我的征尘是星辰大海。。。
The dirt and dust from my pilgrimage forms
oceans of stars...
-------当记忆的篇章变得零碎,当追忆的图片变得模糊,我们只能求助于数字存储的永恒的回忆
作者:黄教授
十月二十七日等待变化等待机会
十月二十八日等待变化等待机会
这不是topcoder的题目仅仅是我自己的练习。
十月二十九日等待变化等待机会
十月三十日等待变化等待机会
这个答案是被否定的因为这个根本是一个概率计算的问题,我却答不上通项公式变成了搜索问题,自然是无法应对大数据量的递归了。可以说这个是一个典型的计算机语言能力无法替代算法的例子。
In most states, gamblers can choose from a wide variety of different lottery games. The rules of a lottery are defined by two integers (choices and blanks) and two boolean variables (sorted and unique). choices represents the highest valid number that you may use on your lottery ticket. (All integers between 1 and choices, inclusive, are valid and can appear on your ticket.) blanks represents the number of spots on your ticket where numbers can be written.
The sorted and unique variables indicate restrictions on the tickets you can create. If sorted is set to true, then the numbers on your ticket must be written in non-descending order. If sorted is set to false, then the numbers may be written in any order. Likewise, if unique is set to true, then each number you write on your ticket must be distinct. If unique is set to false, then repeats are allowed.
Here are some example lottery tickets, where choices = 15 and blanks = 4:
-
{3, 7, 12, 14} -- this ticket is unconditionally valid.
-
{13, 4, 1, 9} -- because the numbers are not in nondescending order, this ticket is valid only if sorted = false.
-
{8, 8, 8, 15} -- because there are repeated numbers, this ticket is valid only if unique = false.
-
{11, 6, 2, 6} -- this ticket is valid only if sorted = false and unique = false.
Given a list of lotteries and their corresponding rules, return a list of lottery names sorted by how easy they are to win. The probability that you will win a lottery is equal to (1 / (number of valid lottery tickets for that game)). The easiest lottery to win should appear at the front of the list. Ties should be broken alphabetically (see example 1).
十一月二日等待变化等待机会
这个问题确实比较难,我花了整整一天来调试。
You work for an electric company, and the power goes out in a rather large apartment complex with a lot of irate tenants. You isolate the problem to a network of sewers underneath the complex with a step-up transformer at every junction in the maze of ducts. Before the power can be restored, every transformer must be checked for proper operation and fixed if necessary. To make things worse, the sewer ducts are arranged as a tree with the root of the tree at the entrance to the network of sewers. This means that in order to get from one transformer to the next, there will be a lot of backtracking through the long and claustrophobic ducts because there are no shortcuts between junctions. Furthermore, it's a Sunday; you only have one available technician on duty to search the sewer network for the bad transformers. Your supervisor wants to know how quickly you can get the power back on; he's so impatient that he wants the power back on the moment the technician okays the last transformer, without even waiting for the technician to exit the sewers first.
You will be given three vector <int>'s: fromJunction, toJunction, and ductLength that represents each sewer duct. Duct i starts at junction (fromJunction[i]) and leads to junction (toJunction[i]). ductlength[i] represents the amount of minutes it takes for the technician to traverse the duct connecting fromJunction[i] and toJunction[i]. Consider the amount of time it takes for your technician to check/repair the transformer to be instantaneous. Your technician will start at junction 0 which is the root of the sewer system. Your goal is to calculate the minimum number of minutes it will take for your technician to check all of the transformers. You will return an int that represents this minimum number of minutes
这个是一个复杂的test,结果是600
RegularSeason
这个不过是500分的题目没有太多的难度,只是理解和改错的问题,对于概率计算的简化让我感到迷惑而已。
A new basketball season will start this autumn, and you want to predict its results. You have been watching the tournaments for ages and following the teams closely, so you can exactly determine the probability that a particular team will win a match vs some other team. Now you want to know, given these probabilities, how many games each of the teams is expected to win in the upcoming tournament.
