Algorithm...
Memorandum for NPC problem
This Wednesday I visited professor during his office hour after a lecture and lab demo. I learned a lot and should write them
down immediately. However, I was too tired and still had a lecture in the evening. Therefore, I write them down now.
1. Is polynomial reduction function mapping problem instances between two problems in an Isomorphism manner?
No. Actually the phrase of "mapping problem instances between two problems" is an oversimplification of my own which is not
accurate and I will discuss them in a short time.
2. The second question is actually similar to the first one: The function is not even ONTO if you still think in my
oversimplified logic understanding.
3. The definition is like this:
The following is something I understand and partly copied from textbook.
Let's use binary encoding to represent our problems. The polynomial reduction function is defined:
f: star({0,1})--->star({0,1}) where star(L) stands for Kleene star of language L.
So, the f is nothing but a string of 0's and 1's.
Then we have the definition of decision problems:
L={x in star({0,1}): Q(x)=1}
The problem is a language such that there exists an algorithm which can accept it. And what's more, the decision problem is that
the algorithm not only accepts it if x is in the language, but also rejects it if x is not in the language.
Is it meaningful to ask if polynomial reduction function is ONTO or not? Of course not! star({0,1}) can never be covered.
4. In the textbook, it gives a method to prove that a language L is NP-complete.
a) Prove L in NP;
b) Select a known NP-complete language L';
c) Describe an algorithm that computes a function f mapping every instance x in star({0,1}) of L' to an instance f(x) of L.
d) Prove that the function f satisfies x in L' if and only if f(x) in L for all x in star({0,1});
e) Prove that the algorithm computing f runs in polynomial time.
My intuition is that if in d), it is enough for us to prove f satisfies that if x in L' then f(x) in L for all x in star({0,1}).
Because it says that for all instance in L' we can always reduce them into an instance in L. Therefore L is AT LEAST as difficult
as L'. Hence, L is a NP-complete problem. Why do we bother to prove the converse proposition?
The answer is still within the definition of formal language. The language is simply defined as strings of 0's,1's. We need to
make sure the strings do make sense to language L'. ( I am a kind of convinced by professor's explanation, but begin to doubt now.)
5. A common mistake is to assume N-color-map problem is exactly biggest size of clique problem.
6. I try to persuade myself that some proof of NP-complete problem would be easier to choose appropriate known NPC problem. I just
wonder if there is any sequence in NPC. Professor says no. Then, by logic if I can reduce L to L', I should also be able to reduce
L' to L if L, L' are all NPC problems.
Reduce, Reduce, Reduce
...
The answer:
It is a illusion to view the LHS of inequality is a special case compared with RHS. On the contrary, LHS is a more general case.
Can you reduce small to big? Surely not. It is very misleading the direction of "<p" which implies the RHS is bigger which is
completely nonsense. Observe that every fifty-fifty is a special case of subset-sum while subset-sum may not be able to transfer
to a fifty-fifty.
To show the evaluation function of A* algorithm is monotonely non-decreasing.
Definition of A* algorithms is:
Consider evaluation function f(n)=g(n)+h(n) where g(n) is the actual cost from start state to state n and h(n) is the always less than or equal to the cost of the "minimal" path from n to goal state, then such "best-first search" algorithms is a A* algorithm.
proof: consider two state i,j where j is descendant of i. By definition of A* algorithm,
h(i)-h(j)<=cost(i,j) (a and since g(n) is actual cost from start state to n, g(n) is always bigger than or equal to cost of minimal path from start state to state n. Therefore, cost(start, i)<=g(i) and cost(start, j)<=g(j), then we know, cost(i,j)=cost(start,j)-cost(start,i)<=g(j)-g(i) (b
then f(j)-f(i)=g(j)-g(i)+h(j)-h(i)>=
cost(i,j)-(h(i)-h(j))>=0
Recall the definition of monotonicity of heuristic is like this:
Definition of monotonicity of heuristics is if:
1. For all state i, j where j is descendant of i, h(i)-h(j)<=cost(i, j) where cost(i,j) is the actual cost from state i to state j;
2. h(goal)=0 which means the heuristic function for goal state is 0;
It is raining hard while I am getting the textbook back.....
Quoting nick huang <nickhuang99@hotmail.com>:
> hi,
>
>
> I spent a whole day in thinking about the proof of "monotone heuristic
> implying A* algorithm" on textbook of page142(4th edition), I feel a
bit
> confused and suspect there is a possible flaw in this proof.
Your feeling is correct.
Perhaps Luger's txtbook is not well written. I had the same problem
when I
first read this textbook.
> On the text, it uses h(s1)-h(s2)<=cost(s1,s2) as the property of
monotone.
OK, that is a definition. And by this definition, monotonicity will be
a
special case for admissibility. (sorry, I forget what is admissibility.)
> But by definition of monotone heuristic, this "cost" function is the
"actual"
Yes. "actual cost" is prinited there. But Luger might want to say "any
possible actual cost".
I guess, "any possbile actual cost" is the right word to put there.
See "One way to describing the monotone property is that the search
space is
everywhere locally consistent....", and the next sentence "The
difference
between the heuristic meansure for a state and any one of its successors
is
bound by the actual cost of going ..."
All these statements give hints that Luger is talking about "any
possibly path
from a node to its successor" instead of a fixed actual path.
> cost from state s1 to s2 instead of cost of "mininal path" from s1 to
s2.
> Since we haven't proved that monotone heuristic gurantees to produce
optimal
> solution, we cannot claim that the "actual cost" is the cost of
"minimal
> path". However, by definition of A* algorithm, only those algorithms
such
> that the heuristic function h(n) is smaller than or equal to the cost
of
> "minimal path" from n to the goal is considered as A* algorithm. So, I
guess
> the textbook is using "actual cost" to represent "cost of minimal
path" to
> prove.
If my conjecture above is right, then "minimal path" is just one kind
of path
out of many possibility and is already covered in the definition of
"monotonicity".
>But this is not correct since actual cost is always bigger than or
> equal to cost of minimal path, so this doesn't prove
h(s1)-h(s2)<=cost(s1,s2)
> of minimal path.
>
> By the way, if this proof is valid, we even don't have to employ such
> summation procedure, just by definition of monotone of
> h(n1)-h(n2)<=cost(n1,n2)
> plug in n2=goal state and get for any state n1 such that
> h(n1, goal)<=cost(n1, goal) to reach the conclusion.
I can not understand the above two lines. Do you misprint something
there?
>
> Surely you wouldn't agree this proof, would you?
>
> Thank you for your time and awaiting your reply promptly,
>
> have a nice day,
>
> nick huang/qingzhe huang
>
go from nick
hi,
Thank you for your message and detailed explanation!
1. Your conjecture is interesting, but I am not convinced yet because
a) If "actual cost of any possible path" is what Luger wants to express, he probably would invent a new concept for this because it is not so obvious.
b) This will make A* algorithm and monotonicity a bit similar, see A* only requires each state to compare with goal state and monotonicity requires each two state to compare. Is this a bit too close to invent two concept?
c) The line you said you don't follow is like this: if the "cost" in monotonicity is referring to cost of minimal path, then the proof is quite simple. Even simpler than what is showed in text on page 142. You see, you only need to prove "for all states n, if h(n)-h(goal)<=cost(n, goal), then it is A* algorithm." (Please check definition of A* algorithm) However, by definition of monotone, h(goal) is 0. So, this is always true which means we already proves monotone is A* algorithm. But this seems too easy and we even don't need the summation procedure.
2. A* and monotone can be drawn as graph like this:
(evaluation function f=h(n)+g(n)
| -------------| both A* and monotone converge at goal state
| ----------- ------ |
A* |------- ----------- |
| ------ |
mono |------ |
| |
|_________________________________ (state space n)
(start state) (goal state)
If the y-axis is f=g(n)+h(n) and x-axis is state space n, then both curve of A* and monotone is non-decreasing(This can be proved easily.) and they both converge at goal state because in case of A* f(goal)=h(goal)+g(goal) where h(goal)=0 since the minimal path from goal to goal is 0 and h(goal)<=0, and in case of monotone, f(goal)=h(goal)+g(goal) where h(goal)=0 by definition. So the two line converge at coordinate of (goal, g(goal)).
However, the starting point may not be same because g(start) are always 0, and h(start) in case of A* is different from h(start) in monotone.
I have a feeling that we might be able to prove by contradiction that the two curve is coincided even at start point, but I tried and failed, maybe you can do that.
3. Nice to discuss with you.
have a nice day,
come from DY
> hi,
>
> Thank you for your message and detailed explanation!
> 1. Your conjecture is interesting, but I am not convinced yet because
> a) If "actual cost of any possible path" is what Luger wants to express, he
> probably would invent a new concept for this because it is not so obvious.
> b) This will make A* algorithm and monotonicity a bit similar, see A* only
> requires each state to compare with goal state and monotonicity requires each
> two state to compare. Is this a bit too close to invent two concept?
The two concepts are much related. Viewed historically, A* comes first, then
comes monotonicity. The latter is a special case of and implies the former;
while the former is more general than the latter.
Monotonicy is nothing but a cheap toy played by its creators and some writers
like Luger.
By the way, the summation procedure is kind of a show-off, I think.
> c) The line you said you don't follow is like this: if the "cost" in
> monotonicity is referring to cost of minimal path, then the proof is quite
> simple. Even simpler than what is showed in text on page 142. You see, you
> only need to prove "for all states n, if h(n)-h(goal)<=cost(n, goal), then
> it is A* algorithm." (Please check definition of A* algorithm)
Yes, I believe this line of reasoning is acceptable (because monotonicty means
'everywhere locally admissible') .
>However, by
> definition of monotone, h(goal) is 0. So, this is always true which means we
> already proves monotone is A* algorithm. But this seems too easy and we even
> don't need the summation procedure.
No summuation procedure is really needed in order to prove that monotonicity
implies A*. Since Luger sticks to the 'local admisibility' for the concept of
monotonicity, so a summation procedure would make 'locality' more clear to
readers.
> 2. A* and monotone can be drawn as graph like this:
> (evaluation function f=h(n)+g(n)
> | -------------| both A* and
> monotone converge at goal state
> | ----------- ------ |
> A* |------- ----------- |
> | ------ |
> mono |------ |
> | |
> |________________________|_________ (state space n)
> (start state) (goal state)
> If the y-axis is f=g(n)+h(n) and x-axis is state space n, then both curve of
> A* and monotone is non-decreasing(This can be proved easily.) and they both
> converge at goal state because in case of A* f(goal)=h(goal)+g(goal) where
> h(goal)=0 since the minimal path from goal to goal is 0 and h(goal)<=0, and
> in case of monotone, f(goal)=h(goal)+g(goal) where h(goal)=0 by definition.
> So the two line converge at coordinate of (goal, g(goal)).
> However, the starting point may not be same because g(start) are always 0,
> and h(start) in case of A* is different from h(start) in monotone.
> I have a feeling that we might be able to prove by contradiction that the two
> curve is coincided even at start point, but I tried and failed, maybe you can
> do that.
I don't think I could do that.
By the way, I am interested in finding a monotonicity function for exercise 2
on page 156(Version IV). If you know that, or you know someone know that,
please let me know that answer. I will be very much interested in that.
>
> 3. Nice to discuss with you.
Best wishes, and have a nice day.
Camera: It is essential to have a flexible and realistic control of flight in a shooting game. Otherwise player might be unable to detect those fast-moving targets. We supply third-person-view camera apart from first-person-view camera in order to help player re-locate from lost in flight and easily detect moving targets because without much sense of coordinate pilot can be easily lose sense of location. As the camera is closely connected with flight control, the algorithm will be introduced as following.
Flight Control: We supply six degrees freedom of flight control. That is forward/backward with respect of current heading of chopper, left/right perpendicular to current heading of chopper, upward/downward perpendicular to current heading of chopper, yaw, pitch, roll. Therefore player can move in any arbitrary position and posture.
Design Approach: At beginning, I want to use similar idea of OpenGL function "gluLookAt" which use two vector plus one coordinate to represent both position and posture of chopper. However, this proves to be a bad choice because of two disadvantages:
a) You cannot take advantage of rotating functions in OpenGL and you have to calculate your own transformation matrix. By solving the cross product and dot product of vectors, I need to solve a linear system and at some boundary cases I need to consider the case of divided-by-zero situations. And it is quite a computation intensive approach for programmer. (Even though these calculation cannot be avoided in any approach, but it can be done by OpenGL and possibly be optimized. )
b) Another disadvantage is that trigonometry function is not linear. Therefore by using vector representation I cannot interpolate the transition by linearly modify vectors unless vector is transformed back to angles. The immediate result is loss of smoothness in flight control. This is why I return to current design which uses angles plus coordinate.
Implementation: I define a Movement structure which contains current coordinate of chopper plus angles of yaw, pitch and roll of chopper from original posture. However, in first-person-view camera it is not simply three rotations because the previous two rotations will have some effects on the third rotation. It is like this:
GLfloat LookAt_x=current_coord.x+ sin(yaw)*cos(pitch);
GLfloat LookAt_y= current_coord.y+sin(pitch)*cos(roll);
GLfloat LookAt_z= current_coord.z+cos(yaw)*cos(pitch);
In the assignment, I didn't solve this problem and I feel happy that I solve it in my project. This is one thing that I learned in this project.
Flight Control Implementation: Flight control becomes much easier after I choose the correct representation of position and posture of chopper because the calculations are all similar and I can use the same function for other repeatedly. For example, I define a function "calcCoord" which calculates the relative coordinate offset with respect to current position of chopper when chopper moves a distance d in forward direction. It is like this:
x_offset=d*cos(pitch)*sin(yaw);
y_offset=d*sin(pitch)*cos(roll);
z_offset=d*cos(pitch)*cos(yaw);
Then all other calculations will be done by simply change the passing parameter.
backward: change distance d to -d
left/right: change yaw to yaw+90, yaw-90 respectively
up/down: change pitch to pitch+90, pitch-90 respectively
yaw/pitch/roll: just modify each respectively without calculation
And even the "head light" is also calculate by this manner.
The gun fire simulation contains three algorithms. They are rocket flight tracking, target tracking, collision detection, explosion simulation algorithms.
Rocket Flight Tracking: The rocket flight is exactly same as chopper flight control system except that each rocket must maintain its own starting data for position, posture and moment. Then these data will be updated whenever display callback is executed.
a) position: The position will be exact the position of chopper when the rocket is fired.
b) posture: Since we allow player to shoot at arbitrary angle by clicking mouse in first-person-view window, the starting posture of rocket will be slightly different from chopper when fired. By calculating the coordinate of mouse click, we can figure out the relative offset of mouse pointer against center of first-person-view which is regarded as current heading of chopper. Even though we understand it is not linear relationship between the offset of coordinate and current yaw, pitch and roll of chopper, user still can get a realistic vision because we only need an initial shooting direction for each rocket. The calculation of initial direction of rocket is like this:
angle_offset_yaw = horizontal_offset/ half_width_window * horizontal_view_angle;
angle_offset_pitch = vertical__offset / half_height_window * vertical_view_angle;
The vertical _view_angle is chosen as perspective view_angle in perspective view function. And
horizontal_view_angle = vertical_view_angle * (height_window/ width_window);
c) moment: It is the timing data acquired in environment by function "GetClickCount".
Then the rocket flight is exactly like the flight of chopper.
Target Tracking: In a real 3D shooting game, the target tracking would be very complicated since a possible AI might be involved. In our project, we choose a simple solution that all targets only move in a constant speed at a constant direction. Therefore to track all positions of targets, we can iterate all target initial position by adding an offset of elapsed_time*moving_speed to the direction of movement.
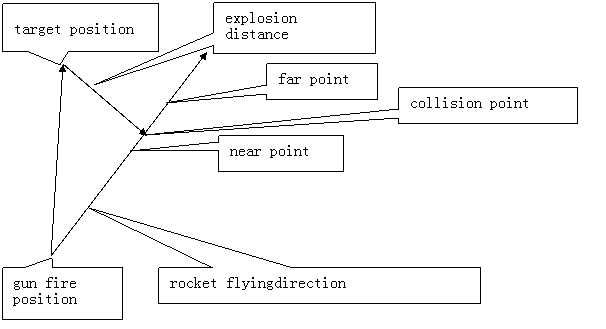
Collision Detection: Please see the following graph.
Figure 10 Collision detection: The arrow represents vector of direction of rocket flying and the direction from firing position to target.
a) Design Approach: A naive collision detection algorithm is simply calculate the immediate distance between each pair of flying rocket and target. However, the display callback function is executed in a discrete manner so that it is possible that display callback is called at moment when rocket is at position "near point" and "far point". At both position, the distance between rocket and target might be bigger than a pre-defined "explosion distance". But obviously the rocket can hit target between these two points. So, this naive algorithm won't work properly.
b) Implementation Details:
At any moment for any flying rocket with respect to any target, the collision detection algorithms all the same. We need to calculate the collision point and then compare the current position of rocket with it. If we take into consideration of movement of direction of target, the calculation is quite complicated. Therefore, I deliberately make the movement speed of target very small compared with moving speed of rocket so that we can ignore the factor of moving direction of target. However, still we consider the changing position of target at any moment.
