
Frank Denneman is a Chief Technologist in the Office of CTO of the Cloud Platform BU at VMware. He is the author of multiple books including “vSphere 6.5 Host Technical Deep Dive” and the “vSphere Clustering Technical Deep Dive” series.
AMD’s current flagship model is the 12-core 6100 Opteron code name Magny-Cours. Its architecture is quite interesting to say at least. Instead of developing one CPU with 12 cores, the Magny Cours is actually two 6 core “Bulldozer” CPUs combined in to one package. This means that an AMD 6100 processor is actually seen by ESX as this:
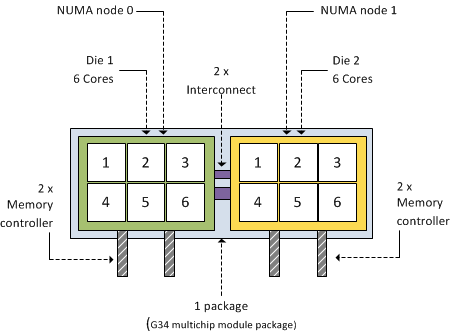
As mentioned before, each 6100 Opteron package contains 2 dies. Each CPU
(die) within the package contains 6 cores and has its own local
memory controllers. Even though many server architectures group DIMM
modules per socket, due to the use of the local memory controllers
each CPU will connect to a separate memory area, therefore creating
different memory latencies within the package.
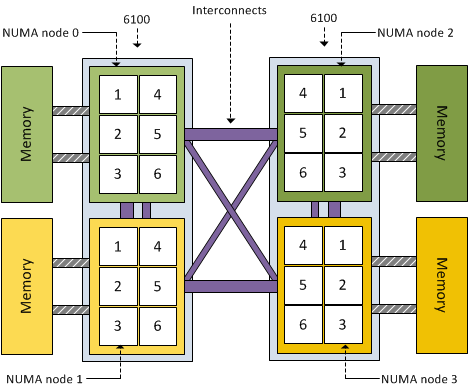
Because different memory latency exists within the package, each CPU is seen as a separate NUMA node. That means a dual AMD 6100 processor system is treated by ESX as a four-NUMA node system:
Impact on virtual machines
Because the AMD 6100 is actually two 6-core NUMA nodes, creating a virtual machine configured with
more than 6 vCPUs will result in a wide-VM. In a wide-VM all vCPUs
are split across a multitude of NUMA clients. At the virtual
machine’s power on, the CPU scheduler determines the number of NUMA
clients that needs to be created so each client can reside within a
NUMA node. Each NUMA client contains as many vCPUs possible that fit
inside a NUMA node.That means that an 8 vCPU virtual machine is split
into two NUMA clients, the first NUMA client contains 6 vCPUs and the
second NUMA client contains 2 vCPUs. The article “ESX
4.1 NUMA scheduling” contains more info about wide-VMs.
Distribution
of NUMA clients across the architecture
ESX 4.1 uses a round-robin algorithm during initial placement and will often pick
the nodes within the same package. However it is not guaranteed and
during load-balancing the VMkernel could migrate a NUMA client to
another NUMA node external to the current package.
Although the new AMD architecture in a two-processor system ensures a 1-hop environment due to the existing interconnects, the latency from 1 CPU to another CPU memory within the same package is less than the latency to memory attached to a CPU outside the package. If more than 2 processors are used a 2-hop system is created, creating different inter-node latencies due to the varying distance between the processors in the system.
Magny-Cours
and virtual machine vCPU count
The new architecture should perform well, at least better that the older Opteron series
due to the increased bandwidth of the HyperTransport interconnect and
the availability of multiple interconnects to reduce the amounts of
hops between NUMA nodes. By using Wide-VM structures, ESX reduces the
amount of hops and tries to keep as much memory local. But –if
possible- the administrator should try to keep the virtual machine
CPU count beneath the maximum CPU count per NUMA node. In the 6100
Magny-Cours case that should be maximum 6 vCPUs per virtual machine