You will be given a vector <string>, teams. Each element of teams will be formatted as "NAME P1 P2 ... PN", where NAME is the name of the team, and P1, P2, ..., PN are the probabilities that this team will win home games against the 1st, 2nd, ..., Nth teams, respectively (the ith probability for the ith team will always be equal to 0). Ties are not possible due to the rules, so if the ith team has a probability p of beating the jth team in a home game, then the jth team has a probability of (100-p) of beating the ith team when the ith team is at home. Finally, you will be given an int rounds, which gives you the number of rounds in the championship. This means that team A will play 2*rounds games against each other team B (rounds as the visitors and rounds as the home team). You should predict the expected number of games each team will win in the tournament. You should round your prediction to the nearest integer (.5 rounds up).
The return value should be a vector <string>, with each element formatted as "NAME NUMBER", where NAME is the name of the team, and NUMBER is the predicted number of wins. NUMBER should have no extra leading zeroes. The return value should be sorted by NUMBER in decreasing order (so the first element of the result will represent the most probable champion). If several teams have the same rounded number of wins, sort them using predicted number of wins before rounding (again in decreasing order); if a tie still remains, sort the tied teams by NAME in ascending alphabetical order.
十一月八日等待变化等待机会
原本以为是一个很简单的二分法搜索却折腾了好久,看来脑子是锈死了。话说一个有序数组里所有的数字都是两两成对的,除了一个,也就是说数组一定是奇数个数字,并且是排序的,并且有(size-1)/2个unique的数字,这个条件很重要,我一开始没有意识到结果debug了好久。首先就是正确产生这样子的数组,这里我也懒得讲究什么效率了,就是先产生一个排序的不重复的,然后合并(其实应该调用merge,应该比append再sort来的有效率),最后随机抽调一个数字。
二分法的关键是要意识到递归搜索的数组的长度一定是奇数的,我一开始没有意识到。