The collision happens only when these two conditions are satisfied:
i) At some future moment, the shortest distance between target position to the line of rocket flying is smaller than "explosion distance". (Here as I mentioned above, we assume the target is moving at a very slow speed and we assume between every two consecutive two display callback is called, we won't take direction of target into consideration. )
ii) The current position of flying rocket is equal to or exceeding this collision point.
The algorithm uses dot product to calculate the angle t between vector v1 representing rocket flying direction and vector v2 representing gun firing position to current target position. Therefore the distance d between firing position and collision point is:
d= dot(v1,v2); // v1 must be normalized first.
Then by checking the current flying time, we can know if rocket is equal to or exceeding the explosion point.
Explosion Simulation Algorithms: The explosion is always assumed to happen at the moment when rocket hits the target and at the position where the target is at that moment.
i) Flight Algorithms: Basically explosion is similar to rocket flying that as long as you set up the initial flying data. Every time when display callback is executed, the only thing you need to do is just updating the position.
ii) Initializing Flying Data: For a simple solution, I just use the position of target at the moment of explosion and randomly choosing the yaw, pitch and roll for each fragment of explosion.
iii) Fragments Representation: For a simple solution, I just use random sized, colored cube to represent each fragment as we have some problems in importing objects from Maya.
Design Approach: Originally I write a rather complicated library to encapsulate all OpenGL transformation. The idea is quite straight forward. I view all transformation in changing properties of one object in following ways: position, color, containing volume size, axis-direction. Therefore, programmer only needs to setup all parameters for each object and all transformation code will be done by library. For example, we set a sphere at position of coord(x,y,z), color(r,g,b), volume(w,h,l), direction(vx, vy, vz). Then my library will do the series transformations of rotating to align axis to coincide to direction(vx,vy,vz), set color to color(r,g,b), translate to coord(x,y,z), scale to volume(w,h,l). And all high-level objects can be done universally in this manner. The programmer only need to implement a virtual drawing function of derived class. In the case of sphere, the drawing function is simply "glutSolidSphere". By this design, we can even use "script file" to design program since each object is determined by these parameters and programmer can concentrate on high-level logic design with worrying about OpenGL transformation code which are repeated zillions of times. However, at the later stage of this course, more and more OpenGL features are introduced such as lighting, texture, blending etc. I have to again and again expand my original design of framework and at some points some weird phenomenon are detected, like OpenGL fails to detect depth of objects etc. And I don't have enough time for this project. So, this approach is abandoned later. This is one of my biggest regrets in this course apart from that I should spend more time in some advanced OpenGL techniques.
CheckPointing vs. message-logging and failure vs recovery
(The big truth that I learned)
Hey buddy, can you write down what you learned about recovery in most concise way?
Sure.
1. The biggest mistake is to mingle data consistency with inter-process consistency. The best way is just to put data consistency away for
the moment.
2. If there is no "inconsistent cut" situation, each process can recover from wherever it likes.
3. Checkpointing and message-logging are different completely different approaches and should be treated in separate cases. Checkpointing is
more intuitive and it simply "snapshots" current states and later when failure occurs you can restore from this checkpoint. And from checkpoint
to the moment of failure may not be "replayed" exactly if system is non-deterministic which is almost always the case in real world.
4. Message-logging approach assumes that each non-deterministic event can be identified and recorded and replayed during recovery so that after
failure by replaying this non-deterministic events the system recover to the point just before failure. There are many implementation issues and
assumptions of log storage.
5. Checkpointing recovery basically can be independent as long as there is no inconsistent message exchange or in professional term, there is
no orphan process such that it receives a message from failed process which fails to remember this message before failure occurs. Therefore
after recovery of failed process it will have no sense of that sent message while other process does receive the message. In such case, this
recovery is inconsistent which means the selected checkpoint is not appropriate and further rollback is needed. This is called domino effect.
6. Another way to avoid domino effect is coordinated rollback which relies on global checkpointing so that such global checkpoint guarantees
no inconsistent cut. When failure occurs, all processes roll back from this global checkpoint and eliminate possible domino effect with price
of all processes are affected by single process failure because domino effect is not always possible to happen.
7. There are basically pessimistic and optimistic logging scheme in message logging approach. Pessimistic assumes failure is a frequent event
and always precaution in advance such that all outgoing messages are always recorded before send-out. So, after failure by replaying message
log, all messages are guaranteed to be resent to other processes and no orphan process is possible after recovery. (maybe transiant after failure
before recovery is finished.)
8. Optimistic approach assumes failure is far and few. Therefore by only analysis possible lost message after failure running performance is
put on priority. The detailed algorithm is not read by me yet.
9. That is all I learned in these two days. And the last thing is that inter-process consistency must also be synchronized with data consistency
in the sense that data update operation in database is also possible lost when failure occurs. A local database log must also be maintained
independently or combined with message log. Maybe independent log is better since recovery is using different algorithm for these two issue.
The Virtual Synchrony
The textbook is ,just as professor mentioned in first lecture, crispy and concise. (I forget the word he used.)
1. It mentioned in textbook that every query can be sent to different member of the group by a simple method, say according its rank in the
group. However, if you regard that this is done directly by client program, you are in a trap as I am. It is done by a kind of "load balancing
manager" or "wrapper" or whatever you call it because usually the replication of server and service is transparent to client program. For
example, in CORBA one service is mapped to exactly one registry name even though there are replication of service running behind scene. The
client will always direct its request to exactly one server or agent of server group.
2. Then can you give an exact picture about how virtual synchrony is running?
Yes, let me try.
a) In virtual synchrony, the simplest model is that there is exact single update initiator. Here please note that I create the word "update
initiator" and don't be misled by the word "single". Actually all updates should be applied to every replica so that they keep in a synchronized
state. Then why do we use word "single"? The word "single" here simply means single multicast sender so that causal order of update can be
easily achieved by "fbcast" or "FIFO" order from this single sender. As for all other kinds of queries which don't change state of server,
we don't need multicast the query to each member of group. Instead if we ignore Byzantine error, we can trust single reply from any of replica
by sending the query to it.
b) In virtual synchrony, all updates are done in causal order and all "read" requests are actually in asynchronous mode which means that two
read requests may be directed to two replica running concurrently. And this can achieve highest performance.
c) How to achieve mutual exclusion for conflicted updates?
It will use lock to ensure mutual exclusion. Whenever there is an update, the sender can issue a lock request to all replica and wait for
confirmation reply. After receiving grant for lock request from each replica, sender can issue update request to all replica. The simple
algorithm for lock can be as simple as that the exclusive lock will only be granted when there is no either non-exclusive lock or other exclusive
lock. This is very easy thing in any book about file lock.
d) Can we say update is in lock step mode in virtual synchrony?
Not exactly. In fact, we don't have to wait for all replies from all replica for update. Therefore it is faster than lock step. However, each
replica is updating in exact sequence for all updates. i.e. If there are a series of queries and all the write queries will be executed in
identical sequence in each replica. As for read queries, probably each of them is executed only in one replica. So, in this sense, virtual
synchrony is like lock step in which all replica maintain synchronized state for every moment.
3. How about Byzantine error?
If we want to cope with Byzantine error, we simply increase the number of replies of both read and write queries to t+1 before replying to
client where the total number of replica is 3t+1. Therefore the potential performance gain in virtual synchrony might be lost here because
we probably need to multicast even read requests and wait for more than one reply from replica.
4. How about GMS implementation?
Actually this is not an appropriate question for virtual synchrony since dynamic group view is not only for virtual synchrony. Generally
speaking, cbcast with dynamic group view algorithm can be implemented by vector time in the sense that whenever a failed process is noted
by monitor, a flush operation will be executed to ensure all ongoing message be delivered before new group view is sent to each live process.
However, it is possible that the failed process may fail during multicast. Therefore it is possible that only some of members of group will
receive the last message from failed process. Depending on whether we want to implement "dynamic uniformity" or not, we can either ask all
receivers of these message to resend it or not.
virtual synchrony revisited
After I write down the above, I begin to suspect what I learned from professor. In the slides he presented in class, it seems that virtual
synchrony doesn't require a single multicast sender. In fact, update requests can be sent from any process as long as the "conflicting
update" requests are executed in identical order in all members of replica. It can be done!
Suppose a wrapper or a load balancing manager receives all requests from client. This is indeed the situation in CORBA when you register a
group of replica under a single registry name. This manager program maintains a group view and it can also act as GMS manager. So, in current
group, we have n replica's. The manager receives a request from client and send it to any one of replica according to its rank disregarding
whether it is read request or write request. Here we can apply our load balancing algorithm.
When replica receives a request, it treats the request differently depending on whether it is read or write request. If it is read request, it
simply get its local result and return to sender. (If you want to dig deeper, you may need to apply reading lock to local database first.)
If it is write request, the process may need to issue a lock request in "causal order" by multicast with vector time in message. Until it
receives reply of granting lock from each members of group, it will send out its write request to all by simply fbcast because under protection
of lock, we actually maintain the order of any conflicting updates. Therefore cbcast is no longer needed.
The Connectivity in a Random Graph
This is inspired by a public lecture given by Dr. Hopcroft who was awarded with Turing Reward. And the following is just some wild imagination
from myself.
1. Assume at beginning you only have N number of isolated vertices. Then you begin to randomly pick up pairs of vertices to add an edge between
them. If any two vertices are connected, then the "shortest distance" between them is the number of edges connecting with them in shortest path
between them.( This is a rather clumsy definition. I can simply say the length of shortest path between them. )
2. Assume you pick up vertex with equal chance, how does the number of connected vertices increase?
Let's assume before you pick the first vertex the number of connected vertices is C and the number of total vertices is N. Then the number of
isolated vertices is N-C. The chance to pick up a connected vertex is C/N and the chance to pick up an isolated vertex is (N-C)/N. When you are
going to pick up the second vertex, there is a small chance that you may pick up the exact first vertex. But it won't increase any connectivity.
Therefore, the number of connected vertices becomes
C'= (C + 2)*(N-C)/N *(N-C-1)/N + (C+1)*C/N*(N-C)/N + C*C/N*(C-1)/N + C*1/N
= ( C^3 + (2-N)*C^2 + (N^2 -3N+1)*C -2N ) / N^2
a) Please note that the first term is the case when we pick up two distinct vertices in isolated vertices. The second term is the case when we
pick up one connected vertex and one isolated vertex. The third term is when we pick up two connected vertices. The fourth term is when we pick
up the same vertex as what we pick up in first time.
b) This is a recursive formula and N can be viewed as a constant in a stable system. This implies the connected vertices increase roughly in
cubic power.
c) Also please note that the chances of the four cases in a) are also changing with C. That is to say, the more connected the graph is, the big
chance you will pick up
3. Another simple question is what is the effect when we add an edge into this graph. Does it create any shortcut in system?
a) If one of vertex we pick up is originally isolated vertex, then at least we create a new connection which reduce the distance between these
two vertices from infinity to one.
b) If we pick up two connected vertices, then it is hard to say the edge will create a shortcut. Then how can we know about this?
Assume These two distinctive connected vertices we pick up are a and b. Then let's see what is effect of this edge for any other connected
vertex x. Assume the shortest distances from x to a , b are d1 and d2 respectively, then there are three cases to consider. Obviously the
newly-added edge might change the d1 and d2.
i) If d1==d2 then the shortest distance from x to a or b won't change because d1 + 1 >d1.
ii) If d1==d2+1 then still the shortest distance is not affected because d1+1=d2. Also please note that the case d1+1==d2 is similar.
iii) If d1>d2+1 then we have created a new shortcut, namely d2+1.
iv) In other words, the newly-added edge will force the difference of shortest distance of any vertex to these two newly-connected vertices to
at most one. This sounds like a theorem, but I doubt it has any usefulness. (However, it rings some bell about AVL tree. Maybe it can be used
in such remote-connected issue.)
4. The more interesting question is which vertices are affected with changed shortest distance when we add a new edge. I think there are
countless people are interested to know. For example, in your search engine database when a new link is added what do you need to change for
the rest of data?
the "varying" is not what I expected, but it maybe what you understand
<<<<<<<<here goes
I don't quite understand how the sample program calculate the "reflected
image" because the code transform the "normal" by "gl_Normal" which is
transpose of inverse of "gl_ModelViewMatrix". And of course they use
"gl_ModelViewMatrix" to transform vertex. (See example "polkadot3d") I think
we should use "gl_ModelViewMatrix" for transformation for both vertex and
normal.
And when I did such experiment, it looks exactly same! Why is that?
See the attachment of my experiment. I changed the transformation in "vert"
part.
Enclosed the shading program:
//vertex shader
// This is the Vertex Shader for three dimensional polka dots.
//
// author(s): Joshua Doss
//
// Copyright (C) 2002-2006 3Dlabs Inc. Ltd.
//Create uniform variables for lighting to allow user interaction
uniform float SpecularContribution;
uniform vec3 LightPosition;
uniform float MaxCounter;
varying vec3 MCPosition;
varying float LightIntensity;
varying float counter;
void main(void)
{
float diffusecontribution = 1.0 - SpecularContribution;
// compute the vertex position in eye coordinates
vec3 ecPosition = vec3(gl_ModelViewMatrix * gl_Vertex);
//////////////////////////////////////////////////////////////////////////
//This is where I don't understand: why do we use "gl_NormalMatrix" which is the
//transpose of inverse of "gl_ModelViewMatrix" instead "gl_ModelViewMatrix" itself?
// compute the transformed normal
//vec3 tnorm = normalize(gl_NormalMatrix * gl_Normal);
///////////////////////////////////////////////////////////////////////////////
//And following is what experiment I do for using "gl_ModelViewMatrix"
//here because the compiler seems to not support "mat3(ma4)" constructor,
//I have to split the mat4 into three vec3 and construct mat3.
vec3 v0=vec3(gl_ModelViewMatrix[0]);
vec3 v1=vec3(gl_ModelViewMatrix[1]);
vec3 v2=vec3(gl_ModelViewMatrix[2]);
mat3 myMatrix=mat3(v0, v1, v2);
vec3 tnorm = vec3(myMatrix * gl_Normal);
tnorm=normalize(tnorm);
//////////////////////////////////////////////////////////////////
//now tnorm is actually norm after gl_ModelViewMatrix transformation
//and amazingly the effect is all the same.
//////////////////////////////////////////////////////////////////
// compute a vector from the model to the light position
vec3 lightVec = normalize(LightPosition - ecPosition);
// compute the reflection vector
vec3 reflectVec = reflect(-lightVec, tnorm);
// compute a unit vector in direction of viewing position
vec3 viewVec = normalize(-ecPosition);
// calculate amount of diffuse light based on normal and light angle
float diffuse = max(dot(lightVec, tnorm), 0.0);
float spec = 0.0;
// if there is diffuse lighting, calculate specular
if(diffuse > 0.0)
{
spec = max(dot(reflectVec, viewVec), 0.0);
spec = pow(spec, 16.0);
}
// add up the light sources, since this is a varying (global) it will pass to frag shader
LightIntensity = diffusecontribution * diffuse * 1.5 + SpecularContribution * spec;
//LightIntensity = 0.56;
counter=counter+1.0;
if (counter>(MaxCounter-1.0))
{
counter=1.0;
}
// the varying variable MCPosition will be used by the fragment shader to determine where
// in model space the current pixel is
//counter=counter+1;
MCPosition = vec3 (gl_Vertex);
// send vertex information
gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
}
//fragment shader
//
// Fragment shader for 3 dimensional polka dot shader.
//
// Author: Joshua Doss
//
// Copyright (C) 2002-2006 3Dlabs Inc. Ltd.
//
// See 3Dlabs-License.txt for license information
//
varying float LightIntensity;
varying vec3 MCPosition;
varying float counter;
//Create uniform variables so dots can be spaced and scaled by user
uniform vec3 Spacing;
//uniform float DotSize;
uniform float MaxCounter;
//Create colors as uniform variables so they can be easily changed
uniform vec3 ModelColor, PolkaDotColor;
void main(void)
{
float insidesphere, sphereradius, scaledpointlength;
vec3 scaledpoint, finalcolor;
// Scale the coordinate system
// The following line of code is not yet implemented in current drivers:
// mcpos = mod(Spacing, MCposition);
// We will use a workaround found below for now
/////////////////////////////////////////////////////////
//scaledpoint = MCPosition - (Spacing * floor(MCPosition/Spacing));
// Bring the scaledpoint vector into the center of the scaled coordinate system
//scaledpoint = scaledpoint - Spacing/2.0;
/////////////////////////////////////////////////////////
// Find the length of the scaledpoint vector and compare it to the dotsize
//scaledpointlength = length(scaledpoint);
//counter = counter+1;
//insidesphere = step(scaledpointlength,DotSize);
if (counter> 0.0)
insidesphere=0.0;
else
insidesphere=1.0;
//insidesphere=counter/MaxCounter;
//insidesphere=0.5;
//LightIntensity =0.1;
//myVar=1.0;
// Determine final output color before lighting
finalcolor = vec3(mix(ModelColor, PolkaDotColor, insidesphere));
// Output final color and factor in lighting
gl_FragColor = clamp(vec4(finalcolor * LightIntensity, 1.0), 0.0, 1.0);
}
>>>>>>>>Here comes...
correct transformation for normals is transpose of inverse of
gl_modelviewmatrix.
checkout appendix of OpenGL red book for explanation.
maybe there is no scaling in your experiment. so effects might look same.
i should be back in lab on monday.
i don't have access to various versions of visual studio in my home. so
cannot answer those questions. the code given should run fine with vs7
and vs7.1
a varying variable is something which you calculate in vertex shader and
wants interpolated results in fragment shader.
consider triangle: there are 3 vertices: so 3 times vertex shader is
called. fragment shader is called many times depending on pixels in
triangle and each pixel calculations is done by fragment shader which
might need interpolated results from 3 vertices.
fragment shader operates on pixel only after results from all vertices
of triangle (or other primitive) is available.
you cannot use constant instead of varying because interpolation is
different for different pixels of triangle. varying automatically takes
care of this.
