 3d 32 20 2d 2d 6b 65 65 70 2d 73 tries=2 --keep-s
41aef0: 65 73 73 69 6f 6e 2d 63 6f 6f 6b 69 65 73 20 2d ession-cookies -
41af00: 2d 6e 6f 2d 76 65 72 62 6f 73 65 20 2d 71 20 2d -no-verbose -q -
41af10: 2d 75 73 65 72 2d 61 67 65 6e 74 3d 56 4d 43 4c -user-agent=VMCL
41af20: 49 20 2d 2d 73 61 76 65 2d 63 6f 6f 6b 69 65 73 I --save-cookies
41af30: 20 25 73 20 20 2d 2d 6e 6f 2d 63 68 65 63 6b 2d %s --no-check-
41af40: 63 65 72 74 69 66 69 63 61 74 65 20 20 2d 2d 70 certificate --p
41af50: 6f 73 74 2d 64 61 74 61 3d 22 57 45 42 56 41 52 ost-data="WEBVAR
41af60: 5f 55 53 45 52 4e 41 4d 45 3d 25 73 26 57 45 42 _USERNAME=%s&WEB
41af70: 56 41 52 5f 50 41 53 53 57 4f 52 44 3d 25 73 22 VAR_PASSWORD=%s"
41af80: 20 68 74 74 70 73 3a 2f 2f 25 73 3a 25 64 2f 72 https://%s:%d/r
41af90: 70 63 2f 57 45 42 53 45 53 2f 63 72 65 61 74 65 pc/WEBSES/create
41afa0: 2e 61 73 70 00 63 72 65 61 74 65 2e 61 73 70 00 .asp.create.asp.
41afb0: 25 73 25 73 00 67 65 74 73 65 73 73 69 6f 6e 74 %s%s.getsessiont
41afc0: 6f 6b 65 6e 2e 61 73 70 00 67 65 74 72 6f 6c 65 oken.asp.getrole
我做了一个简单的验证,但是我现在回过头来看不知道为什么我的结论是vmcli的这个常量字符串有问题?明明是有quote的,为什么我当时在笔记里说不行?也许我头脑想反了?难不成我认为c代码里的这个常量字符串需要escape character,我头脑比较混乱。
而且我当时看到的错误似乎完全不相关:
The
command is:
[root@rh63-58-110 Linux_x86_64]# ./VMCLIEXE -r
172.17.59.189:443 -u admin -p admin -c /home/Downloads/fifth.iso
The
log shows:
Mon Jul 31 15:39:42 2017 Warning (6): Check if Wget is
installed on Client machine
Mon Jul 31 15:39:42 2017 Error (1):
Unable
to connect to the server: 172.17.59.189 : Check HTTPS port
: Check HTTPS Port
这个是我的简单的测试程序似乎再证明vmcli没有问题?
#include <stdio.h>
#include <stdlib.h>
const char* param = "wget --directory-prefix=%s --prefer-family=IPv6 --connect-timeout=1 --read-timeout=120 --tries=2 --keep-session-cookies --no-verbose -q --user-agent=VMCLI --save-cookies %s --no-check-certificate --post-data=\"WEBVAR_USERNAME=%s\&WEBVAR_PASSWORD=%s\" https://%s:%d/rpc/WEBSES/create.asp";
int main(int argc, char**argv)
{
char buffer[2048];
char* sDirPrefix = "123456789";
char* sCookieFile = "123456789/cookie.txt";
char* sUser = "admin";
char* sPassword = "admin";
char* sIp = "172.17.59.189";
int nPort = 443;
sprintf(buffer, param, sDirPrefix, sCookieFile, sUser, sPassword, sIp, nPort);
int ret = system(buffer);
printf("return value: %d and its status %d of command: %s\n", ret, WEXITSTATUS(ret), buffer);
return 0;
}
我是否记录过这个问题呢?就是ubuntu的apt的proxy的设置。
it needs a apt.conf to tell how to acquire proxy:
Acquire::http::proxy "http://<yourproxyserver>:<Port>";
Acquire::https::proxy "http://<yourproxyserver>:<Port>";
Acquire::ftp::proxy "http://<yourproxyserver>:<Port>";
Acquire::http::proxy "http://<domain\user>:<password>@<yourproxyserver>:<Port>";
Acquire::https::proxy "http://<domain\user>:<password>@<yourproxyserver>:<Port>";
Acquire::ftp::proxy "http://<domain\user>:<password>@<yourproxyserver>:<Port>";
我翻阅我的工作笔记看到以下莫名其妙的文字,这究竟在说些什么?