十一月九日等待变化等待机会
这个是我做的一个小实验来检验sdl_ttf库能否正确显示中文。需要链接sdl2_ttf
十一月十二日等待变化等待机会
对于昨天的遭遇感到有些愤愤不平,可是也无可奈何。这个是一个头条看到的问题,就是所谓的寻找most closest ancester的问题,定义是两个节点的最近的共同祖先,解释起来不如使用实例来看:
这个程序还是花了不少的时间的,首先是怎么定义二叉树,我感觉内存回收是一个头疼的问题,所以决定使用shared_ptr
其次是如何产生二叉树,这个似乎是一个简单的问题,可是开始的时候我没有使用bfs,而是dfs,结果树的形状就不好看了
作为一个小工具你需要把二叉树好看的打印出来,那么这个也是一个分层打印的BFS,为了分层打印我使用了一个TreeValues的容器可以把每一层的数值存在一个map里,它的key是层数,value是一个数值的vector
再次是搜索共同祖先,这个化简为首先搜索一个节点的所有祖先
那么所谓的最近的共同祖先就是按照两个祖先链条找到第一个相同的节点
这个是总的测试程序,因为我现在习惯于把代码都写成一个测试函数里的lambda,所以才会有这么多的lambda递归的定义的麻烦事情。
十一月二十日等待变化等待机会
这个是结果
十一月二十一日等待变化等待机会
我只是想先验证一下这样子操作sub matrix是否方便来搜索sudoku,结果比较失望。
这个是一个简单的问题就是给你一个数组要求你找出所有的数字的和是总数一半的。
运行结果
十一月二十三日等待变化等待机会
我第一次尝试用lower/upper bound但是发现很麻烦,还不如直接遍历,但是,我懒得debug了。
十一月二十四日等待变化等待机会
结果是这样子的,注意这里忽略了空集,所以,可以很容易验证29=512
subset size:511
{ 1}{ 2}{ 3}{ 4}{ 5}{ 6}{ 7}{ 8}{ 9}{ 1 2}{ 1 3}{ 1 4}{ 1 5}{ 1 6}{ 1 7}{ 1 8}{ 1 9}{ 2 3}{ 2 4}{ 2 5}{ 2 6}{ 2 7}{ 2 8}{ 2 9}{ 3 4}{ 3 5}{ 3 6}{ 3 7}{ 3 8}{ 3 9}{ 4 5}{ 4 6}{ 4 7}{ 4 8}{ 4 9}{ 5 6}{ 5 7}{ 5 8}{ 5 9}{ 6 7}{ 6 8}{ 6 9}{ 7 8}{ 7 9}{ 8 9}{ 1 2 3}{ 1 2 4}{ 1 2 5}{ 1 2 6}{ 1 2 7}{ 1 2 8}{ 1 2 9}{ 1 3 4}{ 1 3 5}{ 1 3 6}{ 1 3 7}{ 1 3 8}{ 1 3 9}{ 1 4 5}{ 1 4 6}{ 1 4 7}{ 1 4 8}{ 1 4 9}{ 1 5 6}{ 1 5 7}{ 1 5 8}{ 1 5 9}{ 1 6 7}{ 1 6 8}{ 1 6 9}{ 1 7 8}{ 1 7 9}{ 1 8 9}{ 2 3 4}{ 2 3 5}{ 2 3 6}{ 2 3 7}{ 2 3 8}{ 2 3 9}{ 2 4 5}{ 2 4 6}{ 2 4 7}{ 2 4 8}{ 2 4 9}{ 2 5 6}{ 2 5 7}{ 2 5 8}{ 2 5 9}{ 2 6 7}{ 2 6 8}{ 2 6 9}{ 2 7 8}{ 2 7 9}{ 2 8 9}{ 3 4 5}{ 3 4 6}{ 3 4 7}{ 3 4 8}{ 3 4 9}{ 3 5 6}{ 3 5 7}{ 3 5 8}{ 3 5 9}{ 3 6 7}{ 3 6 8}{ 3 6 9}{ 3 7 8}{ 3 7 9}{ 3 8 9}{ 4 5 6}{ 4 5 7}{ 4 5 8}{ 4 5 9}{ 4 6 7}{ 4 6 8}{ 4 6 9}{ 4 7 8}{ 4 7 9}{ 4 8 9}{ 5 6 7}{ 5 6 8}{ 5 6 9}{ 5 7 8}{ 5 7 9}{ 5 8 9}{ 6 7 8}{ 6 7 9}{ 6 8 9}{ 7 8 9}{ 1 2 3 4}{ 1 2 3 5}{ 1 2 3 6}{ 1 2 3 7}{ 1 2 3 8}{ 1 2 3 9}{ 1 2 4 5}{ 