<<<<<<<<<<<<<<<<Here goes
Thank you for your explanation. However, still I don't get how interpolation
in fragment can be possible with "varying" variables which vertex program
assigns values for each vertex. There must be some misunderstanding in my
view of pipeline and shading language. So, the following is my understanding
and please verify for me.
1. All vertex, primitives, pixels operations are done in pipeline,
stream-line manner which means they are more or less in parallel:
Vertex-Transformation-pipeline: vert[0], vert[1],vert[2]...vert[n]
triangle-assembly-pipeline: tri[0],tri[1]...tri[m]
rasterization-pipeline: pixel[0], pixel[1], pixel[2]...pixel[p]
Assuming the operation orders are optimized such that vert[0],vert[1],
vert[2] corresponds tri[0] so that triangle-assembly-pipeline doesn't have
to wait. So does for rasterization pipeline or scan-conversion.
Then as you said the same vertex program will be executed by three vertices,
namely vert[0], vert[1], vert[2], and multiple fragments or pixels will be
scan-converted. And the scan convertion cannot start until all vertices of
triangle are available. Thus the "varying" variable can only store the
assignment done by the last vertex or vert[2] in this case. So, how can
multiple pixels or fragments interpolate by using the same "varying"
variable which is shared by three vertices?
2. A second guess occurs to me. Is it true that those interpolation will be
done "automatically" by fragment shader itself if we define those
"interpolating functions", like "step", "mix"?
i.e. If I call step(edge, value) then shader itself will do internally to
interpolate the "value" among all fragments? This is a bit crazy and I just
don't believe it.
>>>>>>>>>>>>>>>>here comes..
Maybe similarity between C++ and OpenGL shading language is causing
confusion. Many keywords such as varying may have expanded or different
meaning than that in C++.
varying (in OpenGL 2, not in C++) means interpolation will be done
automatically by hardware between values of vertices.
this (varying) variable value will be automatically different for
different fragments, as per calculation by hardware.
I already explained this in my previous explanation.
It has nothing to do with functions such as step etc.
This interpolated value is necessary for effects such as per pixel
lighting where we need interpolated normals etc.
Just like color was automatically interpolated (in smooth shading) for
fragment color in previous versions of OpenGL (say OpenGL 1.2), so does
varying variables in shading language.
<<<<<<<<<<<<<<<<here goes...
Thank you for your explanation. Maybe I should ask a more specific question
like this. The following is a simple shading program.
vertex program:
varying vec4 myposition;
void main(void)
{
myposition=gl_Vertex;
gl_Position=gl_ModelViewProjectionMatrix * gl_Vertex ;
}
fragment program:
varying vec4 myposition;
void main()
{
gl_FragColor = myposition;
}
Suppose we have a model of one big triangle vert1, vert2, vert3 and how does
hardware interpolate values in between different pixels?
Or more specifically after running three times of vertex program what
happens with "varying" variable myposition? And for all n pixels what value
would each pixel pick up?
<<<<<<<<<here goes...
Sorry again.Just after sending out the previous question I think I might
understand what you mean.
When doing scan conversion, for all those "varying" variables between three
vertices of one triangle, the hardware will do linear interpolation. So,
taking the example given in my previous mail, suppose the triangle finally
is transformed to be display coordinate of v1(0,0) v2(10,10) v3(20,5). Then
v1 between v2 there are 10 rows and varying "mcpostion" will be linearly
interpolated by 10. Similarly between v1 and v3, there are there are 5 rows,
the "mcposition" will be linearly interpolated by 5. And within each
scanning line, the "mcposition" will also be linearly interpolated
"horizontally". In case of segment pass v2, there will be 10 column and the
scan line will linearly interpolate "mcposition" by 10.
>>>>>>>>>>>here comes...
yes. interpolation between vertices occur. though formula is more
complicated. see OpenGL specification for exact interpolation formula.
Sometimes my brain is as sticky as glue...
The following code is describing the algorithm of LZW compression.
set w = NIL
loop
read a character K
if wK exists in the dictionary
w = wK
else
output the code for w
add wK to the string table
w = K
endloop
I like to interpret it as an algorithm of "discovery" which is so intuitive in one man's vision of procedure of discovering his surrounding
environment. Whenever you see something new, you record it down in your memory in preparation for next "recognition". And whenever you see
something the first thing you are trying is to find it out in your memory if you saw that before. So, if this is the way of establishing of
knowledge, then what is advantage of this architecture of information? In other words, what is "good" of doing this? One obvious answer is
to make optimum usage of memory so that we can memorize more.
Finally I give up because I don't understand the significance of my way.
#include <set>
#include <cstdio>
#include <deque>
using namespace std;
struct Code
{
char* code;
int index;
static int counter;
void display();
};
int Code::counter=0;
struct CodeComp
{
bool operator()(const Code& first, const Code& second)
{
return strcmp(first.code, second.code)<0;
}
bool operator()(const Code& first, const Code& second) const
{
return strcmp(first.code, second.code)<0;
}
};
typedef set<Code, CodeComp> CodeSet;
typedef deque<Code> CodeQueue;
class Dictionary
{
private:
CodeSet codeSet;
Code dummy;
CodeQueue codeQueue;
CodeSet::iterator it;
public:
void readFile(char* fileName);
void readString(char* sentence);
void printCode();
void printQueue();
};
int main()
{
Dictionary dictionary;
dictionary.readString("\\WED\\WE\\WEE\\WEB");
dictionary.printCode();
dictionary.printQueue();
return 0;
}
void Dictionary::printQueue()
{
printf("the code queue is:\n");
for (int i=0; i<codeQueue.size(); i++)
{
codeQueue[i].display();
}
}
void Code::display()
{
printf("[index=%d;code=%s]\n", index, code);
}
void Dictionary::printCode()
{
printf("the code table is:\n");
for (it=codeSet.begin(); it!=codeSet.end(); it++)
{
it->display();
}
}
void Dictionary::readString(char* sentence)
{
int len=strlen(sentence);
int tempLen, i, j;
Code result;
char* buf=new char[len+1];
char* temp=new char[len+1];
codeQueue.clear();
for (i=0; i<len; i++)
{
buf[i]=sentence[i];
buf[i+1]='\0';
//index=-1;
//printf("now let's see code\n");
//printCode();
//printf("now let's see queue\n");
//printQueue();
result.code=NULL;
for (j=i; j>=0; j--)
{
dummy.code=buf+j;
it=codeSet.find(dummy);
if (it==codeSet.end())
{
tempLen=strlen(buf+j);
dummy.code=new char[tempLen+1];
strncpy(dummy.code, buf+j, tempLen+1);
dummy.index=dummy.counter++;
it=codeSet.insert(dummy).first;
break;
}
else
{
result=*it;
}
}
if (result.code==NULL)
{
result=*it;
}
tempLen=strlen(result.code);
while (!codeQueue.empty())
{
if (tempLen>strlen(codeQueue.back().code))
{
tempLen-=strlen(codeQueue.back().code);
codeQueue.pop_back();
}
else
{
break;
}
}
codeQueue.push_back(result);
}
}
void Dictionary::readFile(char* fileName)
{
}
//The running result is like this:
the code table is:
[index=10;code=B]
[index=2;code=D]
[index=3;code=DW]
[index=1;code=E]
[index=7;code=EE]
[index=8;code=EEW]
[index=9;code=EEWE]
[index=5;code=EW]
[index=6;code=EWE]
[index=0;code=W]
[index=4;code=WE]
the code queue is:
[index=0;code=W]
[index=1;code=E]
[index=2;code=D]
[index=0;code=W]
[index=1;code=E]
[index=4;code=WE]
[index=6;code=EWE]
[index=10;code=B]
Press any key to continue
the simple binary sending...
The title is not exact because I cannot find a proper term to describe it. In cluster the communication is done in parallel for
point-to-point communication. So, when you want all data be sent to one node for processing, it is better to do it in a fashion of binary-
tree-like. The following code is a demo and test for my personal usage. It is a bit improvement compared with my naive implementation last
winter.
#include <stdio.h>
#include <stdlib.h>
struct BinaryDesc
{
int total;
int *array;
int myIndex;
};
int roundCount;
void recvFrom(int me, int from)
{
printf("me%d will receive from %d\n", me, from);
}
void sendTo(int me, int to)
{
printf("me%d will send to %d\n", me, to);
}
void doBinary(const BinaryDesc* desc)
{
int i;
BinaryDesc myDesc;
if (desc->total==1)
{
printf("finished and last one is %d\n", desc->array[0]);
return;
}
else
{
printf("after %d round\n", ++roundCount);
}
if (desc->myIndex%2==0)
{
//i may have to receive
if (desc->myIndex+1<desc->total)
{
recvFrom(desc->array[desc->myIndex], desc->array[desc->myIndex+1]);
}
else
{
printf("me%d is idle in this round\n", desc->array[desc->myIndex]);
}
//in any case I will do this
myDesc.total=(desc->total+1)/2;
myDesc.array=new int[myDesc.total];
for (i=0; i<myDesc.total; i++)
{
myDesc.array[i]=desc->array[2*i];
}
myDesc.myIndex=desc->myIndex/2;
doBinary(&myDesc);
delete[]myDesc.array;
}
else
{
//i always have to send
sendTo(desc->array[desc->myIndex], desc->array[desc->myIndex-1]);
//then I quit;
}
}
int main()
{
BinaryDesc desc;
int i, last=0;
desc.total=12;
desc.array=new int[desc.total];
printf("the array is:\n");
for (i=0; i<desc.total; i++)
{
desc.array[i]=last+rand()%3+1;
last=desc.array[i];
printf("[%d]", desc.array[i]);
}
printf("\nand now let's do one by one\n");
for (i=0; i<desc.total; i++)
{
printf("\n******************\nfor index =%d\n", i);
roundCount=0;
desc.myIndex=i;
doBinary(&desc);
}
delete[]desc.array;
return 0;
}
The running outcome is like this:
the array is:
[3][6][8][10][13][15][16][17][19][22][25][28]
and now let's do one by one
******************
for index =0
after 1 round
me3 will receive from 6
after 2 round
me3 will receive from 8
after 3 round
me3 will receive from 13
after 4 round
me3 will receive from 19
finished and last one is 3
******************
for index =1
after 1 round
me6 will send to 3
******************
for index =2
after 1 round
me8 will receive from 10
after 2 round
me8 will send to 3
******************
for index =3
after 1 round
me10 will send to 8
******************
for index =4
after 1 round
me13 will receive from 15
after 2 round
me13 will receive from 16
after 3 round
me13 will send to 3
******************
for index =5
after 1 round
me15 will send to 13
******************
for index =6
after 1 round
me16 will receive from 17
after 2 round
me16 will send to 13
******************
for index =7
after 1 round
me17 will send to 16
******************
for index =8
after 1 round
me19 will receive from 22
after 2 round
me19 will receive from 25
after 3 round
me19 is idle in this round
after 4 round
me19 will send to 3
******************
for index =9
after 1 round
me22 will send to 19
******************
for index =10
after 1 round
me25 will receive from 28
after 2 round
me25 will send to 19
******************
for index =11
after 1 round
me28 will send to 25
Press any key to continue Do you know or do you not know? "Nick, let me ask you about something!"
"Yes?"
"What is computation?"
"Hmm.... computation is such a procedure that we compute some elements and assemble their results in a certain manner to present."
"What IS computation?"
"Hmm..."
"What EXACTLY are you doing for computation?"
"Hmm... I am trying to sort..."
"Yes!"
"...out...the problem...Am I right?"
"Yes!"
"Is my answer correct about computation?"
"Yes! Oh, no!"
"Yes or no?"
"You are sorting."
"What am I doing?"
"Sorting!"
"Hmm...do you mean all computation is just a kind of sorting?"
"Yes!"
"Hmm...any problem? any algorithm?"
"Yes!"
"Isn't it too generic?"
"Isn't it good?"
"Hmm...it depends, doesn't it?"
"Depends on what?"
"It depends on how you define sorting."
"Sorting is such a procedure that you compare all elements with a specific order and then reassembly data to present it in that order.
Optimization questions usually requires you to give the top element in result like the maximum or minimum one or some of their property like
the size of that element etc. Decision problem simply asks if the element has such a property."
"Hmm..."
"..."
"How do you sort?"
"You compare elements."
"In pairs?"
"That is best you can expect. Most P problems require you to only look into binary relations. In some cases you may need to look into each
triples or more. As long as you don't have to look into n-ary relations it is P problem."
"Is that all?"
"I think so."
"We have n*(n-1) pairs for n elements and do you suggest that for all P problems we can only have O(n*n) algorithm?"
"Certainly not! We are talking about a "total order" here which enjoys transitive law such that (a<b&b<c)=>a<c. And all sorting algorithms
take advantage of this property to save logn from n and that is why the best of sorting algorithm can only do O(nlogn)."
"Saving logn from n? Can you be more specific?"
"No!"
"Why not?"
"Hmm..."
"Do you know or do you not know?"
"Hmm..."
"How about those algorithm such that they only need O(n)?"
"What are these algorithm doing?"
"Hmm..."
"They are searching!"
"Hmm..."
"For searching problem you only need to compare what you have with what you encounter in linear probing."
"Then it is SEARCHING not SORTING, isn't it?"
"It is still sorting, only that your comparison requirement becomes equal or not-equal. Therefore all n element are sorted in two
super-elements. One is equal, the other is not equal."
"Hmm...then how about those algorithms with O(logn)? Are we doing sorting with binary search?"
"This is because you are taking advantage of numbers!"
"Numbers?"
"Yes! What is number?"
"Hmm..."
"Number system can be MAPPED by any other "total order" like an image and we already pre-calculate some properties of number system. By
taking advantage of this, we achieve O(logn)."
"Can you be more specific?"
"What do you know about numbers?"
"Hmm..."
"Do you know the precedence of each number? Then after mapping each element into number which is a special total order, you will take
advantage that you know the precedence of each number and can even random access element like RAM."
"Hmm...can you be more specific?"
"..."
"I am asking a question!"
"Zzzz..."
question:
Given 2n+1 number, all except one are in pairs of same value. e.g. [1,2,4,6,2,1,4] and 3 is your input. 6 is the number you need to find out.
my answer:
void findSingle(int array[], int arraySize)
{
set<int> mySet;
pair<set<int>::iterator, bool> result;
for (int i=0; i<arraySize; i++)
{
result=mySet.insert(array[i]);
if (!result.second)
{
mySet.erase(result.first);
}
}
printf("it is %d\n", *mySet.begin());
}
time complexity:
O(log1+log2 +log3 + ...logn)
There should be a limit for this series, but I don't know.
/////////////////////////////////
The above is a common solution and there is a magic solution. Just "xor" all of them and the remainder is the number. I learn this from my
friend.
////////////////////////////////
question: loop in link list.
How to find loop in link list? I learned this magic algorithm from my friends.
#include <stdio.h>
#include <stdlib.h>
struct Link
{
Link* next;
int rank;
int value;
};
Link* init(int length)
{
Link* result=new Link;
Link* ptr=result;
result->next=NULL;
result->rank=0;
result->value=rand()%1000;
for (int i=0; i<length; i++)
{
ptr->next=new Link;
ptr->next->rank=ptr->rank+1;
ptr->next->next=NULL;
ptr->next->value=rand()%1000;
ptr=ptr->next;
}
return result;
}
void make_loop(Link* root, int crossStep)
{
Link* cross=root;
Link* ptr;
if (root==NULL)
{
printf("empty link list\n");
return;
}
for (int i=0; i<crossStep; i++)
{
cross=cross->next;
if (cross==NULL)
{
printf("link list is not long enough\n");
return;
}
}
ptr=cross;
while (ptr->next!=NULL)
{
ptr=ptr->next;
}
ptr->next=cross;
}
void print_link(Link* root)
{
Link*ptr=root;
printf("begin print link list\n");
while (ptr!=NULL)
{
printf("rank[%d] value[%d]\n", ptr->rank, ptr->value);
ptr=ptr->next;
}
}
bool find_loop(Link* root)
{
Link* fast=root, *slow=root;
bool noLoop=false;
int counter=0;
//check condition if root==NULL
while (slow!=NULL)
{
if (fast->next!=NULL)
{
fast=fast->next;
}
else
{
return false;//no loop;
}
if (fast->next!=NULL)
{
fast=fast->next;
}
else
{
return false;//no loop;
}
if (slow==fast)
{
printf("first counter=%d\n", counter);
return true;
}
if (slow->next!=NULL)
{
slow=slow->next;
if (slow==fast)
{
printf("second counter=%d\n", counter);
return true;
}
}
counter++;
}
return false;
}
int main()
{
Link* root;
root=init(20);
print_link(root);
make_loop(root, 15);
//print_link(root);
if (find_loop(root))
{
printf("there is a loop\n");
}
else
{
printf("there is no loop\n");
}
return 0;
}
question: how to test if a number is power of 2?