Certificates on their own are only public pieces of information. What links a public key certificate to the name it contains is the fact that whoever has legitimate control over that name (e.g. your name or your server's name) also has the private key for it.
Certificates are used to prove the identity of the remote party by challenging the remote party to perform an operation that can only be done with the corresponding private key: signing something (which can be verified with the public key) or deciphering something that was encrypted with the public key. (Both can happen in the SSL/TLS handshake, depending on the cipher suite.)
During the SSL/TLS handshake, the server sends its certificate (in clear) and proves to the client that it has the corresponding private key using an authenticated key exchange.
In your case, you also want to use client-certificate authentication. It's not enough to send the client certificate during the handshake: the client must also prove it has the private key. Otherwise, anyone who receives that certificate could clone it. The point of using certificates is to prevent any cloning, in such a way that you never have to show your own secret (the private key).
More specifically, the client has to sign the handshake messages in the Certificate Verify message of the TLS handshake so that the server can verify it against the public key sent in the client certificate. Without this step, no client-certificate authentication would be taking place.
the client certificate was given to me by the third party, but it does not contain any private key
Giving you your certificate without its private key seems a bit pointless, unless you're expected to have generated a certificate request on your side beforehand (in which case you would have the private key).
Indeed, rather than being given a certificate and its private key, it's better practice for you to generate your key-pair, create a certificate request (CSR), and have your CA issue a certificate from that CSR (but without them ever knowing your private key). In this case, you would be expected to have kept your private key, and you would be able to use it with the cert you would have received.
我大约记得以上部分是我从stackoverflow上google来的,解释的是关于certificate的问题,我现在理解是说:所谓public/private key pair是互为加密解密的钥匙,就是说你用你的privatekey来加密的部分成为你的certificate,当然其中包含了public key作为certificate的一部分,任何人都可以使用这个明文的public key来解密这个certificate来验证这个证书的确是你使用你的privatekey加密的,原因是没有人能够根据publickey来猜出你的privatekey,这个理由就是分解两个质数的乘积没有捷径。
我以前记得提过这个,是否有详情?
I compare some headers of snmpget with our libsnmp++ and see that snmpget(a part of http://www.net-snmp.org/download.html ) has some float/double type defines like in asn1.h
#define ASN_APP_FLOAT (ASN_APPLICATION | 8)
...
#define ASN_OPAQUE_FLOAT (ASN_OPAQUE_TAG2 + ASN_APP_FLOAT)
And my gdb snmpget shows it knows the return pdu has type of float.
And in libsnmp++ asn1.h, there is no ype of float or double defined.
So, I guess libsnmp++ is lack of native support of float or double when encoded with octlet tag...
十二月二十三日 等待变化等待机会
十二月二十四日 等待变化等待机会
他的代码有一个有意思的地方,虽然是很小的东西一点就破,可是我不说你还真不知道为什么。比如原理是如此的简单,查看magic然后在临时目录下编译源代码然后fork然后根据返回的pid,如果是0就是child Process,通常我们是去执行exec,可是它不时地,反而child process去while(kill(getppid(),0)>=0)sleep(1);而如果pid>0也就是parent process,它反而去execvp.这是为什么呢?难道代码逻辑有误?当然不是,其实有谁规定了一定要parent process必须是原来的,一定要childprocess去执行?本身这个使用fork只是保障exec之后有人保障unlink那个临时文件,所以,这个工作无论是parent还是child都可以做到,使用parent process去execvp按照作者注释的解释:The reason the compiled program is execed as the parent program is to allow use of same PID for the compiled program, so that it is possible to use "strace" "kill -HUP" and other conventional methods of debugging.