1 2 4 6}{ 1 2 4 7}{ 1 2 4 8}{ 1 2 4 9}{ 1 2 5 6}{ 1 2 5 7}{ 1 2 5 8}{ 1 2 5 9}{ 1 2 6 7}{ 1 2 6 8}{ 1 2 6 9}{ 1 2 7 8}{ 1 2 7 9}{ 1 2 8 9}{ 1 3 4 5}{ 1 3 4 6}{ 1 3 4 7}{ 1 3 4 8}{ 1 3 4 9}{ 1 3 5 6}{ 1 3 5 7}{ 1 3 5 8}{ 1 3 5 9}{ 1 3 6 7}{ 1 3 6 8}{ 1 3 6 9}{ 1 3 7 8}{ 1 3 7 9}{ 1 3 8 9}{ 1 4 5 6}{ 1 4 5 7}{ 1 4 5 8}{ 1 4 5 9}{ 1 4 6 7}{ 1 4 6 8}{ 1 4 6 9}{ 1 4 7 8}{ 1 4 7 9}{ 1 4 8 9}{ 1 5 6 7}{ 1 5 6 8}{ 1 5 6 9}{ 1 5 7 8}{ 1 5 7 9}{ 1 5 8 9}{ 1 6 7 8}{ 1 6 7 9}{ 1 6 8 9}{ 1 7 8 9}{ 2 3 4 5}{ 2 3 4 6}{ 2 3 4 7}{ 2 3 4 8}{ 2 3 4 9}{ 2 3 5 6}{ 2 3 5 7}{ 2 3 5 8}{ 2 3 5 9}{ 2 3 6 7}{ 2 3 6 8}{ 2 3 6 9}{ 2 3 7 8}{ 2 3 7 9}{ 2 3 8 9}{ 2 4 5 6}{ 2 4 5 7}{ 2 4 5 8}{ 2 4 5 9}{ 2 4 6 7}{ 2 4 6 8}{ 2 4 6 9}{ 2 4 7 8}{ 2 4 7 9}{ 2 4 8 9}{ 2 5 6 7}{ 2 5 6 8}{ 2 5 6 9}{ 2 5 7 8}{ 2 5 7 9}{ 2 5 8 9}{ 2 6 7 8}{ 2 6 7 9}{ 2 6 8 9}{ 2 7 8 9}{ 3 4 5 6}{ 3 4 5 7}{ 3 4 5 8}{ 3 4 5 9}{ 3 4 6 7}{ 3 4 6 8}{ 3 4 6 9}{ 3 4 7 8}{ 3 4 7 9}{ 3 4 8 9}{ 3 5 6 7}{ 3 5 6 8}{ 3 5 6 9}{ 3 5 7 8}{ 3 5 7 9}{ 3 5 8 9}{ 3 6 7 8}{ 3 6 7 9}{ 3 6 8 9}{ 3 7 8 9}{ 4 5 6 7}{ 4 5 6 8}{ 4 5 6 9}{ 4 5 7 8}{ 4 5 7 9}{ 4 5 8 9}{ 4 6 7 8}{ 4 6 7 9}{ 4 6 8 9}{ 4 7 8 9}{ 5 6 7 8}{ 5 6 7 9}{ 5 6 8 9}{ 5 7 8 9}{ 6 7 8 9}{ 1 2 3 4 5}{ 1 2 3 4 6}{ 1 2 3 4 7}{ 1 2 3 4 8}{ 1 2 3 4 9}{ 1 2 3 5 6}{ 1 2 3 5 7}{ 1 2 3 5 8}{ 1 2 3 5 9}{ 1 2 3 6 7}{ 1 2 3 6 8}{ 1 2 3 6 9}{ 1 2 3 7 8}{ 1 2 3 7 9}{ 1 2 3 8 9}{ 1 2 4 5 6}{ 1 2 4 5 7}{ 1 2 4 5 8}{ 1 2 4 5 9}{ 1 2 4 6 7}{ 1 2 4 6 8}{ 1 2 4 6 9}{ 1 2 4 7 8}{ 1 2 4 7 9}{ 1 2 4 8 9}{ 1 2 5 6 7}{ 1 2 5 6 8}{ 1 2 5 6 9}{ 1 2 5 7 8}{ 1 2 5 7 9}{ 1 2 5 8 9}{ 1 2 6 7 8}{ 1 2 6 7 9}{ 1 2 6 8 9}{ 1 2 7 8 9}{ 1 3 4 5 6}{ 1 3 4 5 7}{ 1 3 4 5 8}{ 1 3 4 5 9}{ 1 3 4 6 7}{ 1 3 4 6 8}{ 1 3 4 6 9}{ 1 3 4 7 8}{ 1 3 4 7 9}{ 1 3 4 8 9}{ 1 3 5 6 7}{ 1 3 5 6 8}{ 1 3 5 6 9}{ 1 3 5 7 8}{ 1 3 5 7 9}{ 1 3 5 