I learn this from my friend: !(number & (number-1))
question: how to count how many bits in an integer?
int countBits(unsigned int number)
{
int result=0;
while (number)
{
number=(number-1)&number;
result++;
}
return result;
}
question: how to swap two integer without an extra variable for temporary storage?
void swapInteger(int& x, int& y)
{
x=x^y; //x = x xor y
y=x^y; //y = (x xor y) xor y ==> x
x=x^y; //x = (x xor y) xor x ==> y
}
W gives a even simpler solution!
x=x+y;
y=x-y;
x=x-y;
Remember: The determinant of reflection is -1 and the determinant of rotation is 1.
Here is a little summation of various "type" cast. Please note that complex type should rather not be called type-cast, but instead
type-compatible assignment. You see, it is C++ specification that the derived class type is "compatible" with base class type. There is
actually not "type-conversion", therefore no need for type-cast.
|
|
static_cast
|
dynamic_cast
|
reinterpret_cast
|
const_cast
|
C cast
|
|
Primitive type
|
Y
|
N
|
N
|
N
|
Y
|
|
Primitive pointer
type
|
N
|
N
|
Y
|
Y/N(cannot cast to other
type than itself w/o const)
|
Y
|
|
Complex type (no inheritance)
|
N
|
N
|
N
|
N
|
N
|
|
Complex pointer type (no inheritance)
|
N
|
N
|
Y
|
N
|
Y
|
|
Runtime check
(Complex pointer type)
|
N
|
Y
|
N
|
N
|
N
|
|
Remove const and
volatile for pointer type
|
N
|
N
|
N
|
Y
|
Y
|
What is new?
There are several things I want to make a note.
1. The so-called singleton is made through "hiding" its constructor as "protected" so that no instance can
call its constructor because of access restriction. i.e. A a; Instance "a" is trying to access A::A(); which
is declared as protected.
2. Therefore we hide the constructor, and then we need to give a restricted method to construct an instance
by declaring a method, like "createInstance", to return a new instance. In the case of singleton, we don't
generate more than one instance.
3. In principle, a derived class inherents all protected member and method from its base class by public
inheritance. If the base class declare its constructor as protected, it will be inherited just like anything
else. However, because of syntax a= new A; will automatically call its constructor equivalently like
i) A::operator new(sizeof(A); //if A's operator new is overided, otherwise use "global new operator".
ii)A:A()
And this is treated as if a.A(); Therefore you are NOT able to call this EVEN in an inherited class member
method though as inherited class you inherits all protected member from your base class. This is the reason
why you cannot call base class constructor in inherited class member function.
4. Overriding operator new in a class doesn't change the situation in a=new A; because as soon you type "A"
after "new" you already instruct compiler to call A's constructor after A's "new" operator. So, unless you
change to specifically to a=(A*)A::operator new(sizeof(A)); However, this is more like a meaningless question
because you and I cannot image what is purpose of doing this. Just for hacking code?
5. There is one thing I don't understand at beginning. When I override operator new as following, I always get a warning
from compiler saying that no matching "delete" operator is found and there is possible memory leaking etc. even though
I have already override my delete operator as A::operator delete(void* ptr);
Later I found out that. The thing is that the compiler will try to find a delete operator with exact same parameter as
the override "new operator". i.e. void* A::operator new(size_t size, sometype param); must be matched with
void A::operator delete(void* ptr, sometype param);
And by default new takes size_t as first parameter, delete takes void* as first parameter. From then on, the parameter type
and number must match. This is so-called the matched new-delete.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
class A;
class A
{
protected:
static A* a;
static bool instance();
void func(){printf("I am func of A\n");}
int aInt;
void* operator new(size_t size, char initChar);
void operator delete(void* ptr);
A(){;}
public:
};
void* A::operator new(size_t size, char initChar)
{
if (a!=NULL)
{
a=(A*)malloc(size);
memset(a, size, initChar);
}
return a;
}
void A::operator delete(void* ptr)
{
free(ptr);
ptr=NULL;
}
A* A::a=NULL;
bool A::instance()
{
if (a==NULL)
{
a=(A*)(new(0) A);
}
return true;
}
class B: public A
{
public:
void instance()
{
//this works but we cannot dynamically allocate memory
//as it is only a local temporary variable.
a=&(A::A());
//this works because we just work around with A::A() or A's constructor
//instead we only want to use its "member method".
a=(A*)A::operator new(sizeof(A), 0) ;
A::func();
printf("now I am inside B and access A's member, like its constructor.\n");
//A* ptr=new A;//this will give error
aInt=0;
}
void deInstance()
{
delete a;
}
};
int main()
{
B b;
//A* a=(A*)A::operator new(sizeof(A),0) ;
b.instance();
b.deInstance();
return 0;
}
///////////////////////////////////
md5: repeater
////////////////////////////////////
file: repeater.cpp
#include <stdio.h>
#include "md5.h"
#include <set>
using namespace std;
unsigned char start[16];
struct Digest
{
unsigned char src[16];
unsigned char dest[16];
bool operator==(const Digest& other)
{
return memcmp(dest, other.dest, 16)==0;
}
};
struct DigestComp
{
bool operator()(const Digest& first, const Digest& second)
{
return memcmp(first.dest, second.dest, 16)<0;
}
};
typedef set<Digest, DigestComp> md5Set;
void init(md5Set& mySet, Digest& digest)
{
md5_state_t state;
memset(digest.src, 0, 16);
md5_init(&state);
md5_append(&state, digest.src, 16);
md5_finish(&state, digest.dest);
mySet.insert(digest);
}
void
void repeat()
{
pair<md5Set::iterator, bool> result;
md5Set* pMySet;
Digest start, digest;
int counter=0, i;
md5_state_t state;
pMySet=new md5Set;
init(*pMySet, start);
memcpy(&digest.src, &start.dest, sizeof(Digest));
do
{
md5_init(&state);
md5_append(&state, digest.src, 16);
md5_finish(&state, digest.dest);
result=pMySet->insert(digest);
counter++;
if (counter%1000==0)
{
printf("counter=%d\n", counter);
}
memcpy(digest.src, digest.dest, 16);
}
while (result.second);
printf("found? counter=%d\n", counter);
printf("src[");
for (i=0; i<16; i++)
{
printf("%c", digest.src[i]);
}
printf("]\n");
printf("dest[");
for (i=0; i<16; i++)
{
printf("%c", digest.dest[i]);
}
printf("]\n");
}
int main()
{
repeat();
return 0;
}
file: md5.h
/*
Copyright (C) 1999, 2002 Aladdin Enterprises. All rights reserved.
This software is provided 'as-is', without any express or implied
warranty. In no event will the authors be held liable for any damages
arising from the use of this software.
Permission is granted to anyone to use this software for any purpose,
including commercial applications, and to alter it and redistribute it
freely, subject to the following restrictions:
1. The origin of this software must not be misrepresented; you must not
claim that you wrote the original software. If you use this software
in a product, an acknowledgment in the product documentation would be
appreciated but is not required.
2. Altered source versions must be plainly marked as such, and must not be
misrepresented as being the original software.
3. This notice may not be removed or altered from any source distribution.
L. Peter Deutsch
ghost@aladdin.com
*/
/* $Id: md5.h,v 1.4 2002/04/13 19:20:28 lpd Exp $ */
/*
Independent implementation of MD5 (RFC 1321).
This code implements the MD5 Algorithm defined in RFC 1321, whose
text is available at
http://www.ietf.org/rfc/rfc1321.txt
The code is derived from the text of the RFC, including the test suite
(section A.5) but excluding the rest of Appendix A. It does not include
any code or documentation that is identified in the RFC as being
copyrighted.
The original and principal author of md5.h is L. Peter Deutsch
<ghost@aladdin.com>. Other authors are noted in the change history
that follows (in reverse chronological order):
2002-04-13 lpd Removed support for non-ANSI compilers; removed
references to Ghostscript; clarified derivation from RFC 1321;
now handles byte order either statically or dynamically.
1999-11-04 lpd Edited comments slightly for automatic TOC extraction.
1999-10-18 lpd Fixed typo in header comment (ansi2knr rather than md5);
added conditionalization for C++ compilation from Martin
Purschke <purschke@bnl.gov>.
1999-05-03 lpd Original version.
*/
#ifndef md5_INCLUDED
#define md5_INCLUDED
/*
* This package supports both compile-time and run-time determination of CPU
* byte order. If ARCH_IS_BIG_ENDIAN is defined as 0, the code will be
* compiled to run only on little-endian CPUs; if ARCH_IS_BIG_ENDIAN is
* defined as non-zero, the code will be compiled to run only on big-endian
* CPUs; if ARCH_IS_BIG_ENDIAN is not defined, the code will be compiled to
* run on either big- or little-endian CPUs, but will run slightly less
* efficiently on either one than if ARCH_IS_BIG_ENDIAN is defined.
*/
typedef unsigned char md5_byte_t; /* 8-bit byte */
typedef unsigned int md5_word_t; /* 32-bit word */
/* Define the state of the MD5 Algorithm. */
typedef struct md5_state_s {
md5_word_t count[2]; /* message length in bits, lsw first */
md5_word_t abcd[4]; /* digest buffer */
md5_byte_t buf[64]; /* accumulate block */
} md5_state_t;
#ifdef __cplusplus
extern "C"
{
#endif
/* Initialize the algorithm. */
void md5_init(md5_state_t *pms);
/* Append a string to the message. */
void md5_append(md5_state_t *pms, const md5_byte_t *data, int nbytes);
/* Finish the message and return the digest. */
void md5_finish(md5_state_t *pms, md5_byte_t digest[16]);
#ifdef __cplusplus
} /* end extern "C" */
#endif
#endif /* md5_INCLUDED */
file://md5.cpp
/*
Copyright (C) 1999, 2000, 2002 Aladdin Enterprises. All rights reserved.
This software is provided 'as-is', without any express or implied
warranty. In no event will the authors be held liable for any damages
arising from the use of this software.
Permission is granted to anyone to use this software for any purpose,
including commercial applications, and to alter it and redistribute it
freely, subject to the following restrictions:
1. The origin of this software must not be misrepresented; you must not
claim that you wrote the original software. If you use this software
in a product, an acknowledgment in the product documentation would be
appreciated but is not required.
2. Altered source versions must be plainly marked as such, and must not be
misrepresented as being the original software.
3. This notice may not be removed or altered from any source distribution.
L. Peter Deutsch
ghost@aladdin.com
*/
/* $Id: md5.c,v 1.6 2002/04/13 19:20:28 lpd Exp $ */
/*
Independent implementation of MD5 (RFC 1321).
This code implements the MD5 Algorithm defined in RFC 1321, whose
text is available at
http://www.ietf.org/rfc/rfc1321.txt
The code is derived from the text of the RFC, including the test suite
(section A.5) but excluding the rest of Appendix A. It does not include
any code or documentation that is identified in the RFC as being
copyrighted.
The original and principal author of md5.c is L. Peter Deutsch
<ghost@aladdin.com>. Other authors are noted in the change history
that follows (in reverse chronological order):
2002-04-13 lpd Clarified derivation from RFC 1321; now handles byte order
either statically or dynamically; added missing #include <string.h>
in library.
2002-03-11 lpd Corrected argument list for main(), and added int return
type, in test program and T value program.
2002-02-21 lpd Added missing #include <stdio.h> in test program.
2000-07-03 lpd Patched to eliminate warnings about "constant is
unsigned in ANSI C, signed in traditional"; made test program
self-checking.
1999-11-04 lpd Edited comments slightly for automatic TOC extraction.
1999-10-18 lpd Fixed typo in header comment (ansi2knr rather than md5).
1999-05-03 lpd Original version.
*/
#include "md5.h"
#include <string.h>
#undef BYTE_ORDER /* 1 = big-endian, -1 = little-endian, 0 = unknown */
#ifdef ARCH_IS_BIG_ENDIAN
# define BYTE_ORDER (ARCH_IS_BIG_ENDIAN ? 1 : -1)
#else
# define BYTE_ORDER 0
#endif
#define T_MASK ((md5_word_t)~0)
#define T1 /* 0xd76aa478 */ (T_MASK ^ 0x28955b87)
#define T2 /* 0xe8c7b756 */ (T_MASK ^ 0x173848a9)
#define T3 0x242070db
#define T4 /* 0xc1bdceee */ (T_MASK ^ 0x3e423111)
#define T5 /* 0xf57c0faf */ (T_MASK ^ 0x0a83f050)
#define T6 0x4787c62a
#define T7 /* 0xa8304613 */ (T_MASK ^ 0x57cfb9ec)
#define T8 /* 0xfd469501 */ (T_MASK ^ 0x02b96afe)
#define T9 0x698098d8
#define T10 /* 0x8b44f7af */ (T_MASK ^ 0x74bb0850)
#define T11 /* 0xffff5bb1 */ (T_MASK ^ 0x0000a44e)
#define T12 /* 0x895cd7be */ (T_MASK ^ 0x76a32841)
#define T13 0x6b901122
#define T14 /* 0xfd987193 */ (T_MASK ^ 0x02678e6c)
#define T15 /* 0xa679438e */ (T_MASK ^ 0x5986bc71)
#define T16 0x49b40821
#define T17 /* 0xf61e2562 */ (T_MASK ^ 0x09e1da9d)
#define T18 /* 0xc040b340 */ (T_MASK ^ 0x3fbf4cbf)
#define T19 0x265e5a51
#define T20 /* 0xe9b6c7aa */ (T_MASK ^ 0x16493855)
#define T21 /* 0xd62f105d */ (T_MASK ^ 0x29d0efa2)
#define T22 0x02441453
#define T23 /* 0xd8a1e681 */ (T_MASK ^ 0x275e197e)
#define T24 /* 0xe7d3fbc8 */ (T_MASK ^ 0x182c0437)
#define T25 0x21e1cde6
#define T26 /* 0xc33707d6 */ (T_MASK ^ 0x3cc8f829)
#define T27 /* 0xf4d50d87 */ (T_MASK ^ 0x0b2af278)
#define T28 0x455a14ed
#define T29 /* 0xa9e3e905 */ (T_MASK ^ 0x561c16fa)
#define T30 /* 0xfcefa3f8 */ (T_MASK ^ 0x03105c07)
#define T31 0x676f02d9
#define T32 /* 0x8d2a4c8a */ (T_MASK ^ 0x72d5b375)
#define T33 /* 0xfffa3942 */ (T_MASK ^ 0x0005c6bd)
#define T34 /* 0x8771f681 */ (T_MASK ^ 0x788e097e)
#define T35 0x6d9d6122
#define T36 /* 0xfde5380c */ (T_MASK ^ 0x021ac7f3)
#define T37 /* 0xa4beea44 */ (T_MASK ^ 0x5b4115bb)
#define T38 0x4bdecfa9
#define T39 /* 0xf6bb4b60 */ (T_MASK ^ 0x0944b49f)
#define T40 /* 0xbebfbc70 */ (T_MASK ^ 0x4140438f)
#define T41 0x289b7ec6
#define T42 /* 0xeaa127fa */ (T_MASK ^ 0x155ed805)
#define T43 /* 0xd4ef3085 */ (T_MASK ^ 0x2b10cf7a)
#define T44 0x04881d05
#define T45 /* 0xd9d4d039 */ (T_MASK ^ 0x262b2fc6)
#define T46 /* 0xe6db99e5 */ (T_MASK ^ 0x1924661a)
#define T47 0x1fa27cf8
#define T48 /* 0xc4ac5665 */ (T_MASK ^ 0x3b53a99a)
#define T49 /* 0xf4292244 */ (T_MASK ^ 0x0bd6ddbb)
#define T50 0x432aff97
#define T51 /* 0xab9423a7 */ (T_MASK ^ 0x546bdc58)
#define T52 /* 0xfc93a039 */ (T_MASK ^ 0x036c5fc6)
#define T53 0x655b59c3
#define T54 /* 0x8f0ccc92 */ (T_MASK ^ 0x70f3336d)
#define T55 /* 0xffeff47d */ (T_MASK ^ 0x00100b82)
#define T56 /* 0x85845dd1 */ (T_MASK ^ 0x7a7ba22e)
#define T57 0x6fa87e4f
#define T58 /* 0xfe2ce6e0 */ (T_MASK ^ 0x01d3191f)
#define T59 /* 0xa3014314 */ (T_MASK ^ 0x5cfebceb)
#define T60 0x4e0811a1
#define T61 /* 0xf7537e82 */ (T_MASK ^ 0x08ac817d)
#define T62 /* 0xbd3af235 */ (T_MASK ^ 0x42c50dca)
#define T63 0x2ad7d2bb
#define T64 /* 0xeb86d391 */ (T_MASK ^ 0x14792c6e)
static void
md5_process(md5_state_t *pms, const md5_byte_t *data /*[64]*/)
{
md5_word_t
a = pms->abcd[0], b = pms->abcd[1],
c = pms->abcd[2], d = pms->abcd[3];
md5_word_t t;
#if BYTE_ORDER > 0
/* Define storage only for big-endian CPUs. */
md5_word_t X[16];
#else
/* Define storage for little-endian or both types of CPUs. */
md5_word_t xbuf[16];
const md5_word_t *X;
#endif
{
#if BYTE_ORDER == 0
/*
* Determine dynamically whether this is a big-endian or
* little-endian machine, since we can use a more efficient
* algorithm on the latter.