十二月二十五日 等待变化等待机会
nick@ubuntu-14:~$ /bin/kill -L
1 HUP 2 INT 3 QUIT 4 ILL 5 TRAP 6 ABRT 7 BUS
8 FPE 9 KILL 10 USR1 11 SEGV 12 USR2 13 PIPE 14 ALRM
15 TERM 16 STKFLT 17 CHLD 18 CONT 19 STOP 20 TSTP 21 TTIN
22 TTOU 23 URG 24 XCPU 25 XFSZ 26 VTALRM 27 PROF 28 WINCH
29 POLL 30 PWR 31 SYS
在man 7 signal里有详细的解说关于每一个signal。(Where three values are given, the first one is usually valid for alpha and sparc, the middle one for x86, arm, and most other architectures, and the last one for mips)
Signal Value Action Comment
SIGHUP 1 Term Hangup detected on controlling terminal or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
SIGCHLD 20,17,18 Ign Child stopped or terminated
SIGCONT 19,18,25 Cont Continue if stopped
SIGSTOP 17,19,23 Stop Stop process
SIGTSTP 18,20,24 Stop Stop typed at terminal
SIGTTIN 21,21,26 Stop Terminal input for background process
SIGTTOU 22,22,27 Stop Terminal output for background process
Next the signals not in the POSIX.1-1990 standard but described in
SUSv2 and POSIX.1-2001.
Signal Value Action Comment
SIGBUS 10,7,10 Core Bus error (bad memory access)
SIGPOLL Term Pollable event (Sys V).
Synonym for SIGIO
SIGPROF 27,27,29 Term Profiling timer expired
SIGSYS 12,31,12 Core Bad argument to routine (SVr4)
SIGTRAP 5 Core Trace/breakpoint trap
SIGURG 16,23,21 Ign Urgent condition on socket (4.2BSD)
SIGVTALRM 26,26,28 Term Virtual alarm clock (4.2BSD)
SIGXCPU 24,24,30 Core CPU time limit exceeded (4.2BSD)
SIGXFSZ 25,25,31 Core File size limit exceeded (4.2BSD)
Next various other signals.
Signal Value Action Comment
SIGIOT 6 Core IOT trap. A synonym for SIGABRT
SIGEMT 7,-,7 Term
SIGSTKFLT -,16,- Term Stack fault on coprocessor (unused)
SIGIO 23,29,22 Term I/O now possible (4.2BSD)
SIGCLD -,-,18 Ign A synonym for SIGCHLD
SIGPWR 29,30,19 Term Power failure (System V)
SIGINFO 29,-,- A synonym for SIGPWR
SIGLOST -,-,- Term File lock lost (unused)
SIGWINCH 28,28,20 Ign Window resize signal (4.3BSD, Sun)
SIGUNUSED -,31,- Core Synonymous with SIGSYS
其实以上照抄manpage似乎毫无意义,大多数的signal我一辈子都不一定会用到,我只不过从来没有听说过HUP这个,确实是孤陋寡闻,假如binfmt-interpreter创建的childprocess去按照习惯execvp执行编译好的可执行程序,而parentprocess使用waitpid等待那么对于debug确实是比较罗嗦因为你gdb到fork以后你要根据返回的pid再去远程gdb这个pid。而以下的代码确实很经典值得借鉴。首先,fork返回0的是childprocess,那么先把自己至于后台也就是daemon(0,0),根据manpage如果两个参数都是0的话,首先chdir到”/”,其次把stdout/in/err都转向到/dev/null。这样子我们的子进程就不会干扰真正执行的程序了,而这一步也正是父进程所期待的waitpid需要得到的。我觉得waitpid所说的childprocess的state