8 9}{ 1 3 6 7 8}{ 1 3 6 7 9}{ 1 3 6 8 9}{ 1 3 7 8 9}{ 1 4 5 6 7}{ 1 4 5 6 8}{ 1 4 5 6 9}{ 1 4 5 7 8}{ 1 4 5 7 9}{ 1 4 5 8 9}{ 1 4 6 7 8}{ 1 4 6 7 9}{ 1 4 6 8 9}{ 1 4 7 8 9}{ 1 5 6 7 8}{ 1 5 6 7 9}{ 1 5 6 8 9}{ 1 5 7 8 9}{ 1 6 7 8 9}{ 2 3 4 5 6}{ 2 3 4 5 7}{ 2 3 4 5 8}{ 2 3 4 5 9}{ 2 3 4 6 7}{ 2 3 4 6 8}{ 2 3 4 6 9}{ 2 3 4 7 8}{ 2 3 4 7 9}{ 2 3 4 8 9}{ 2 3 5 6 7}{ 2 3 5 6 8}{ 2 3 5 6 9}{ 2 3 5 7 8}{ 2 3 5 7 9}{ 2 3 5 8 9}{ 2 3 6 7 8}{ 2 3 6 7 9}{ 2 3 6 8 9}{ 2 3 7 8 9}{ 2 4 5 6 7}{ 2 4 5 6 8}{ 2 4 5 6 9}{ 2 4 5 7 8}{ 2 4 5 7 9}{ 2 4 5 8 9}{ 2 4 6 7 8}{ 2 4 6 7 9}{ 2 4 6 8 9}{ 2 4 7 8 9}{ 2 5 6 7 8}{ 2 5 6 7 9}{ 2 5 6 8 9}{ 2 5 7 8 9}{ 2 6 7 8 9}{ 3 4 5 6 7}{ 3 4 5 6 8}{ 3 4 5 6 9}{ 3 4 5 7 8}{ 3 4 5 7 9}{ 3 4 5 8 9}{ 3 4 6 7 8}{ 3 4 6 7 9}{ 3 4 6 8 9}{ 3 4 7 8 9}{ 3 5 6 7 8}{ 3 5 6 7 9}{ 3 5 6 8 9}{ 3 5 7 8 9}{ 3 6 7 8 9}{ 4 5 6 7 8}{ 4 5 6 7 9}{ 4 5 6 8 9}{ 4 5 7 8 9}{ 4 6 7 8 9}{ 5 6 7 8 9}{ 1 2 3 4 5 6}{ 1 2 3 4 5 7}{ 1 2 3 4 5 8}{ 1 2 3 4 5 9}{ 1 2 3 4 6 7}{ 1 2 3 4 6 8}{ 1 2 3 4 6 9}{ 1 2 3 4 7 8}{ 1 2 3 4 7 9}{ 1 2 3 4 8 9}{ 1 2 3 5 6 7}{ 1 2 3 5 6 8}{ 1 2 3 5 6 9}{ 1 2 3 5 7 8}{ 1 2 3 5 7 9}{ 1 2 3 5 8 9}{ 1 2 3 6 7 8}{ 1 2 3 6 7 9}{ 1 2 3 6 8 9}{ 1 2 3 7 8 9}{ 1 2 4 5 6 7}{ 1 2 4 5 6 8}{ 1 2 4 5 6 9}{ 1 2 4 5 7 8}{ 1 2 4 5 7 9}{ 1 2 4 5 8 9}{ 1 2 4 6 7 8}{ 1 2 4 6 7 9}{ 1 2 4 6 8 9}{ 1 2 4 7 8 9}{ 1 2 5 6 7 8}{ 1 2 5 6 7 9}{ 1 2 5 6 8 9}{ 1 2 5 7 8 9}{ 1 2 6 7 8 9}{ 1 3 4 5 6 7}{ 1 3 4 5 6 8}{ 1 3 4 5 6 9}{ 1 3 4 5 7 8}{ 1 3 4 5 7 9}{ 1 3 4 5 8 9}{ 1 3 4 6 7 8}{ 1 3 4 6 7 9}{ 1 3 4 6 8 9}{ 1 3 4 7 8 9}{ 1 3 5 6 7 8}{ 1 3 5 6 7 9}{ 1 3 5 6 8 9}{ 1 3 5 7 8 9}{ 1 3 6 7 8 9}{ 1 4 5 6 7 8}{ 1 4 5 6 7 9}{ 1 4 5 6 8 9}{ 1 4 5 7 8 9}{ 1 4 6 7 8 9}{ 1 5 6 7 8 9}{ 2 3 4 5 6 7}{ 2 3 4 5 6 8}{ 2 3 4 5 6 9}{ 2 3 4 5 7 8}{ 2 3 4 5 7 9}{ 2 3 4 5 8 9}{ 2 3 4 6 7 8}{ 2 3 4 6 