*/
static const int w = 1;
if (*((const md5_byte_t *)&w)) /* dynamic little-endian */
#endif
#if BYTE_ORDER <= 0 /* little-endian */
{
/*
* On little-endian machines, we can process properly aligned
* data without copying it.
*/
if (!((data - (const md5_byte_t *)0) & 3)) {
/* data are properly aligned */
X = (const md5_word_t *)data;
} else {
/* not aligned */
memcpy(xbuf, data, 64);
X = xbuf;
}
}
#endif
#if BYTE_ORDER == 0
else /* dynamic big-endian */
#endif
#if BYTE_ORDER >= 0 /* big-endian */
{
/*
* On big-endian machines, we must arrange the bytes in the
* right order.
*/
const md5_byte_t *xp = data;
int i;
# if BYTE_ORDER == 0
X = xbuf; /* (dynamic only) */
# else
# define xbuf X /* (static only) */
# endif
for (i = 0; i < 16; ++i, xp += 4)
xbuf[i] = xp[0] + (xp[1] << 8) + (xp[2] << 16) + (xp[3] << 24);
}
#endif
}
#define ROTATE_LEFT(x, n) (((x) << (n)) | ((x) >> (32 - (n))))
/* Round 1. */
/* Let [abcd k s i] denote the operation
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
#define F(x, y, z) (((x) & (y)) | (~(x) & (z)))
#define SET(a, b, c, d, k, s, Ti)\
t = a + F(b,c,d) + X[k] + Ti;\
a = ROTATE_LEFT(t, s) + b
/* Do the following 16 operations. */
SET(a, b, c, d, 0, 7, T1);
SET(d, a, b, c, 1, 12, T2);
SET(c, d, a, b, 2, 17, T3);
SET(b, c, d, a, 3, 22, T4);
SET(a, b, c, d, 4, 7, T5);
SET(d, a, b, c, 5, 12, T6);
SET(c, d, a, b, 6, 17, T7);
SET(b, c, d, a, 7, 22, T8);
SET(a, b, c, d, 8, 7, T9);
SET(d, a, b, c, 9, 12, T10);
SET(c, d, a, b, 10, 17, T11);
SET(b, c, d, a, 11, 22, T12);
SET(a, b, c, d, 12, 7, T13);
SET(d, a, b, c, 13, 12, T14);
SET(c, d, a, b, 14, 17, T15);
SET(b, c, d, a, 15, 22, T16);
#undef SET
/* Round 2. */
/* Let [abcd k s i] denote the operation
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
#define G(x, y, z) (((x) & (z)) | ((y) & ~(z)))
#define SET(a, b, c, d, k, s, Ti)\
t = a + G(b,c,d) + X[k] + Ti;\
a = ROTATE_LEFT(t, s) + b
/* Do the following 16 operations. */
SET(a, b, c, d, 1, 5, T17);
SET(d, a, b, c, 6, 9, T18);
SET(c, d, a, b, 11, 14, T19);
SET(b, c, d, a, 0, 20, T20);
SET(a, b, c, d, 5, 5, T21);
SET(d, a, b, c, 10, 9, T22);
SET(c, d, a, b, 15, 14, T23);
SET(b, c, d, a, 4, 20, T24);
SET(a, b, c, d, 9, 5, T25);
SET(d, a, b, c, 14, 9, T26);
SET(c, d, a, b, 3, 14, T27);
SET(b, c, d, a, 8, 20, T28);
SET(a, b, c, d, 13, 5, T29);
SET(d, a, b, c, 2, 9, T30);
SET(c, d, a, b, 7, 14, T31);
SET(b, c, d, a, 12, 20, T32);
#undef SET
/* Round 3. */
/* Let [abcd k s t] denote the operation
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
#define H(x, y, z) ((x) ^ (y) ^ (z))
#define SET(a, b, c, d, k, s, Ti)\
t = a + H(b,c,d) + X[k] + Ti;\
a = ROTATE_LEFT(t, s) + b
/* Do the following 16 operations. */
SET(a, b, c, d, 5, 4, T33);
SET(d, a, b, c, 8, 11, T34);
SET(c, d, a, b, 11, 16, T35);
SET(b, c, d, a, 14, 23, T36);
SET(a, b, c, d, 1, 4, T37);
SET(d, a, b, c, 4, 11, T38);
SET(c, d, a, b, 7, 16, T39);
SET(b, c, d, a, 10, 23, T40);
SET(a, b, c, d, 13, 4, T41);
SET(d, a, b, c, 0, 11, T42);
SET(c, d, a, b, 3, 16, T43);
SET(b, c, d, a, 6, 23, T44);
SET(a, b, c, d, 9, 4, T45);
SET(d, a, b, c, 12, 11, T46);
SET(c, d, a, b, 15, 16, T47);
SET(b, c, d, a, 2, 23, T48);
#undef SET
/* Round 4. */
/* Let [abcd k s t] denote the operation
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
#define I(x, y, z) ((y) ^ ((x) | ~(z)))
#define SET(a, b, c, d, k, s, Ti)\
t = a + I(b,c,d) + X[k] + Ti;\
a = ROTATE_LEFT(t, s) + b
/* Do the following 16 operations. */
SET(a, b, c, d, 0, 6, T49);
SET(d, a, b, c, 7, 10, T50);
SET(c, d, a, b, 14, 15, T51);
SET(b, c, d, a, 5, 21, T52);
SET(a, b, c, d, 12, 6, T53);
SET(d, a, b, c, 3, 10, T54);
SET(c, d, a, b, 10, 15, T55);
SET(b, c, d, a, 1, 21, T56);
SET(a, b, c, d, 8, 6, T57);
SET(d, a, b, c, 15, 10, T58);
SET(c, d, a, b, 6, 15, T59);
SET(b, c, d, a, 13, 21, T60);
SET(a, b, c, d, 4, 6, T61);
SET(d, a, b, c, 11, 10, T62);
SET(c, d, a, b, 2, 15, T63);
SET(b, c, d, a, 9, 21, T64);
#undef SET
/* Then perform the following additions. (That is increment each
of the four registers by the value it had before this block
was started.) */
pms->abcd[0] += a;
pms->abcd[1] += b;
pms->abcd[2] += c;
pms->abcd[3] += d;
}
void
md5_init(md5_state_t *pms)
{
pms->count[0] = pms->count[1] = 0;
pms->abcd[0] = 0x67452301;
pms->abcd[1] = /*0xefcdab89*/ T_MASK ^ 0x10325476;
pms->abcd[2] = /*0x98badcfe*/ T_MASK ^ 0x67452301;
pms->abcd[3] = 0x10325476;
}
void
md5_append(md5_state_t *pms, const md5_byte_t *data, int nbytes)
{
const md5_byte_t *p = data;
int left = nbytes;
int offset = (pms->count[0] >> 3) & 63;
md5_word_t nbits = (md5_word_t)(nbytes << 3);
if (nbytes <= 0)
return;
/* Update the message length. */
pms->count[1] += nbytes >> 29;
pms->count[0] += nbits;
if (pms->count[0] < nbits)
pms->count[1]++;
/* Process an initial partial block. */
if (offset) {
int copy = (offset + nbytes > 64 ? 64 - offset : nbytes);
memcpy(pms->buf + offset, p, copy);
if (offset + copy < 64)
return;
p += copy;
left -= copy;
md5_process(pms, pms->buf);
}
/* Process full blocks. */
for (; left >= 64; p += 64, left -= 64)
md5_process(pms, p);
/* Process a final partial block. */
if (left)
memcpy(pms->buf, p, left);
}
void
md5_finish(md5_state_t *pms, md5_byte_t digest[16])
{
static const md5_byte_t pad[64] = {
0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
};
md5_byte_t data[8];
int i;
/* Save the length before padding. */
for (i = 0; i < 8; ++i)
data[i] = (md5_byte_t)(pms->count[i >> 2] >> ((i & 3) << 3));
/* Pad to 56 bytes mod 64. */
md5_append(pms, pad, ((55 - (pms->count[0] >> 3)) & 63) + 1);
/* Append the length. */
md5_append(pms, data, 8);
for (i = 0; i < 16; ++i)
digest[i] = (md5_byte_t)(pms->abcd[i >> 2] >> ((i & 3) << 3));
}
A Little File Tool
//stdafx.h
#include <stdio.h>
#include <windows.h>
#include <TCHAR.H>
#include "fileMap.h"
#pragma comment(lib, "Rpcrt4.lib")
//filemap.h
typedef void (* HandleFileCallBack)(_TCHAR* fullName, _TCHAR* fileName);
bool mapFile(const _TCHAR* fileName, LPBYTE& ptr, DWORD& size);
void unmapFile(LPBYTE ptr);
void genericFind(const _TCHAR* dir, HandleFileCallBack handleFileCallBack);
bool generateUniqueFileName(LPTSTR buffer, int bufferSize);
//stdafx.cpp
#include "stdafx.h"
//filemap.cpp
#include "stdafx.h"
HANDLE fileHandle, fileMapHandle;
bool mapFile(const _TCHAR* fileName, LPBYTE& ptr, DWORD& size)
{
if (!(fileHandle = CreateFile(fileName, GENERIC_READ|GENERIC_WRITE, FILE_SHARE_READ, NULL,
OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL)))
{
_tprintf(_T("open file %s failed error %d\n"), fileName, GetLastError());
return false;
}
if (!(fileMapHandle = CreateFileMapping(fileHandle, NULL, PAGE_READWRITE, 0, 0, NULL)))
{
_tprintf(_T("create file %s mapping failed error %d\n"), fileName, GetLastError());
CloseHandle(fileHandle);
return false;
}
if (!(ptr = (LPBYTE)MapViewOfFile(fileMapHandle, FILE_MAP_WRITE, 0, 0, 0)))
{
printf("map file %s failed error %d\n", fileName, GetLastError());
CloseHandle(fileHandle);
CloseHandle(fileMapHandle);
return false;
}
size = GetFileSize(fileHandle, NULL);
return true;
}
void unmapFile(LPBYTE ptr)
{
UnmapViewOfFile(ptr);
CloseHandle(fileHandle);
CloseHandle(fileMapHandle);
}
void genericFind(const TCHAR* dir, HandleFileCallBack handleFileCallBack)
{
HANDLE handle;
TCHAR curFileName[MAX_PATH];
TCHAR wildFileName[MAX_PATH];
WIN32_FIND_DATA ffd;
_sntprintf(wildFileName, MAX_PATH, _T("%s\\*.*"), dir);
handle=FindFirstFile(wildFileName, &ffd);
if (handle==INVALID_HANDLE_VALUE)
{
_tprintf(_T("findfirst failed of error code =%d\n"), GetLastError());
exit(19);
}
do
{
if (_tcsicmp(ffd.cFileName, _T("."))!=0 && _tcsicmp(ffd.cFileName, _T(".."))!=0)
{
_stprintf(curFileName, _T("%s\\%s"), dir, ffd.cFileName);
if (GetFileAttributes(curFileName)&FILE_ATTRIBUTE_DIRECTORY)
{
genericFind(curFileName, handleFileCallBack);
}
else
{
handleFileCallBack(curFileName, ffd.cFileName);
}
}
}
while (FindNextFile(handle, &ffd));
FindClose(handle);
}
bool generateUniqueFileName(LPTSTR buffer, int bufferSize)
{
UUID uuid;
if (bufferSize < 33)
{
return false;
}
if (UuidCreate(&uuid) == RPC_S_OK)
{
_stprintf(buffer, _T("%X%X%X"), uuid.Data1, uuid.Data2, uuid.Data3);
return true;
}
return false;
}
//filetools.cpp
#include "stdafx.h"
TCHAR buffer[2048];
int length;
void moveFileHandler(LPTSTR fullName, LPTSTR fileName)
{
int len;
len = _tcslen(fileName);
//if (_tcsnicmp(fileName + len - 4, _T(".jpg"), 4)== 0)
{
//_tcscpy(buffer + length, fileName);
generateUniqueFileName(buffer + length, 2048 - length);
_tcscat(buffer, _T(".jpg"));
if (! MoveFileEx(fullName, buffer, MOVEFILE_COPY_ALLOWED|MOVEFILE_WRITE_THROUGH
|MOVEFILE_REPLACE_EXISTING))
{
printf("error of %d\n", GetLastError());
}
}
}
int _tmain(int argc, LPCTSTR* argv)
{
if (argc ==3)
{
_tcscpy(buffer, argv[2]);
length = _tcslen(buffer);
if (buffer[length]!=_T('\\'))
{
buffer[length] = _T('\\');
length ++;
}
genericFind(argv[1], moveFileHandler);
}
return 0;
}
/* meta wants to hide all traces of amoi and they need to replace all "amoi" to "meta", including file name because those "include" statements. */
#include <windows.h>
#include <stdio.h>
#include <tchar.h>
typedef int (*HandleFileCallBack)(char*dir, char* fileName, void* userData);
typedef struct
{
char* src;
char* dst;
int len;
} ReplaceDataStruct;
struct MyCollectStruct
{
FILE* fSrc;
FILE* fHead;
};
void doReplace(char* ptr, char* src, char* dst, int len)
{
int i;
for (i = 0; i < len; i ++)
{
if (isupper(ptr[i]))
{
ptr[i] = toupper(dst[i]);
}
else
{
ptr[i]= tolower(dst[i]);
}
}
}
int replaceBuffer(char* buffer, DWORD bufferSize, char* src, char* dst, int len)
{
char* ptr = NULL;
int i, counter = 0;
ptr= buffer;
for (i = 0; i< bufferSize; i ++)
{
if (strnicmp(ptr, src, len) == 0)
{
doReplace(ptr, src, dst, len);
counter ++;
}
ptr ++;
}
return counter;
}
int replaceInFile(char* fileName, char* src, char* dst, int len)
{
HANDLE hFile = INVALID_HANDLE_VALUE;
char* buffer;
int counter =0;
DWORD size=0;
DWORD dwSize = 0;
bool result = false;
if ((hFile=CreateFile(fileName, GENERIC_READ|GENERIC_WRITE, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL))!=INVALID_HANDLE_VALUE)
{
if (dwSize=GetFileSize(hFile, NULL))
{
if ((buffer = (char*) malloc(dwSize))!= NULL)
{
if (ReadFile(hFile, buffer, dwSize, &size, NULL) && dwSize == size)
{
counter = replaceBuffer(buffer, dwSize, src, dst, len);
if (counter >0)
{
SetFilePointer(hFile, 0, NULL, FILE_BEGIN);
if (WriteFile(hFile, buffer, dwSize, &size, NULL)&& dwSize==size)
{
result = true;
}
}
else
{
if (counter ==0)
{
result = true;
}
}
}
free(buffer);
}
}
CloseHandle(hFile);
}
if (result)
{
return counter;
}
else
{
return -1;
}
}
int replaceFileName(char* dir, char* fileName, char* src, char* dst, int len)
{
int counter = 0;
char buffer[MAX_PATH];
char oldPath[MAX_PATH*4];
char newPath[MAX_PATH*4];
strcpy(buffer, fileName);
counter = replaceBuffer(buffer, strlen(buffer), src, dst, len);
if (counter > 0)
{
sprintf(oldPath, "%s\\%s", dir, fileName);
sprintf(newPath, "%s\\%s", dir, buffer);
MoveFile(oldPath, newPath);
}
return counter;
}
int replaceFileCallback(char* dir, char* fileName, void* userData)
{
int counter = 0;
char oldPath[MAX_PATH*4];
ReplaceDataStruct* pMyData = (ReplaceDataStruct*)userData;
sprintf(oldPath, "%s\\%s", dir, fileName);
if ((counter = replaceInFile(oldPath, pMyData->src, pMyData->dst, pMyData->len))!= -1)
{
counter += replaceFileName(dir, fileName, pMyData->src, pMyData->dst, pMyData->len);
}
else
{
return -1;
}
return counter;
}
int collectFileCallback(char* dir, char* fileName, void* userData)
{
int counter = 0;
MyCollectStruct* pMyData = (MyCollectStruct*) userData;
char oldPath[MAX_PATH*4];
FILE* stream = NULL;
char* ptr= NULL;
sprintf(oldPath, "%s\\%s", dir, fileName);
if ((ptr = strrchr(fileName, '.'))!= NULL)
{
if (stricmp(ptr, ".c")==0)
{
stream = pMyData->fSrc;
}
else
{
if (stricmp(ptr, ".h")==0)
{
stream = pMyData->fHead;
}
}
if (stream!= NULL)
{
counter = fwrite(oldPath, strlen(oldPath), 1,stream);
fwrite("\n", 1, 1, stream);
}
}
return counter;
}
int genericFind(TCHAR* dir, HandleFileCallBack handleFileCallBack, void* userData)
{
HANDLE handle;
int counter = 0, temp;
TCHAR curFileName[MAX_PATH];
TCHAR wildFileName[MAX_PATH];
WIN32_FIND_DATA ffd;
_sntprintf(wildFileName, MAX_PATH, _T("%s\\*.*"), dir);
handle=FindFirstFile(wildFileName, &ffd);
if (handle==INVALID_HANDLE_VALUE)
{
_tprintf(_T("findfirst failed of error code =%d\n"), GetLastError());
exit(19);
}
do
{
if (_tcsicmp(ffd.cFileName, _T("."))!=0 && _tcsicmp(ffd.cFileName, _T(".."))!=0)
{
_stprintf(curFileName, _T("%s\\%s"), dir, ffd.cFileName);
if (GetFileAttributes(curFileName)&FILE_ATTRIBUTE_DIRECTORY)
{
counter += genericFind(curFileName, handleFileCallBack, userData);
}
else
{
// check extention name
if ((temp = handleFileCallBack(dir, ffd.cFileName, userData)) == -1)
{
counter = -1;
break;
}
else
{
counter += temp;
}
}
}
}
while (FindNextFile(handle, &ffd));
FindClose(handle);
return counter;
}
int myReplace(int argc, char** argv)
{
int counter =0, length;
char path[MAX_PATH];
ReplaceDataStruct myData;
if (argc==4)
{
length = strlen(argv[2]);
if (length != strlen(argv[3]))
{
printf("src '%s' must have same length with dst '%s'\n", argv[2], argv[3]);
return 0;
}
printf("begin search directory %s to replace %s with %s\n\n", argv[1], argv[2], argv[3]);
GetCurrentDirectory(MAX_PATH*4, path);
sprintf(path, "%s\\%s", path, argv[1]);
myData.src = argv[2];
myData.dst = argv[3];
myData.len = strlen(argv[2]);
counter = genericFind(argv[1], replaceFileCallback, &myData);
printf("total replacement of %d\n", counter);
}
else
{
printf("usage: dirName src dst\n");
}
return 0;
}
int myCollect(int argc, char** argv)
{
int counter =0, length;
char path[MAX_PATH];
char name[MAX_PATH];
MyCollectStruct myData;
if (argc==3)
{
printf("begin search directory %s to collect fileName and output %s\n\n", argv[1], argv[2]);
GetCurrentDirectory(MAX_PATH*4, path);
sprintf(path, "%s\\%s", path, argv[1]);
sprintf(name, "%s.source", argv[2]);
if ((myData.fSrc=fopen(name, "w"))!= NULL)
{
sprintf(name, "%s.head", argv[2]);
if ((myData.fHead=fopen(name, "w"))!= NULL)
{
counter = genericFind(argv[1], collectFileCallback, &myData);
printf("total collectment of %d\n", counter);
fclose(myData.fHead);
}
fclose(myData.fSrc);
}
}
else
{
printf("usage: dirName outputFileName\n");
}
return 0;
}
int main(int argc, char** argv)
{
if (argc == 3)
{
return myCollect(argc, argv);
}
if (argc ==4)
{
return myReplace(argc, argv);
}
return 0;
}
A simple tool to find dependency loop in source file (There is no fancy implementation of 'scanner'. Therefore the "#include" statement is by simplest, naive scanning)
//////////////////////////////////////////////////////////////////////////////////////
// When we just enter the computer science department in universities, we are told that Object Oriented
// programming is supposed to ease the job of programmers. And C++ is an OO language. Does that mean C++
// is an easy language to master?