change不是指的daemonize这一步而是sleep。daemonize只是把前台让给父进程,或者原来前台就是父进程的,子进程不想干扰而已。那么作为子进程监听父进程就只能使用getppid得到的parent_pid来持续假装kill使用一个特殊signal
“0”来检验父进程是否存在,根据kill的manpage,这个0照样需要错误处理只不过没有发出任何的实质的signal而已。这个是一个很实用的技巧,因为作为父进程简单的waitpid就可以监控子进程,可是作为子进程就只有这个办法了。
而以下代码中的父进程则需要先等待子进程进入到休眠状态后才去execvp。不要忘记execvp之后一行代码打印错误,你正常执行execvp是不会返回到这里的,嫁出去的女儿是不会回娘家的,回来的都是被休掉的,所以要打印错误,这个是基本常识,只不过我觉得我会遗漏。当然毫无疑问的这个编译后的可执行程序被删除的工作只有子进程才能做到了,为什么呢?理由同上了,正常的execvp是不会返回的,同样的函数的最后的返回也是预备给这个情况的。以下的代码可以保证我们使用gdb一直跟踪执行到原本的C代码文件里,这也就是binfmtC的目的让你似乎以为c代码可以被直接当作脚本执行。
int exec_prog(const char * filename, int argc, char**argv)
{
int pid;
int parent_pid;
switch(pid=fork())
{
case -1:
/* fork failed */
fprintf(stderr,
"binfmtc: Failed to fork \n");
return EXIT_FAILURE;
break;
case 0:
/* when I am the child process, unlink the file after the parent
process has exited.
*/
parent_pid=getppid();
if (daemon(0,0) < 0)
{
exit (-1);
}
while ((parent_pid!=-1)
&& (kill(parent_pid,0) >= 0))
{
sleep(1);
}
unlink(filename);
exit(0);
default:
/* I am the parent process, exec into the built program */
waitpid(pid,NULL,0);
execvp(filename, argv);
fprintf(stderr,
"binfmtc: failed execvp of %s \n", filename);
break;
}
return EXIT_FAILURE;
}
查看linux kernel的binfmt唯一能看懂的就是这个是实现在文件系统之上?成为内核的一部分,当然也是linux支持的可执行格式的实现?总之我已经忘了为什么看到这里,原本是systemd的问题?
关于plymouth的图形问题找到了这个,首先下载相应的plymouth的theme,然后使用update-alternatives –config default.plymouth选择下载的theme.然后update-initramfs -u这个参数仅仅修改initramfs,这个很好用的命令。实验以下。
十二月二十五日 等待变化等待机会
十二月二十六日 等待变化等待机会
十二月二十七日 等待变化等待机会
十二月二十九日 等待变化等待机会
这里是我的猜想,有两个rom,一个是安全机制,一个是正常机制,但是即便是没有安全同样的两个rom并不会少只不过是被disable了安全机制而已,那么对于non-XIP的code要求一个header指名size和目标地址就很容易理解了,很可能是上电后直接执行安全rom的地址,这里如果是xip很简单没有问题,但是如果是所谓mmc的话,目标地址也是写死了,等到这个逻辑在内存里站住脚了再去执行另一块rom的代码,这里就需要所谓的GP header要写明size和目标地址了。
十二月三十日 等待变化等待机会
我发现还是结合阅读linux kernel的文档是一个很好的学习的方式,因为那里的文档不但言简意赅,更重要的有很多延伸阅读给你很多的线索,比如我觉得我应该要去好好理解dts/dtb的设计,因为我几乎是一无所知根本看不懂,唯一知道的是device tree的设计最早是Linus不满大量的代码被用来描述设备。文档里的开头就把我引导了启动部分,而arm/booting的这段文字我需要深刻的理解:
Essentially, the boot loader should provide (as a minimum) the
following:
![]()
{kind=link}
{kind=link}
{kind=link}