7 9}{ 2 3 4 6 8 9}{ 2 3 4 7 8 9}{ 2 3 5 6 7 8}{ 2 3 5 6 7 9}{ 2 3 5 6 8 9}{ 2 3 5 7 8 9}{ 2 3 6 7 8 9}{ 2 4 5 6 7 8}{ 2 4 5 6 7 9}{ 2 4 5 6 8 9}{ 2 4 5 7 8 9}{ 2 4 6 7 8 9}{ 2 5 6 7 8 9}{ 3 4 5 6 7 8}{ 3 4 5 6 7 9}{ 3 4 5 6 8 9}{ 3 4 5 7 8 9}{ 3 4 6 7 8 9}{ 3 5 6 7 8 9}{ 4 5 6 7 8 9}{ 1 2 3 4 5 6 7}{ 1 2 3 4 5 6 8}{ 1 2 3 4 5 6 9}{ 1 2 3 4 5 7 8}{ 1 2 3 4 5 7 9}{ 1 2 3 4 5 8 9}{ 1 2 3 4 6 7 8}{ 1 2 3 4 6 7 9}{ 1 2 3 4 6 8 9}{ 1 2 3 4 7 8 9}{ 1 2 3 5 6 7 8}{ 1 2 3 5 6 7 9}{ 1 2 3 5 6 8 9}{ 1 2 3 5 7 8 9}{ 1 2 3 6 7 8 9}{ 1 2 4 5 6 7 8}{ 1 2 4 5 6 7 9}{ 1 2 4 5 6 8 9}{ 1 2 4 5 7 8 9}{ 1 2 4 6 7 8 9}{ 1 2 5 6 7 8 9}{ 1 3 4 5 6 7 8}{ 1 3 4 5 6 7 9}{ 1 3 4 5 6 8 9}{ 1 3 4 5 7 8 9}{ 1 3 4 6 7 8 9}{ 1 3 5 6 7 8 9}{ 1 4 5 6 7 8 9}{ 2 3 4 5 6 7 8}{ 2 3 4 5 6 7 9}{ 2 3 4 5 6 8 9}{ 2 3 4 5 7 8 9}{ 2 3 4 6 7 8 9}{ 2 3 5 6 7 8 9}{ 2 4 5 6 7 8 9}{ 3 4 5 6 7 8 9}{ 1 2 3 4 5 6 7 8}{ 1 2 3 4 5 6 7 9}{ 1 2 3 4 5 6 8 9}{ 1 2 3 4 5 7 8 9}{ 1 2 3 4 6 7 8 9}{ 1 2 3 5 6 7 8 9}{ 1 2 4 5 6 7 8 9}{ 1 3 4 5 6 7 8 9}{ 2 3 4 5 6 7 8 9}{ 1 2 3 4 5 6 7 8 9}
在这个基础上我们来实现固定大小的子集的产生
这个纯粹是好奇的实验,假如sudoku的9个数字里有重复的数字,我们能否依靠加总他们的和来发现是什么数字重复了几次呢?这个纯粹是不可能,用脚趾头想也知道无意义,我却想看看也许有什么特殊的分布可以利用?实际上完全没有
从这个结果来看完全没有办法
十一月二十五日等待变化等待机会
给定一个数列,寻找任何一条最长的钟摆
其实难度在于寻找所有的最长的钟摆,这个有些麻烦在于stl里没有tree,需要自己定义就很麻烦,因此我只能返回所有的中间过程然后再删除保留最长的。
这个是题目里的例子1,17,5,10,13,15,10,5,16,8,的结果
对于最大连续子数组的问题比较简单在于连续,所以比上面的问题来的容易些。有人对于子数组的起始去做优化寻找正数作为开始点,可是对于数组全部为负数这个“贪心”算法不成立。
这个是我的改进以便返回最大的子数组。
十一月三十日等待变化等待机会
这是一个不难的小题目,可是我却花了好长时间,就是bit的操作很久不用生疏了。
十二月二日等待变化等待机会
这个关于“墙和灯光”的著名的问题,我似乎以前听说过,真的做起来花了很多时间,主要是我想找到一个好的处理二维数组的方式,现在看起来还是valarray有一些优势。
这个是测试的例子
这个是一个cross-word的小游戏程序
Given an m x n board of characters and a list of strings words, return all words on the board.
Each word must be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once in a word.