// Most kids across world would readily claim that they know C/C++ which is becoming some kind of default
// in programmers' resume. However, I think C++ is one of most difficult language to grasp as you must really
// understand why it is becoming what it is like today which requires you to become an excellent C programmer.
// After you found the limitation of various fancy macro's in C language you would surely desperately turn
// to help of compiler of C++. Well C++ without STL is almost like people who programming without using stdlib.
// There would be pains and joys, depending on how tight your schedule would be, for you to re-invent every wheels
// which have been created dozens of years ago.
// Therefore I hope this would be some kind of help for kids who claim they know how to program. Enjoy! :)
//////////////////////////////////////////////////////////////////////////////////////
#include <windows.h>
#include <stdio.h>
#include <set>
#include <vector>
#include <tchar.h>
#define MY_FILE_NAME_SIZE (MAX_PATH/4)
/////////////////////////////////////////////////////////////////////////////////////////////////
// template print function for set element
template<class T>
void templatePrint(T& t)
{
T::iterator it;
for (it = t.begin(); it != t.end(); it ++)
{
it->print();
}
}
////////////////////////////////////////////////////////////////////////////////////////////////
/////////////////////////////////////////////////
// forward declaration
struct FileNameStructComp;
struct FileNameStruct;
struct FileDependManager;
struct FileDependPairStruct;
/////////////////////////////////////////////////
typedef int (*HandleFileCallBack)(char*dirName, char*fileName, void* userData);
void genericFind(TCHAR* dir, HandleFileCallBack handleFileCallBack, void* userData);
// we need struct to capsulate char buffer is because of STL
// char buf[] is actually a "const" pointer and set, vector etc. expect to take a non-const element
struct FileNameStruct
{
char name[MY_FILE_NAME_SIZE];
FileNameStruct()
{
name[0]='\0';
}
void print()
{
printf("name: %s\n", name);
}
};
struct FilePathStruct
{
char path[MAX_PATH*2];
FilePathStruct()
{
path[0] = '\0';
}
void print()
{
printf("path: %s\n", path);
}
};
struct FileInfoStruct
{
FileNameStruct name;
FilePathStruct path;
void print()
{
path.print();
name.print();
}
};
//////////////////////////////////////////////////////
// various "functor" for enforcing "total ordering" in container. Read MSDN!
struct FileNameStructComp
{
bool operator()(const FileNameStruct& left, const FileNameStruct& right)const
{
return stricmp(left.name, right.name) < 0;
}
};
struct FileInfoStructComp
{
bool operator()(const FileInfoStruct& left, const FileInfoStruct& right) const
{
return stricmp(left.name.name, right.name.name) < 0 ;
}
};
//////////////////////////////////////////////////////
//////////////////////////////////////////////////////
// I hate to write "using namespace std;" because it will also include many unwanted stuff
typedef std::set<FileNameStruct, FileNameStructComp> FileNameSet;
typedef std::pair<FileNameSet::iterator, bool> FileNameSetResult;
typedef std::set<FileInfoStruct, FileInfoStructComp> FileInfoSet;
typedef std::pair<FileInfoSet::iterator, bool> FileInfoSetResult;
typedef std::pair<FileNameStruct, FileNameStruct> FileNamePair;
//////////////////////////////////////////////////////
bool isSourceFile(char* fileName)
{
char* ptr = NULL;
if ((ptr= strrchr(fileName, '.'))!= NULL)
{
return stricmp(ptr, ".h")==0 || stricmp(ptr, ".c")==0 || stricmp(ptr, ".cpp")== 0;
}
return false;
}
////////////////////////////////////////////////////////
// the reason i prefer "struct" than "class" is because I hate to type "public:" inside class
// There is no second man in this world who would like to use my code and why should I care about those
// OO rules?
// There is a moment that I decide to drop "refSet" because everyone has its "depSet" and you can calculate
// "refSet" for each other. Soon I returned to original design because this calculation is quite expensive.
// Therefore wasting some storage for better performance. Besides constructing "refset" is quite natural when
// iterating all source files in directory.
typedef struct
{
FileNameStruct me;
FileNameSet depSet;
FileNameSet refSet;
bool addDep(char* fileName);
bool addRef(char* fileName);
bool findLoop(FileNameSet& loopSet);
void print()
{
printf("me: ");
me.print();
printf("\n*********************************\ndepSet: ");
templatePrint<FileNameSet>(depSet);
printf("\n*********************************\nrefSet: ");
templatePrint<FileNameSet>(refSet);
}
} FileDependStruct;
struct FileDependStructComp
{
bool operator()(const FileDependStruct& left, const FileDependStruct& right) const
{
return stricmp(left.me.name, right.me.name) < 0;
}
};
typedef std::set<FileDependStruct, FileDependStructComp> FileDependSet;
typedef std::pair<FileDependSet::iterator, bool> FileDependResult;
typedef std::pair<FileNameStruct, FileNameStruct> FileDependPair;
// This is a kind of legacy before I use "FileDependPairStruct" instead of "FileDependPair"
// see comment of "FileDependPairStruct"
struct FileDependPairComp
{
bool operator()(const FileDependPair& left, const FileDependPair& right) const
{
int result;
result = stricmp(left.first.name, right.first.name);
if (result == 0)
{
return stricmp(left.second.name, right.second.name) < 0;
}
else
{
return result < 0;
}
}
};
////////////////////////////////////////////////////////
// The reason for this little wrap-up is that I want to avoid repeating in "mutual-dependency-pair" listing.
// For example, A and B are mutual dependent. Therefore you will end up to store both pair<A,B> and pair<B,A>
// which is redundent. In the following struct, it enforce alphabetic order for "pair"'s "first" and "second".
// Another direct reason is that I want to use "templatePrint" which requires each element in container to have a \
// member function called "print". And the original STL "pair" cannot do this.
struct FileDependPairStruct
{
FileDependPair pair;
FileDependPairStruct(const FileNameStruct& left, const FileNameStruct& right)
{
if (stricmp(left.name, right.name) < 0 )
{
pair.first = left;
pair.second = right;
}
else
{
pair.first = right;
pair.second = left;
}
}
void print()
{
printf("[%s] <=====> [%s]\n", pair.first.name, pair.second.name);
}
};
struct FileDependPairStructComp
{
bool operator()(const FileDependPairStruct& left, const FileDependPairStruct& right) const
{
FileDependPairComp comp;
return comp(left.pair, right.pair);
}
};
typedef std::set<FileDependPairStruct, FileDependPairStructComp> FileDependPairSet;
struct FileDependManager
{
FileInfoSet all;
FilePathStruct path;
FileDependSet dependSet;
int addFilePath(char* fileName, char* pathName);
int readFile(FileDependStruct* pDepStruct, char* pathName);
int readDir(char* dirName);
bool readLine(FileDependStruct* pDepNode, char*lineBuffer);
int addDepRef(FileDependStruct* pDepNode, FileDependStruct* pRefNode);
bool findIncludeFileName(char* lineBuffer, char* szNameBuffer);
//int writeFile(char* fileName);
int findLoop(FileDependPairSet& loopPairSet);
void print()
{
printf("path: ");
path.print();
printf("all file info: ");
templatePrint<FileInfoSet>(all);
printf("dependSet: ");
templatePrint<FileDependSet>(dependSet);
}
};
int myCreateSetCallback(char* dirName, char*fileName, void* userData);
int FileDependManager::readDir(char* pathName)
{
strcpy(path.path, pathName);
genericFind(pathName, myCreateSetCallback, this);
return 0;
}
bool FileDependManager::findIncludeFileName(char* lineBuffer, char* szNameBuffer)
{
char* ptr = NULL;
int i = 0;
// To Do : // add filter for comment, white space etc... later if (strncmp(lineBuffer, "#include ", 9) == 0) { ptr = lineBuffer + 9; if ((ptr = strchr(ptr, '"'))!= NULL) { ptr ++; while (*ptr != '"') { szNameBuffer[i] = *ptr; if (*ptr == '\0') { return false; //no ending } i++; ptr++; } szNameBuffer[i] = '\0'; return true; } } return false; } // TO DO: we need a "state" to indicate 'comment' begin, end, 'macro' begin, end etc... // let's use a 'uint32' for bitmap later bool FileDependManager::readLine(FileDependStruct* pDepNode, char* lineBuffer) { FileDependStruct refNode; FileDependResult result; if (findIncludeFileName(lineBuffer, refNode.me.name)) { pDepNode->addDep(refNode.me.name); result = dependSet.insert(refNode); result.first->addRef(pDepNode->me.name); return true; } return false; } int FileDependManager::readFile(FileDependStruct* pDepStruct, char* pathName) { char pathBuffer[MAX_PATH*2]; char lineBuffer[1024]; char* ptr = NULL; FILE* stream = NULL; //FileNameStruct node; int counter = 0; sprintf(pathBuffer, "%s\\%s", pathName, pDepStruct->me.name); if ((stream = fopen(pathBuffer, "r")) != NULL) { while (!feof(stream)) { if (fgets(lineBuffer, 1024, stream)!= NULL) { counter = readLine(pDepStruct, lineBuffer); } } fclose(stream); } return 0; } bool FileDependStruct::findLoop(FileNameSet& loopSet) { FileNameSet::iterator it; loopSet.clear(); for (it = depSet.begin(); it!= depSet.end(); it++) { if (refSet.find(*it) != refSet.end()) { loopSet.insert(*it); } } return ! loopSet.empty(); } int FileDependManager::findLoop(FileDependPairSet& loopPairSet) { FileNameSet::iterator it; FileDependSet::iterator depIt; FileNameSet loopSet; for (depIt = dependSet.begin(); depIt != dependSet.end(); depIt ++) { if (depIt->findLoop(loopSet)) { for (it = loopSet.begin(); it != loopSet.end(); it ++) { loopPairSet.insert(FileDependPairStruct(depIt->me, *it)); } } } return 0; } int FileDependManager::addFilePath(char* fileName, char* pathName) { FileInfoStruct node; if (pathName) { strcpy(node.name.name, fileName); strcpy(node.path.path, pathName); all.insert(node); } return 1; } bool FileDependStruct::addDep(char* fileName) { FileNameStruct dep; FileNameSetResult result; strcpy(dep.name, fileName); result = depSet.insert(dep); return result.second; } bool FileDependStruct::addRef(char* fileName) { FileNameStruct ref; FileNameSetResult result; strcpy(ref.name, fileName); result = refSet.insert(ref); return result.second; } void genericFind(TCHAR* dir, HandleFileCallBack handleFileCallBack, void* userData) { HANDLE handle; TCHAR curFileName[MAX_PATH]; TCHAR wildFileName[MAX_PATH]; WIN32_FIND_DATA ffd; _sntprintf(wildFileName, MAX_PATH, _T("%s\\*.*"), dir); handle=FindFirstFile(wildFileName, &ffd); if (handle==INVALID_HANDLE_VALUE) { _tprintf(_T("findfirst failed of error code =%d\n"), GetLastError()); exit(19); } do { if (_tcsicmp(ffd.cFileName, _T("."))!=0 && _tcsicmp(ffd.cFileName, _T(".."))!=0) { _stprintf(curFileName, _T("%s\\%s"), dir, ffd.cFileName); if (GetFileAttributes(curFileName)&FILE_ATTRIBUTE_DIRECTORY) { genericFind(curFileName, handleFileCallBack, userData); } else { // check extention name handleFileCallBack(dir, ffd.cFileName, userData); } } } while (FindNextFile(handle, &ffd)); FindClose(handle); } int myCreateSetCallback(char* dirName, char*fileName, void* userData) { FileDependManager* pThis= (FileDependManager*)userData; FileDependStruct node; FileDependResult result; if (isSourceFile(fileName)) { pThis->addFilePath(fileName, dirName); strcpy(node.me.name, fileName); result = pThis->dependSet.insert(node); pThis->readFile(&(*result.first), dirName); } return 0; } int main(int argc, char** argv) { FileDependManager manager; FileDependPairSet loopSet; if (argc == 2) { manager.readDir(argv[1]); manager.findLoop(loopSet); manager.print(); templatePrint<FileDependPairSet>(loopSet); } return 0; } /* int FileDependStruct::writeFile(char* fileName) { FILE* stream = NULL; FileNameSet::iterator it; int counter = 0; if ((stream = fopen(fileName, "w")) != NULL) { fprintf(stream, "[%s] depend:\n", me.name); for (it = depSet.begin(); it != depSet.end(); it ++) { counter ++; fprintf(stream, "[%s]\n", it->name); } fprintf(stream, "\n*****************************\n[%s] reference:\n", me.name); for (it = refSet.begin(); it != refSet.end(); it ++) { counter ++; fprintf(stream, "[%s]\n", it->name); } fclose(stream); } return counter; } */ My Little Network LZW Idea(no network now at all cause it is just a beginning :))
#include <map>
#include <string>
#include <windows.h>
#include <TCHAR.h>
#include <stdio.h>
#pragma warning(disable : 4786; once 4786)
typedef unsigned short ushort;
typedef unsigned char uchar;
struct StringCmp
{
bool operator()(const std::string& strLeft, const std::string& strRight) const
{
#if 1
const char* ptr1 = strLeft.data();
const char* ptr2 = strRight.data();
int size1 = strLeft.size();
int size2 = strRight.size();
if (size1 != size2)
{
return size1 < size2;
}
return memcmp(ptr1, ptr2, size1) < 0;
#else
return memcmp(strLeft.data(), strRight.data(), strLeft.size()) < 0;
#endif
}
};
struct OutputFileHeader
{
char magicWord[8]; //"MYNETLZW"
ushort version;
ushort unIndexSize; // 2 for ushort
DWORD dwTableOffset;
OutputFileHeader()
{
memcpy(magicWord, "MYNETLZW", 8);
version = 1.0;
unIndexSize = 2;
dwTableOffset = sizeof(OutputFileHeader); // when file is empty
}
};
typedef std::map<ushort, std::string> IndexTable;
typedef std::map<std::string, ushort, StringCmp> StringTable;