Example 1:
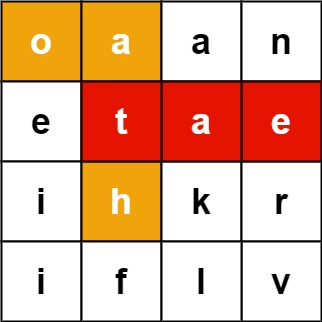
Input: board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
Output: ["eat","oath"]
十二月三日等待变化等待机会
这个题目对我的帮助很大就在于我看了得分最高的大侠的方案大为叹服,不论内存消耗还是代码简洁清晰,算法的洗练都是当之无愧的高高手的杰作。首先我意识到了我长久依赖的一个毛病,我一直想改掉但是总是不成功,就是stack unwinding的问题,在搜索中维持一个context是非常的昂贵的,如果能够利用递归搜索中的栈的自然的“递归”本质,那么就可以用维护一个全局的状态随着递归深入更新状态与返回回归原来状态,这样子就不用给每一个搜索分支分配一份内存的状态。具体来说就是寻路的路径可以在递归开始的时候更新,在递归返回的时候恢复,这个是浅显的道理,之所以我以前一直很害怕这个简单的逻辑是担心走回头路的打转转,那么只要你能够保证你的选择没有回到上一级的出发地的机制,这个就是没有问题的。比如大侠的做法是连路径的一个记录都省却了,而是直接利用参数的“grid”既作为寻路的地图,也作为寻路的路径的辅助,这个当然是很巧妙,但是我不是特别的喜欢,因为作为极限编程固然节省了内存但是从维护的角度来看不是很好的做法。我的态度是欣赏但是不愿意模仿。 我的代码不算优秀但是我自己看得懂,而且有一些中规中局的“大众”风格。
这个题目是难度小一些的反而我花了更多的时间,因为看上去简单,实际上它的要求是不一样的,我使用深度优先的路径搜索是一个overkill,题目不允许因为不必要,有时间限制,所以,反而不是那么的简单,我决定使用广度搜索,因为照例说递归是比循环来的慢,所以,我希望使用deque来加快,看起来大多数人比这个来的快。
A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below).
The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked 'Finish' in the diagram below).
Now consider if some obstacles are added to the grids. How many unique paths would there be?
An obstacle and space is marked as 1 and 0 respectively in the grid.
我的解答我认为是中规中居的平均,但是看起来比平均还茶很多,需要看看别人的解答差距在哪里。
这个问题我一开始使用组合来做,可是速度太慢了。
贪心算法是不对的!
答案是50487,而我的结果是50418,主要的原因就是怎么选择最后要剩下哪个,我的简单的贪心算法不成功。
参考了大侠的算法,我自己改正我的错误,关键就是说无非最后要去掉至多两个数,这个就是“鸽子原理”,就是说如果需要去掉超过两个数,明显就是错的,因为剩下的三个数里面一定有和是三的倍数,所以是错的。明确的这一点就明白无非是找最后要裁掉谁的问题。我的想法是完全没有道理的,就是总数的余数如果是在1,那么当然我们不可能杜撰出余数是2的组合更小,这个似乎是很直观的,但是我很难证明给自己看。我忽然想明白了,我的想法也没有错只不过中间想差了。如果要裁掉的是余数余一,那么当然是一个余一或者两个余二。否则你硬要裁减出一个余二的话,你是做不到的,因为你拿出三个余二的数来与这个余一的反复组合也是徒劳的。因为还是两个余二。原则还是“鸽子原理”不可能超过三两个数。
十二月四日等待变化等待机会
难道这个题目很难吗?为什么我做了这么长时间?最后还是使用比较复杂的容器来存放长度,本来我还打算使用递归来搜索所有的increasing sequence,但是题目仅仅是要求最大长度,所以反而我不知道怎么解决才好。
十二月五日等待变化等待机会
怎么为link list排序呢?
十二月七日等待变化等待机会
这个题目很有意义在于让我练习了一下std::reference_wrapper
Given an array arr. You can choose a set of integers and remove all the occurrences of these integers in the array.
Return the minimum size of the set so that at least half of the integers of the array are removed.