typedef std::map<ushort, DWORD> HitTable;
struct LZW
{
TCHAR strDictionaryName[1024];
OutputFileHeader fileHeader;
StringTable stringTable;
IndexTable indexTable;
//FILE* inStream;
//FILE* outStream;
LZW(LPCTSTR strFileName=_T("myDictionary.txt"));
~LZW();
bool compressFile(LPCTSTR strInFileName, LPCTSTR strOutFileName);
bool decompressFile(LPCTSTR strInFileName, LPCTSTR strOutFileName);
bool saveDictionary(LPCTSTR strFileName, StringTable& table);
bool mergeDictionary(StringTable& source, StringTable& other);
bool loadDictionary(LPCTSTR strFileName, StringTable& table);
bool beginCompression(FILE* stream);
bool beginDecompression(FILE* stream, DWORD& dwOffset, IndexTable& table);
bool endDecompression(FILE* inStream, FILE* outStream, bool bWithError);
bool endCompression(FILE*inStream, FILE* outStream, StringTable& table, bool bWithError);
bool doSaveDictionary(FILE* stream, StringTable& table);
bool doCompression(FILE* inStream, FILE* outStream, StringTable& table);
bool doDecompression(FILE* inStream, FILE* outStream, IndexTable& table, DWORD dwOffset = 0);
bool doLoadDictionary(FILE* stream, StringTable& table);
bool stringTable2IndexTable(StringTable& stringTable, IndexTable& indexTable);
bool initStringTable(StringTable& table);
};
struct DictionaryEntry
{
ushort unLen;
ushort unIndex;
char array[1];
};
bool LZW::mergeDictionary(StringTable& source, StringTable& other)
{
for (StringTable::iterator it = other.begin(); it != other.end(); it ++)
{
if (source.find(it->first) != source.end())
{
source.insert(StringTable::value_type(it->first, source.size()));
}
}
return true;
}
bool LZW::stringTable2IndexTable(StringTable& stringTable, IndexTable& indexTable)
{
StringTable::iterator it;
int i = 0;
std::pair<IndexTable::iterator, bool> ret;
for (it = stringTable.begin(); it != stringTable.end(); ++ it)
{
ret = indexTable.insert(IndexTable::value_type(it->second, it->first));
//indexTable.insert(IndexTable::value_type(it->second, it->first));
if (!ret.second)
{
return false;
}
i ++;
}
return true;
}
bool LZW::loadDictionary(LPCTSTR strFileName, StringTable& table)
{
bool result = false;
std::string str;
FILE* stream = NULL;
if ((stream= fopen(strFileName, "r+b"))!= NULL)
{
if (doLoadDictionary(stream, table))
{
result = mergeDictionary(stringTable, table);
}
fclose(stream);
}
return result;
}
bool LZW::doLoadDictionary(FILE* stream, StringTable& table)
{
bool result = true;
std::string str;
ushort unLen, unIndex;
char buffer[1024];
while (!feof(stream))
{
result = false;
//str.erase(str.begin(), str.end());
if (fread(&unLen, sizeof(ushort), 1, stream)==1)
{
if (fread(&unIndex, sizeof(ushort), 1, stream)==1)
{
if (fread(buffer, unLen, 1, stream)==1)
{
result = true;
str.assign(buffer, unLen);
table.insert(StringTable::value_type(str, unIndex));
}
}
}
if (!result)
{
result = feof(stream);
break;
}
}
return result;
}
bool LZW::doSaveDictionary(FILE* stream, StringTable& table)
{
bool bResult = true;
char buffer[1024];
const char* ptr;
int size;
DictionaryEntry* pDict = (DictionaryEntry*)buffer;
for (StringTable::iterator it = table.begin(); it != table.end(); ++ it)
{
pDict->unLen = it->first.size();
pDict->unIndex = it->second;
memcpy(pDict->array, it->first.data(), it->first.size());
if (fwrite(pDict, pDict->unLen+2*sizeof(ushort), 1, stream)!= 1)
{
bResult = false;
break;
}
}
return bResult;
}
bool LZW::saveDictionary(LPCTSTR strFileName, StringTable& table)
{
bool bResult = false;
FILE* stream;
if ((stream = fopen(strFileName, "w+b"))!= NULL)
{
bResult = doSaveDictionary(stream, table);
fclose(stream);
}
return bResult;
}
bool LZW::initStringTable(StringTable& table)
{
std::string str;
ushort unIndex;
uchar ch = 0;
std::pair<StringTable::iterator, bool> ret;
do
{
str.erase(str.begin(), str.end());
str.append(1, ch);
unIndex = table.size();
ret = table.insert(StringTable::value_type(str, unIndex));
if (!ret.second)
{
return false;
}
ch ++;
}
while (ch != 255);
return true;
}
LZW::LZW(LPCTSTR strFileName)
{
//_tcscpy(strDictionaryName, strFileName);
//loadDictionary(strDictionaryName, stringTable);
}
LZW::~LZW()
{
saveDictionary(strDictionaryName, stringTable);
}
bool LZW::beginCompression(FILE* outStream)
{
OutputFileHeader header;
return fwrite(&header, sizeof(OutputFileHeader), 1, outStream) == 1;
}
bool LZW::endCompression(FILE*inStream, FILE* outStream, StringTable& table, bool bWithError)
{
bool bResult = false;
DWORD dwOffset;
if (!bWithError)
{
dwOffset = ftell(outStream);
if (doSaveDictionary(outStream, table))
{
fseek(outStream, 8+sizeof(ushort)*2, SEEK_SET);
bResult = fwrite(&dwOffset, sizeof(DWORD), 1, outStream) == 1;
}
}
if (inStream!= NULL)
{
fclose(inStream);
}
if (outStream!= NULL)
{
fclose(outStream);
}
return bResult;
}
bool LZW::beginDecompression(FILE* stream, DWORD& dwOffset, IndexTable& indexTable)
{
StringTable stringTable;
OutputFileHeader fileHeader;
if (fread(&fileHeader, sizeof(OutputFileHeader), 1, stream) == 1)
{
if (memcmp(fileHeader.magicWord, "MYNETLZW", 8)==0)
{
dwOffset = fileHeader.dwTableOffset;
if (fseek(stream, dwOffset, SEEK_SET)==0)
{
if (doLoadDictionary(stream, stringTable))
{
return stringTable2IndexTable(stringTable, indexTable);
}
}
}
}
return false;
}
bool LZW::doCompression(FILE* inStream, FILE* outStream, StringTable& table)
{
bool bWithError = true;
char ch;
ushort unIndex= table.size();
StringTable::iterator it;
std::string preStr;
while (true)
{
if (fread(&ch, sizeof(ch), 1, inStream) != 1)
{
break;
}
preStr.append(1, ch);
if (preStr.size() == 1)
{
unIndex = ch;
}
else
{
if ((it = table.find(preStr))== table.end())
{
//unIndex = table.size();
table.insert(StringTable::value_type(preStr, table.size() + 256));
if (fwrite(&unIndex, sizeof(ushort), 1, outStream)!= 1)
{
break;
}
preStr.erase(preStr.begin(), preStr.end());
preStr.append(1, ch);
//it = table.find(preStr);
unIndex = ch;
}
else
{
unIndex = it->second;
}
}
}
if (feof(inStream))
{
if (!preStr.empty())
{
if (preStr.size() > 1)
{
it = table.find(preStr);
unIndex = it->second;
}
else
{
unIndex = preStr[0];
}
bWithError = fwrite(&unIndex, sizeof(ushort), 1, outStream)!= 1;
}
else
{
bWithError = false;
}
}
return !bWithError;
}
bool LZW::compressFile(LPCTSTR strInFileName, LPCTSTR strOutFileName)
{
bool bWithError = true;
FILE* inStream, *outStream;
StringTable table;
do
{
/*
// this is not really necessary cause we know it is there.
if (!initStringTable(table))
{
break;
}
*/
if ((inStream=fopen(strInFileName, _T("r+b")))== NULL)
{
break;
}
if ((outStream = fopen(strOutFileName, _T("w+b")))== NULL)
{
break;
}
if (!beginCompression(outStream))
{
break;
}
bWithError = !doCompression(inStream, outStream, table);
}
while (false);
endCompression(inStream, outStream, table, bWithError);
return true;
}
bool LZW::doDecompression(FILE* inStream, FILE* outStream, IndexTable& table, DWORD dwOffset)
{
bool bWithError = true;
ushort nIndex;
DWORD dwCurOffset;
char buffer[1];
ushort nSize;
const char* ptr;
IndexTable::iterator it;
while (!feof(inStream))
{
dwCurOffset = ftell(inStream);
if (dwCurOffset == dwOffset)
{
bWithError = false;
break;
}
else
{
if (dwCurOffset > dwOffset)
{
break;
// with error
}
}
if (fread(&nIndex, sizeof(ushort), 1, inStream) != 1)
{
break;
}
if (nIndex < 256)
{
buffer[0] = nIndex;
ptr = buffer;
nSize = 1;
}
else
{
if ((it = table.find(nIndex)) == table.end())
{
break;
}
ptr = it->second.data();
nSize = it->second.size();
}
if (fwrite(ptr, nSize, 1, outStream)!= 1)
{
break;
}
}
return !bWithError;
}
bool LZW::decompressFile(LPCTSTR strInFileName, LPCTSTR strOutFileName)
{
bool bWithError = true;
ushort unIndex = 0;
IndexTable table;
FILE* inStream, *outStream;
DWORD dwOffset;
do
{
if ((inStream=fopen(strInFileName, _T("r+b")))== NULL)
{
break;
}
if ((outStream = fopen(strOutFileName, _T("w+b")))== NULL)
{
break;
}
if (!beginDecompression(inStream, dwOffset, table))
{
break;
}
if (fseek(inStream, sizeof(OutputFileHeader), SEEK_SET)==0)
{
bWithError = !doDecompression(inStream, outStream, table, dwOffset);
}
}
while (false);
endDecompression(inStream, outStream, bWithError);
return true;
}
bool LZW::endDecompression(FILE* inStream, FILE* outStream, bool bWithError)
{
if (inStream)
{
fclose(inStream);
}
if (outStream)
{
fclose(outStream);
}
return !bWithError;
}
int _tmain(int argc, TCHAR** argv)
{
LZW dictionary;
TCHAR strBuf[1024];
if (argc == 3)
{
dictionary.compressFile(argv[1], argv[2]);
_stprintf(strBuf, _T("%s.txt"), argv[1]);
dictionary.decompressFile(argv[2], strBuf);
}
return 0;
}
A Sample Test from GDI
#include <windows.h>
#include <stdio.h>
#include <math.h>
#include <time.h>
#include "resource.h"
HINSTANCE hInst; // current instance
char szAppName[] = "myPathTest"; // The name of this application
char szTitle[] = "Path Test Application"; // The title bar text
#if 0
CHOOSEFONT cf; // common dialog box font structure
LOGFONT lf; // logical font structure
HFONT hfont; // new logical font handle
HFONT hfontOld; // original logical font handle
HDC hdc; // display DC handle
int nXStart, nYStart; // drawing coordinates
RECT rc; // structure for painting window
SIZE sz; // structure that receives text extents
double aflSin[90]; // sine of 0-90 degrees
double aflCos[90]; // cosine of 0-90 degrees
double flRadius,a; // radius of circle
int iMode = IDM_AND; // clipping mode
HRGN hrgn; // clip region handle
LRESULT APIENTRY MainWndProc(
HWND hwnd, // window handle
UINT message, // type of message
WPARAM wParam, // additional information
LPARAM lParam) // additional information
{
PAINTSTRUCT ps;
int i;
COLORREF crOld;
switch (message)
{
case WM_PAINT:
hdc = BeginPaint(hwnd, &ps);
EndPaint(hwnd, &ps);
break;
case WM_COMMAND: // command from app's menu
switch (wParam)
{
case IDM_VANISH: // erases client area
hdc = GetDC(hwnd);
GetClientRect(hwnd, &rc);
FillRect(hdc, &rc, (HBRUSH)GetStockObject(WHITE_BRUSH));
ReleaseDC(hwnd, hdc);
break;
case IDM_AND: // sets clip mode to RGN_AND
iMode = RGN_AND;
break;
case IDM_COPY: // sets clip mode to RGN_COPY
iMode = RGN_COPY;
break;
case IDM_DIFF: // sets clip mode to RGN_DIFF
iMode = RGN_DIFF;
break;
case IDM_OR: // sets clip mode to RGN_OR
iMode = RGN_OR;
break;
case IDM_XOR: // sets clip mode to RGN_XOR
iMode = RGN_XOR;
break;
case IDM_CLIP_PATH:
// Retrieve a cached DC for the window.
hdc = GetDC(hwnd);
// Use the font requested by the user in the
// Choose Font dialog box to create a logical
// font, then select that font into the DC.
hfont = CreateFontIndirect(cf.lpLogFont);
hfontOld = (HFONT)SelectObject(hdc, hfont);
// Retrieve the dimensions of the rectangle
// that surrounds the text.
GetTextExtentPoint32(hdc, "Clip Path", 9, &sz);
// Set a clipping region using the rect that
// surrounds the text.
hrgn = CreateRectRgn(nXStart, nYStart, nXStart + sz.cx, nYStart + sz.cy);
SelectClipRgn(hdc, hrgn);
// Create a clip path using text drawn with
// the user's requested font.
BeginPath(hdc);
TextOut(hdc, nXStart, nYStart, "Clip Path", 9);
EndPath(hdc);
SelectClipPath(hdc, iMode);
// Compute the sine of 0, 1, ... 90 degrees.
for (i = 0; i < 90; i++)
{
aflSin[i] = sin( (((double)i) / 180.0)
* 3.14159);
}
// Compute the cosine of 0, 1,... 90 degrees.
for (i = 0; i < 90; i++)
{
aflCos[i] = cos( (((double)i) / 180.0)
* 3.14159);
}
// Set the radius value.
flRadius = (double)(2 * sz.cx);
// Draw the 90 rays extending from the
// radius to the edge of the circle.
for (i = 0; i < 90; i++)
{
MoveToEx(hdc, nXStart, nYStart,
(LPPOINT) NULL);
LineTo(hdc, nXStart + ((int) (flRadius * aflCos[i])), nYStart + ((int) (flRadius * aflSin[i])));
}
// Reselect the original font into the DC.
SelectObject(hdc, hfontOld);
// Delete the user's font.
DeleteObject(hfont);
// Release the DC.
ReleaseDC(hwnd, hdc);
break;
case IDM_FONT:
// Initialize necessary members.
cf.lStructSize = sizeof (CHOOSEFONT);
cf.hwndOwner = hwnd;
cf.lpLogFont = &lf;
cf.Flags = CF_SCREENFONTS | CF_EFFECTS;
cf.rgbColors = RGB(0, 255, 255);
cf.nFontType = SCREEN_FONTTYPE;
// Display the Font dialog box, allow the user
// to choose a font, and render text in the
// window with that selection.
if (ChooseFont(&cf))
{
hdc = GetDC(hwnd);
hfont = CreateFontIndirect(cf.lpLogFont);
hfontOld = (HFONT)SelectObject(hdc, hfont);
crOld = SetTextColor(hdc, cf.rgbColors);
TextOut(hdc, nXStart, nYStart, "Clip Path", 9);
SetTextColor(hdc, crOld);
SelectObject(hdc, hfontOld);
DeleteObject(hfont);
ReleaseDC(hwnd, hdc);
}
break;
default:
return DefWindowProc(hwnd, message, wParam,
lParam);
}
break;
case WM_DESTROY: // window is being destroyed
PostQuitMessage(0);
break;
default:
return DefWindowProc(hwnd, message, wParam, lParam);
}
return 0;
}
#endif
#if 0
LRESULT APIENTRY MainWndProc(HWND hwndMain, UINT uMsg, WPARAM wParam, LPARAM lParam)
{
HDC hdc; // handle to device context
RECT rcClient; // client area rectangle
POINT ptClientUL; // client upper left corner
POINT ptClientLR; // client lower right corner
static POINTS ptsBegin; // beginning point
static POINTS ptsEnd; // new endpoint
static POINTS ptsPrevEnd; // previous endpoint
static BOOL fPrevLine = FALSE; // previous line flag
switch (uMsg)
{
case WM_LBUTTONDOWN:
// Capture mouse input.
SetCapture(hwndMain);
// Retrieve the screen coordinates of the client area,
// and convert them into client coordinates.
GetClientRect(hwndMain, &rcClient);
ptClientUL.x = rcClient.left;
ptClientUL.y = rcClient.top;
// Add one to the right and bottom sides, because the
// coordinates retrieved by GetClientRect do not
// include the far left and lowermost pixels.
ptClientLR.x = rcClient.right + 1;
ptClientLR.y = rcClient.bottom + 1;
ClientToScreen(hwndMain, &ptClientUL);
ClientToScreen(hwndMain, &ptClientLR);
// Copy the client coordinates of the client area
// to the rcClient structure. Confine the mouse cursor
// to the client area by passing the rcClient structure
// to the ClipCursor function.
SetRect(&rcClient, ptClientUL.x, ptClientUL.y,
ptClientLR.x, ptClientLR.y);
ClipCursor(&rcClient);
// Convert the cursor coordinates into a POINTS
// structure, which defines the beginning point of the
// line drawn during a WM_MOUSEMOVE message.
ptsBegin = MAKEPOINTS(lParam);
return 0;
case WM_MOUSEMOVE:
// When moving the mouse, the user must hold down
// the left mouse button to draw lines.
if (wParam & MK_LBUTTON)
{
// Retrieve a device context (DC) for the client area.
hdc = GetDC(hwndMain);
// The following function ensures that pixels of
// the previously drawn line are set to white and
// those of the new line are set to black.
SetROP2(hdc, R2_NOTXORPEN);
// If a line was drawn during an earlier WM_MOUSEMOVE
// message, draw over it. This erases the line by
// setting the color of its pixels to white.
if (fPrevLine)
{
MoveToEx(hdc, ptsBegin.x, ptsBegin.y,
(LPPOINT) NULL);
LineTo(hdc, ptsPrevEnd.x, ptsPrevEnd.y);
}
// Convert the current cursor coordinates to a
// POINTS structure, and then draw a new line.
ptsEnd = MAKEPOINTS(lParam);
MoveToEx(hdc, ptsBegin.x, ptsBegin.y, (LPPOINT) NULL);
LineTo(hdc, ptsEnd.x, ptsEnd.y);
// Set the previous line flag, save the ending
// point of the new line, and then release the DC.
fPrevLine = TRUE;
ptsPrevEnd = ptsEnd;
ReleaseDC(hwndMain, hdc);
}
break;
case WM_LBUTTONUP:
// The user has finished drawing the line. Reset the
// previous line flag, release the mouse cursor, and
// release the mouse capture.
fPrevLine = FALSE;
ClipCursor(NULL);
ReleaseCapture();
return 0;
case WM_DESTROY:
PostQuitMessage(0);
break;
default:
return DefWindowProc(hwndMain, uMsg, wParam, lParam);
}
return 0;
// Process other messages.
}
#endif
BOOL GetGuideLine(HWND hWnd)
{
MSG msg;
HDC hDC = GetDC(hWnd);
BOOL bFirstTime = TRUE;
RECT rect;
DWORD handle = NULL;
char buffer[256];
//SetCapture(hWnd);
GetClientRect(hWnd, &rect);
while (true)
{
if (handle == NULL)
{
handle = GetCurrentThreadId();
sprintf(buffer, "guide line threadid=%d\n", handle);
OutputDebugString(buffer);
}
WaitMessage();
if (PeekMessage(&msg,NULL,WM_MOUSEFIRST,WM_MOUSELAST,PM_REMOVE))
{
// Make sure we are still tracking in our client area
//if ((LOWORD(msg.lParam) < rect.right) && (HIWORD(msg.lParam) < rect.bottom))
{
// Set the CP to our starting position if we are starting
if (bFirstTime)
{
bFirstTime = FALSE;
MoveToEx(hDC, LOWORD(msg.lParam), HIWORD(msg.lParam), NULL);
}
// If we dont have more points than we want...
// Draw from the last point to this one
LineTo(hDC, LOWORD(msg.lParam), HIWORD(msg.lParam));
}
// Bail when the user lets the left button up
if (msg.message == WM_LBUTTONUP)
{
//break;
}
}
}
OutputDebugString("guide out\n");
ReleaseDC(hWnd, hDC);
//ReleaseCapture();
return TRUE;
}
#if 1
static bool bBegin = false;
LRESULT APIENTRY MainWndProc(
HWND hwnd, // window handle
UINT message, // type of message
WPARAM wParam, // additional information
LPARAM lParam) // additional information
{
DWORD handle = NULL;
char buffer[256];
switch (message)
{
case WM_CREATE:
return TRUE;
break;
case WM_LBUTTONDOWN:
bBegin = true;
GetGuideLine(hwnd);
bBegin = false;
break;
case WM_PAINT:
if (bBegin)
{
//MessageBox(hwnd, "Ok", "OK", MB_OK);
OutputDebugString("paint is calling\n");
}
break;
default:
if (bBegin)
{
if (handle == NULL)
{
handle = GetCurrentThreadId();
sprintf(buffer, "main threadid=%d\n and message=%d", handle, message);
OutputDebugString(buffer);
}
//MessageBox(hwnd, "why Ok", "OK", MB_OK);
}
else
{
return DefWindowProc(hwnd, message, wParam, lParam);
}
break;
}
return TRUE;
}
#endif
BOOL InitApplication(HINSTANCE hInstance)
{
WNDCLASS wc;
// Fill in window class structure with parameters that describe the
// main window.
wc.style = CS_OWNDC; // Class style(s).
wc.lpfnWndProc = (WNDPROC)MainWndProc; // Window Procedure
wc.cbClsExtra = 0; // No per-class extra data.
wc.cbWndExtra = 0; // No per-window extra data.
wc.hInstance = hInstance; // Owner of this class
wc.hIcon = LoadIcon (hInstance, szAppName); // Icon name from .RC
wc.hCursor = LoadCursor(NULL, IDC_ARROW);// Cursor
wc.hbrBackground = (HBRUSH)(COLOR_WINDOW+1);// Default color
wc.lpszMenuName = "MYMENU"; // Menu name from .RC
wc.lpszClassName = szAppName; // Name to register as
// Register the window class and return success/failure code.
return (RegisterClass(&wc));
}
BOOL InitInstance(HINSTANCE hInstance, int nCmdShow)
{
HWND hWnd; // Main window handle.
// Save the instance handle in static variable, which will be used in
// many subsequence calls from this application to Windows.
hInst = hInstance; // Store instance handle in our global variable
// Create a main window for this application instance.
hWnd = CreateWindow(
szAppName, // See RegisterClass() call.
szTitle, // Text for window title bar.
WS_OVERLAPPEDWINDOW,// Window style.
CW_USEDEFAULT, 0, CW_USEDEFAULT, 0, // Use default positioning
NULL, // Overlapped windows have no parent.
NULL, // Use the window class menu.
hInstance, // This instance owns this window.
NULL // We don't use any data in our WM_CREATE
);
// If window could not be created, return "failure"
if (!hWnd) {
return (FALSE);
}
// Make the window visible; update its client area; and return "success"
ShowWindow(hWnd, nCmdShow); // Show the window
UpdateWindow(hWnd); // Sends WM_PAINT message
return (TRUE); // We succeeded...
}
#if 1
int APIENTRY WinMain(
HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
MSG msg;
HACCEL hAccelTable;
LONG lTime;
// Just for fun, lets seed the random number generator
time(&lTime);
srand(lTime);
if (!hPrevInstance)
{
// Other instances of app running?
if (!InitApplication(hInstance))
{
// Initialize shared things
return (FALSE);
// Exits if unable to initialize
}
}
/* Perform initializations that apply to a specific instance */
if (!InitInstance(hInstance, nCmdShow))
{
return (FALSE);
}
hAccelTable = LoadAccelerators (hInstance, "TEXTFXACCEL");
/* Acquire and dispatch messages until a WM_QUIT message is received. */
while (!bBegin && GetMessage(&msg, // message structure
NULL, // handle of window receiving the message
0, // lowest message to examine
0)) // highest message to examine
{
if (!TranslateAccelerator (msg.hwnd, hAccelTable, &msg))
{
TranslateMessage(&msg);// Translates virtual key codes
DispatchMessage(&msg); // Dispatches message to window
}
}
return (int)(msg.wParam); // Returns the value from PostQuitMessage
UNREFERENCED_PARAMETER(lpCmdLine); // This will prevent 'unused formal parameter' warnings
}
#endif
int WINAPI myDialogProc(
HWND hwnd, // window handle
UINT message, // type of message
WPARAM wParam, // additional information
LPARAM lParam) // additional information
{
static bool bBegin = false;
static DWORD handle = NULL;
char buffer[256];
switch (message)
{
case WM_LBUTTONDOWN:
bBegin = true;
GetGuideLine(hwnd);
//bBegin = false;
return TRUE;
break;
case WM_CLOSE:
EndDialog(hwnd, 0);
return TRUE;
break;
default:
if (bBegin)
{
sprintf(buffer, "message [%d]", message);
if (handle == NULL)
{
handle = GetCurrentThreadId();
sprintf(buffer, "dialog threadid=%d\n", handle);
OutputDebugString(buffer);
}
//MessageBox(hwnd, buffer, "ok", MB_OK);
bBegin = false;
}
break;
}
return FALSE;
}
#if 0
int APIENTRY WinMain(
HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
DialogBox(hInstance, MAKEINTRESOURCE(IDD_DIALOG_TEST), NULL, myDialogProc);
return 0;
}
#endif
////////////////////////////////////////////////////////////////////////////////////////
// This is a simple test for thread priority on windows. In order to maximally reduce noise, I removed all the synchronization code. And the following is the part of result:
......
......
thread[6] with priority THREAD_PRIORITY_TIME_CRITICAL
thread[5] with priority THREAD_PRIORITY_HIGHEST
thread[6] with priority THREAD_PRIORITY_TIME_CRITICAL
thread[5] with priority THREAD_PRIORITY_HIGHEST
thread[6] with priority THREAD_PRIORITY_TIME_CRITICAL
thread[5] with priority THREAD_PRIORITY_HIGHEST
********************************
thread[0] with priority THREAD_PRIORITY_IDLE runs 1173
thread[1] with priority THREAD_PRIORITY_LOWEST runs 1208
thread[2] with priority THREAD_PRIORITY_BELOW_NORMAL runs 1170
thread[3] with priority THREAD_PRIORITY_NORMAL runs 877
thread[4] with priority THREAD_PRIORITY_ABOVE_NORMAL runs 2151
thread[5] with priority THREAD_PRIORITY_HIGHEST runs 27274
thread[6] with priority THREAD_PRIORITY_TIME_CRITICAL runs 31682
NORMAL_PRIORITY_CLASS
//////////////////////////////////////////////////////////////////////////
#include <windows.h>
#include <math.h>
#include <stdio.h>
#define MAX_THREAD 7
HANDLE handles[MAX_THREAD];
CRITICAL_SECTION cs;
//THREAD_PRIORITY_ABOVE_NORMAL Indicates 1 point above normal priority for the priority class.
//THREAD_PRIORITY_BELOW_NORMAL Indicates 1 point below normal priority for the priority class.
//THREAD_PRIORITY_HIGHEST Indicates 2 points above normal priority for the priority class.
//THREAD_PRIORITY_IDLE Indicates a base-priority level of 1 for IDLE_PRIORITY_CLASS, BELOW_NORMAL_PRIORITY_CLASS, NORMAL_PRIORITY_CLASS, ABOVE_NORMAL_PRIORITY_CLASS, or HIGH_PRIORITY_CLASS processes, and a base-priority level of 16 for REALTIME_PRIORITY_CLASS processes.
//THREAD_PRIORITY_LOWEST Indicates 2 points below normal priority for the priority class.
//THREAD_PRIORITY_NORMAL Indicates normal priority for the priority class.
//THREAD_PRIORITY_TIME_CRITICAL Indicates a base-priority level of 15 for IDLE_PRIORITY_CLASS, BELOW_NORMAL_PRIORITY_CLASS, NORMAL_PRIORITY_CLASS, ABOVE_NORMAL_PRIORITY_CLASS, or HIGH_PRIORITY_CLASS processes, and a base-priority level of 31 for REALTIME_PRIORITY_CLASS processes.
int priority[MAX_THREAD] =
{
THREAD_PRIORITY_IDLE,
THREAD_PRIORITY_LOWEST,
THREAD_PRIORITY_BELOW_NORMAL,
THREAD_PRIORITY_NORMAL,
THREAD_PRIORITY_ABOVE_NORMAL,
THREAD_PRIORITY_HIGHEST,
THREAD_PRIORITY_TIME_CRITICAL
};
char* priorityName[MAX_THREAD] =
{
"THREAD_PRIORITY_IDLE",
"THREAD_PRIORITY_LOWEST",
"THREAD_PRIORITY_BELOW_NORMAL",
"THREAD_PRIORITY_NORMAL",
"THREAD_PRIORITY_ABOVE_NORMAL",
"THREAD_PRIORITY_HIGHEST",
"THREAD_PRIORITY_TIME_CRITICAL",
};
char buffer[65535]={0};
int counter = 0;
DWORD myClass = 0;
#if 0
DWORD WINAPI threadRun(void* param)
{
int index = (int)(param);
int level = 0;
if (SetPriorityClass(handles[index], REALTIME_PRIORITY_CLASS))
{
if (SetThreadPriority(handles[index], priority[index]))
{
while (true)
{
level = GetThreadPriority(handles[index]);
EnterCriticalSection(&cs);
for (int i =0 ; i < MAX_THREAD; i ++)
{
if (level == priority[i])
{
printf("thread[%d] priority=%s\n", index, priorityName[i]);
break;
}
}
LeaveCriticalSection(&cs);
}
}
}
return index;
}
#else
DWORD WINAPI threadRun(void* param)
{
int index = (int)(param);
int level = 0;
bool bStop = false;
// you cannot set REALTIME_PRIORITY_CLASS or anything higher than normal
if (SetThreadPriorityBoost(handles[index], TRUE))
{
if (SetThreadPriority(handles[index], priority[index]))
{
while (!bStop)
{
for (int i = 0; i <10000; i ++)
{
double val = log(1024);
val = exp(1024);
val = log10(val);
}
//EnterCriticalSection(&cs);
buffer[counter++] = index;
if (counter >= 65535)
{
bStop = true;
}
//LeaveCriticalSection(&cs);
}
}
}
else
{
printf("what?????????????????????\n");
}
return index;
}
#endif
int main()
{
int i;
HANDLE handle = NULL;
int number[MAX_THREAD]= {0};
InitializeCriticalSection(&cs);
for (i = 0; i< MAX_THREAD; i ++)
{
handles[i] = CreateThread(NULL, 0, threadRun, (void*)i, 0, NULL);
}
for (i = 0; i < MAX_THREAD; i ++)
{
WaitForSingleObject(handles[i], INFINITE);
}
if (counter >=65535)
{
counter = 65535;
}
for (i = 0; i < counter; i ++)
{
number[buffer[i]] ++;
printf("thread[%d] with priority %s\n", buffer[i], priorityName[buffer[i]]);
}
printf("********************************\n\n");
for (i = 0; i < MAX_THREAD; i ++)
{
printf("thread[%d] with priority %s runs %d\n", i, priorityName[i], number[i]);
}
handle = OpenProcess(PROCESS_QUERY_INFORMATION, FALSE, GetCurrentProcessId());
myClass = GetPriorityClass(handle);
switch (myClass)
{
case ABOVE_NORMAL_PRIORITY_CLASS:
printf("ABOVE_NORMAL_PRIORITY_CLASS");
break;
case BELOW_NORMAL_PRIORITY_CLASS:
printf("BELOW_NORMAL_PRIORITY_CLASS");
break;
case HIGH_PRIORITY_CLASS:
printf("HIGH_PRIORITY_CLASS");
break;
case IDLE_PRIORITY_CLASS:
printf("IDLE_PRIORITY_CLASS");
break;
case NORMAL_PRIORITY_CLASS:
printf("NORMAL_PRIORITY_CLASS");
break;
case REALTIME_PRIORITY_CLASS:
printf("REALTIME_PRIORITY_CLASS");
break;
}
return 0;
}
The following is a few lines of simple code for a couple of simple question in string op, namely trim and split:
string StringManager::trim(const string& src, char* delimiter)
{
return src.substr(src.find_first_not_of(delimiter), src.find_last_not_of(delimiter));
}
StringVector StringManager::split(const string& src, char* delimiter)
{
StringVector result;
int start = 0, current = 0;
do
{
bool bFound = false;
if ((start = src.find_first_not_of(delimiter, current))!= string::npos)
{
if ((current = src.find_first_of(delimiter, start))!= string::npos)
{
bFound = true;
result.push_back(src.substr(start, current - start));
start = current;
}
else
{
// this is the last one or when the line is single word
if (start < src.size())
{
result.push_back(src.substr(start, src.size() - start));
}
}
}
}
while (bFound);
return result;
}
![]()
![]()
![]()