这个是参考这个例子来做试验检验reduce相对于inclusive_scan的加速
运行结果是让人迷惑的,之前似乎有三倍左右的加速,现在看不到了
十二月十五日等待变化等待机会
这个是原来的题目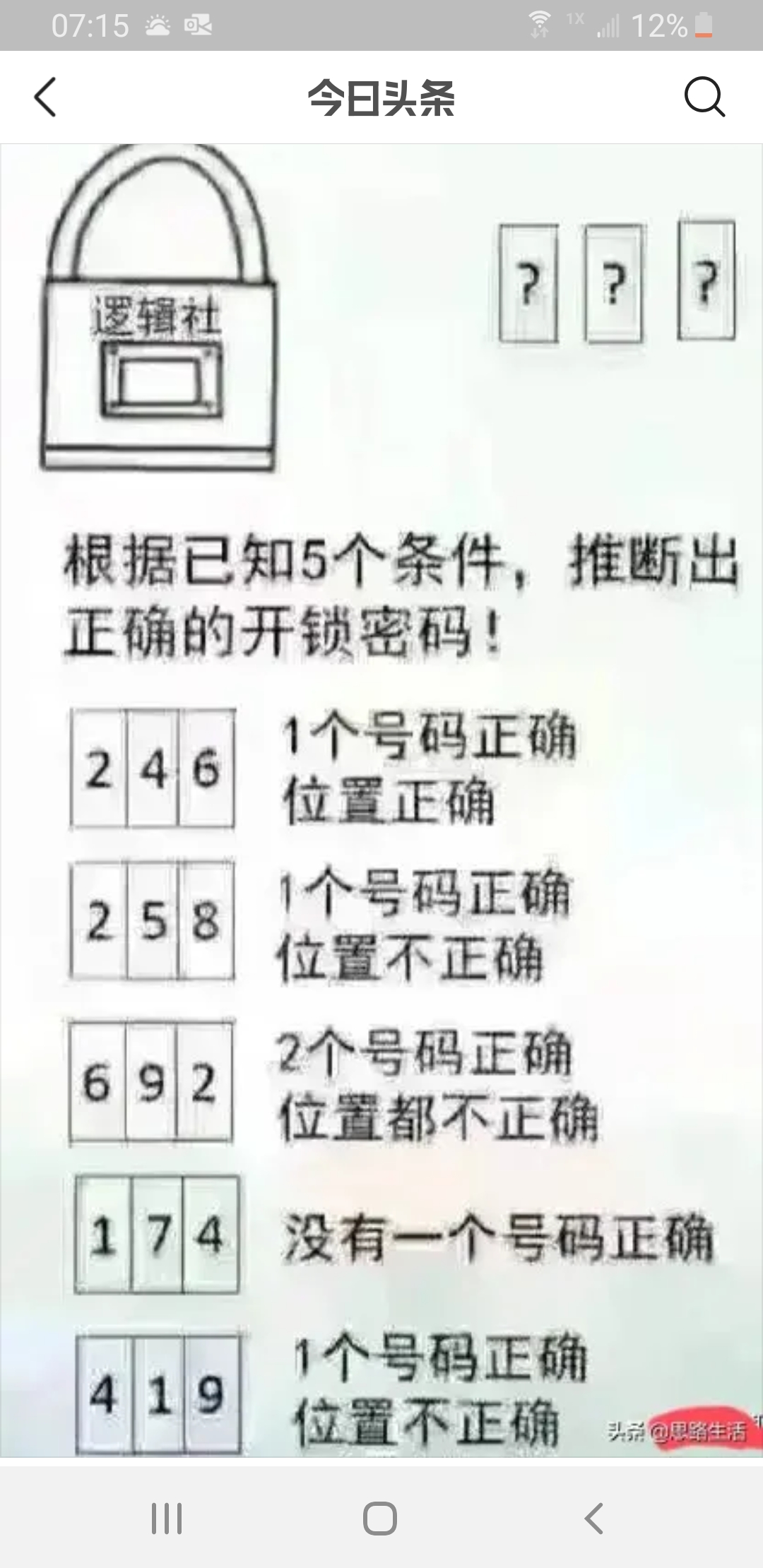 那么我的程序就是写一系列的约束条件。
那么我的程序就是写一系列的约束条件。
十二月十六日等待变化等待机会
十二月二十日等待变化等待机会
结果如下
十二月二十八日等待变化等待机会
这个不过是小小的验证一下++操作符不是一个atomic的操作,我以前对于这一点的认识不是很清楚认为这个是一个指令,其实牵涉到内存读写都不是,因为寄存器也许是一个指令可是内存load/store是十几甚至几十个指令周期啊。
结果如下
counter should be 100000000 and counter=14070258
